As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Usando dicas de junção em Spark SQL
With Spark 3.0, você pode especificar o tipo de algoritmo de junção que você deseja Spark para usar em tempo de execução. A estratégia de junção sugere,BROADCAST,MERGE, SHUFFLE_HASHSHUFFLE_REPLICATE_NL, e instrui Spark usar a estratégia sugerida em cada relação especificada ao juntá-las a outra relação. Esta seção discute as dicas da estratégia de junção em detalhes.
TRANSMISSÃO
Em uma junção de hash de transmissão, um dos conjuntos de dados é significativamente menor do que o outro. Como o conjunto de dados menor pode caber na memória, ele é transmitido para todos os executores no cluster. Depois que os dados são transmitidos, uma junção de hash padrão é executada. Uma junção de Broadcast Hash acontece em duas etapas:
-
Transmissão — O conjunto de dados menor é transmitido para todos os executores dentro do cluster.
-
Junção de hash — O conjunto de dados menor é dividido em hash em todos os executores e, em seguida, unido ao conjunto de dados maior.
Não há sort nenhuma merge operação. Ao unir tabelas de fatos grandes com tabelas de menor dimensão usadas para realizar uma junção de esquema em estrela, o Broadcast Hash é o algoritmo de junção mais rápido. O exemplo a seguir demonstra como uma junção de hash de transmissão funciona. O lado da junção com a dica é transmitido, independentemente do limite de tamanho especificado na propriedade. spark.sql.autoBroadcastJoinThreshold Se os dois lados da junção tiverem dicas de transmissão, aquele com o tamanho menor (com base nas estatísticas) será transmitido. O valor padrão da spark.sql.autoBroadcastJoinThreshold propriedade é 10 MB. Isso configura o tamanho máximo, em bytes, de uma tabela que é transmitida para todos os nós de trabalho ao realizar uma junção.
Os exemplos a seguir fornecem a consulta, o EXPLAIN plano físico e o tempo gasto para que a consulta seja executada. A consulta requer menos tempo de processamento se você usar a BROADCASTJOIN dica para forçar uma junção de transmissão, conforme mostrado no segundo EXPLAIN plano de exemplo.
SQL Query : select table1.id,table1.col,table2.id,table2.int_col from table1 join table2 on table1.id = table2.id == Physical Plan == AdaptiveSparkPlan isFinalPlan=false +- SortMergeJoin [id#80L], [id#95L], Inner :- Sort [id#80L ASC NULLS FIRST], false, 0 : +- Exchange hashpartitioning(id#80L, 36), ENSURE_REQUIREMENTS, [id=#725] : +- Filter isnotnull(id#80L) : +- Scan ExistingRDD[id#80L,col#81] +- Sort [id#95L ASC NULLS FIRST], false, 0 +- Exchange hashpartitioning(id#95L, 36), ENSURE_REQUIREMENTS, [id=#726] +- Filter isnotnull(id#95L) +- Scan ExistingRDD[id#95L,int_col#96L] Number of records processed: 799541 Querytime : 21.87715196 seconds
SQL Query : select /*+ BROADCASTJOIN(table1)*/ table1.id,table1.col,table2.id,table2.int_col from table1 join table2 on table1.id = table2.id Physical Plan == AdaptiveSparkPlan isFinalPlan=false\n +- BroadcastHashJoin [id#271L], [id#286L], Inner, BuildLeft, false :- BroadcastExchange HashedRelationBroadcastMode(List(input[0, bigint, false]),false), [id=#955] : +- Filter isnotnull(id#271L) : +- Scan ExistingRDD[id#271L,col#272] +- Filter isnotnull(id#286L) +- Scan ExistingRDD[id#286L,int_col#287L] Number of records processed: 799541 Querytime : 15.35717314 seconds
MERGE
A junção Shuffle Sort Merge é preferida quando os dois conjuntos de dados são grandes e não cabem na memória. Como o nome indica, essa junção envolve as três fases a seguir:
-
Fase aleatória — Ambos os conjuntos de dados na consulta de junção são misturados.
-
Fase de classificação — Os registros são classificados pela chave de junção em ambos os lados.
-
Fase de mesclagem — Ambos os lados da condição de junção são iterados, com base na chave de junção.
A imagem a seguir mostra uma visualização do Directed Acyclic Graph (DAG) de uma junção Shuffle Sort Merge. Ambas as tabelas são lidas nas duas primeiras etapas. No próximo estágio (estágio 17), eles são embaralhados, classificados e depois mesclados no final.
Observação: algumas das etapas nesta imagem são mostradas como ignoradas porque essas etapas foram concluídas nas etapas anteriores. Esses dados foram armazenados em cache ou persistidos para uso nesses estágios. |
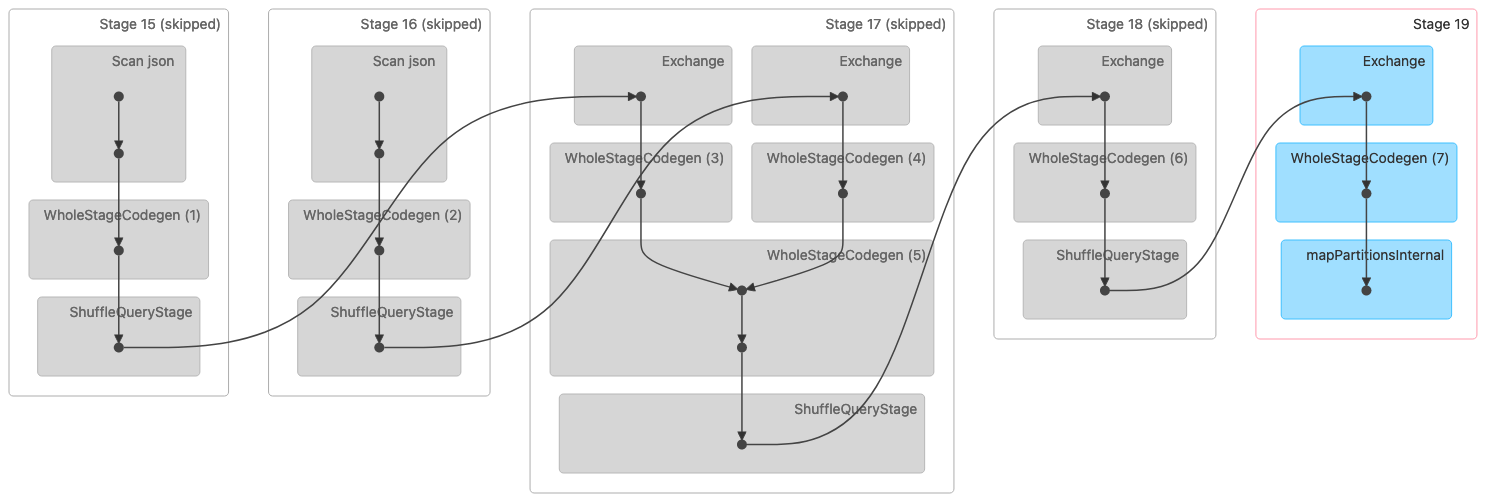
A seguir está um plano físico que indica uma junção Sort Merge.
== Physical Plan == AdaptiveSparkPlan isFinalPlan=false +- SortMergeJoin [id#320L], [id#335L], Inner :- Sort [id#320L ASC NULLS FIRST], false, 0 : +- Exchange hashpartitioning(id#320L, 36), ENSURE_REQUIREMENTS, [id=#1018] : +- Filter isnotnull(id#320L) : +- Scan ExistingRDD[id#320L,col#321] +- Sort [id#335L ASC NULLS FIRST], false, 0 +- Exchange hashpartitioning(id#335L, 36), ENSURE_REQUIREMENTS, [id=#1019] +- Filter isnotnull(id#335L) +- Scan ExistingRDD[id#335L,int_col#336L]
SHUFFLE_HASH
A junção Shuffle Hash, como o nome indica, funciona misturando os dois conjuntos de dados. As mesmas teclas dos dois lados acabam na mesma partição ou tarefa. Depois que os dados são misturados, o menor dos dois conjuntos de dados é dividido em compartimentos e, em seguida, uma junção de hash é executada dentro da partição. Uma junção Shuffle Hash é diferente de uma junção Broadcast Hash porque o conjunto de dados inteiro não é transmitido. Uma junção Shuffle Hash é dividida em duas fases:
-
Fase aleatória — Ambos os conjuntos de dados são misturados.
-
Fase de junção de hash — O lado menor dos dados é dividido em hash, agrupado em intervalos e, em seguida, unido por hash ao lado maior em todas as partições.
A classificação não é necessária com as junções Shuffle Hash dentro das partições. A imagem a seguir mostra as fases da junção Shuffle Hash. Os dados são lidos inicialmente, depois são misturados e, em seguida, um hash é criado e usado para a junção.
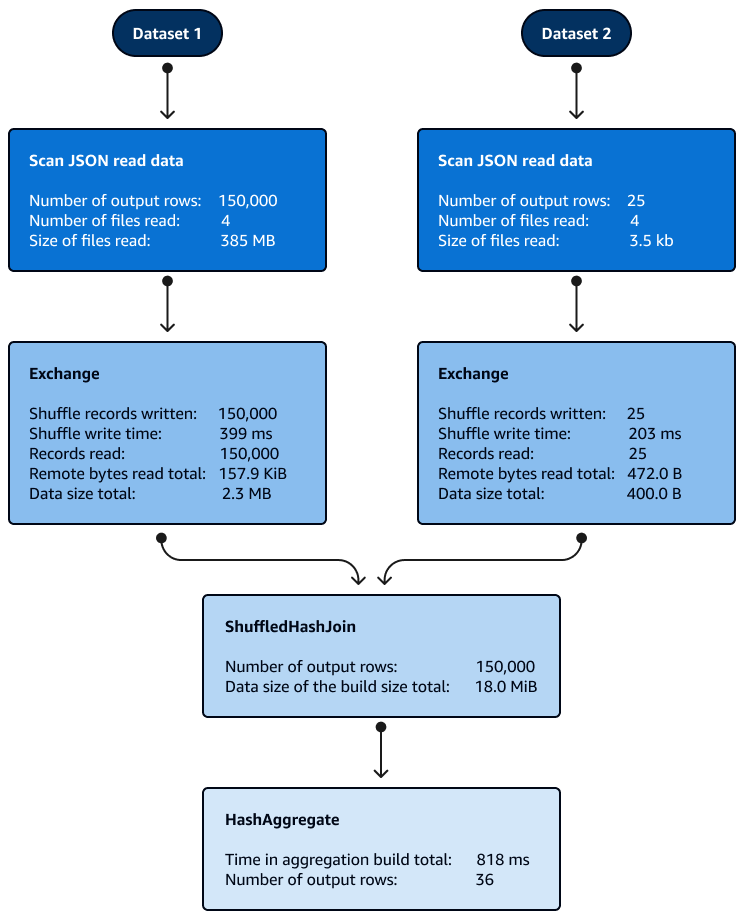
Por padrão, o otimizador escolhe a junção Shuffle Hash quando a junção Broadcast Hash não pode ser usada. Com base no tamanho do limite de junção do Broadcast Hash (spark.sql.autoBroadcastJoinThreshold) e no número de partições aleatórias (spark.sql.shuffle.partitions) escolhidas, ele usa a junção Shuffle Hash quando a única partição do SQL lógico é pequena o suficiente para criar uma tabela de hash local.
SHUFFLE_REPLICATE_NL
A junção Shuffle-and-Replicate Nested Loop, também conhecida como junção de produto cartesiana, funciona de forma muito semelhante a uma junção Broadcast Hash, exceto que o conjunto de dados não é transmitido.
Nesse algoritmo de junção, o shuffle não se refere a um verdadeiro shuffle porque os registros com as mesmas chaves não são enviados para a mesma partição. Em vez disso, toda a partição dos dois conjuntos de dados é copiada pela rede. Quando as partições dos conjuntos de dados estão disponíveis, uma junção de loop aninhado é executada. Se houver X número de registros no primeiro conjunto de dados e Y número de registros no segundo conjunto de dados em cada partição, cada registro no segundo conjunto de dados será associado a cada registro no primeiro conjunto de dados. Isso continua em um loop de X × Y vezes em cada partição.
