As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Custos de inatividade e o surgimento da engenharia do caos
A Consultoria de Inteligência em Tecnologia da Informação (ITIC)
Embora o tempo de inatividade seja comumente associado a sistemas on-line geradores de receita, o impacto negativo vai muito além disso. Todas as grandes empresas e organizações, independentemente de seu modelo de receita principal, dependem criticamente da disponibilidade de seus sistemas internos, como RH e folha de pagamento.
O tempo de inatividade que afeta esses principais serviços internos pode inibir a capacidade de funcionamento de uma empresa, levando a interrupções operacionais substanciais e repercussões financeiras. Os problemas resultantes podem incluir o seguinte:
-
Atrasos no pagamento de funcionários e fornecedores
-
Incapacidade de processar pedidos ou transações de clientes
-
Violações de dados confidenciais permitidas por sistemas de segurança comprometidos
-
Perda de produtividade e oportunidades de receita
-
Penalidades regulatórias por não conformidade
-
Danos à reputação da marca
A engenharia do caos introduz intencionalmente interrupções controladas. Usar a engenharia do caos para entender ou verificar a resposta do sistema às deficiências tornou-se uma prática crítica para melhorar a resiliência do sistema. A engenharia do caos permite que sua organização descubra problemas de forma proativa, valide mecanismos de resiliência e, por fim, reduza o risco de tempo de inatividade não planejado e os custos associados. Os benefícios da engenharia do caos incluem o seguinte:
-
Expondo a dívida técnica
-
Exercício dos músculos operacionais
-
Construindo confiança nos sistemas
-
Identificação de pontos de falha
-
Melhorando o monitoramento e a observabilidade
-
Apoiando o aprendizado baseado em experimentos
-
Oferecendo maior resiliência para reduzir o tempo de inatividade
À medida que os sistemas se tornam mais complexos e as expectativas dos clientes aumentam, a importância da engenharia do caos aumenta. A Gartner recomenda a engenharia do caos
Os desafios da adoção da engenharia do caos
Embora a engenharia do caos seja uma prática cada vez mais importante para melhorar a resiliência do sistema, sua adoção pode enfrentar os seguintes obstáculos:
-
Percepções errôneas sobre risco ‒ Uma percepção errônea comum é que a engenharia do caos é conduzida somente em ambientes de produção, o que gera preocupações com riscos excessivos. Essa percepção decorre da falta de compreensão sobre a natureza sistemática e controlada das práticas de engenharia do caos. Conforme observado no AWS Well-Architected Framework, conduza primeiro a simulação de falhas em um ambiente que não seja de produção.
-
Valor comercial a longo prazo ‒ Os benefícios da engenharia do caos se acumulam gradualmente, dificultando a quantificação do valor comercial e a justificação do investimento inicial. O ROI mais lento dificulta que as organizações priorizem e continuem com a engenharia do caos.
-
Lacunas de habilidades e conhecimentos ‒ A engenharia do caos exige um conjunto exclusivo de habilidades e conhecimentos que podem não estar prontamente disponíveis em sua organização. Construir ou adquirir essa experiência pode ser uma barreira significativa, especialmente para organizações que são novas na prática e aquelas com recursos limitados.
O restante deste documento estratégico se concentrará principalmente no segundo desafio, que é demonstrar o valor comercial da engenharia do caos.
Os efeitos acumulados da engenharia do caos
Diferentemente dos projetos de tecnologia tradicionais com datas de início e término bem definidas, a engenharia do caos é uma prática contínua de aprendizado contínuo e melhorias contínuas na resiliência do sistema. Os benefícios da engenharia do caos aumentam com o tempo.
À medida que os sistemas evoluem e se tornam mais complexos, surgem novos modos de falha. São necessários mais experimentos de caos para identificar possíveis problemas. A solução de um problema pode levar meses, especialmente em grandes empresas com sistemas e processos complexos ou quando as falhas são de propriedade de provedores de serviços externos.
A mudança cultural para encarar o fracasso como uma oportunidade de aprendizado e aprimoramento cresce com o passar dos anos e se torna arraigada na organização. Os investimentos na automação de experimentos de engenharia do caos e no desenvolvimento de ferramentas de apoio continuam a simplificar e aprimorar a prática da engenharia do caos. Construir esse conhecimento institucional e entender a resiliência do sistema é um processo gradual que se acumula ao longo do tempo. O conhecimento, os processos e as ferramentas desenvolvidos por meio da engenharia do caos aumentam de valor à medida que a prática amadurece junto com os sistemas em constante evolução.
O diagrama a seguir mostra como o valor aumenta com o tempo à medida que a adoção do caos progride nos seguintes estágios:
-
Adoção inicial
-
Aprendendo
-
Análise do modo de falha
-
Experimentos únicos
-
Periódico GameDays
-
Experimentação contínua
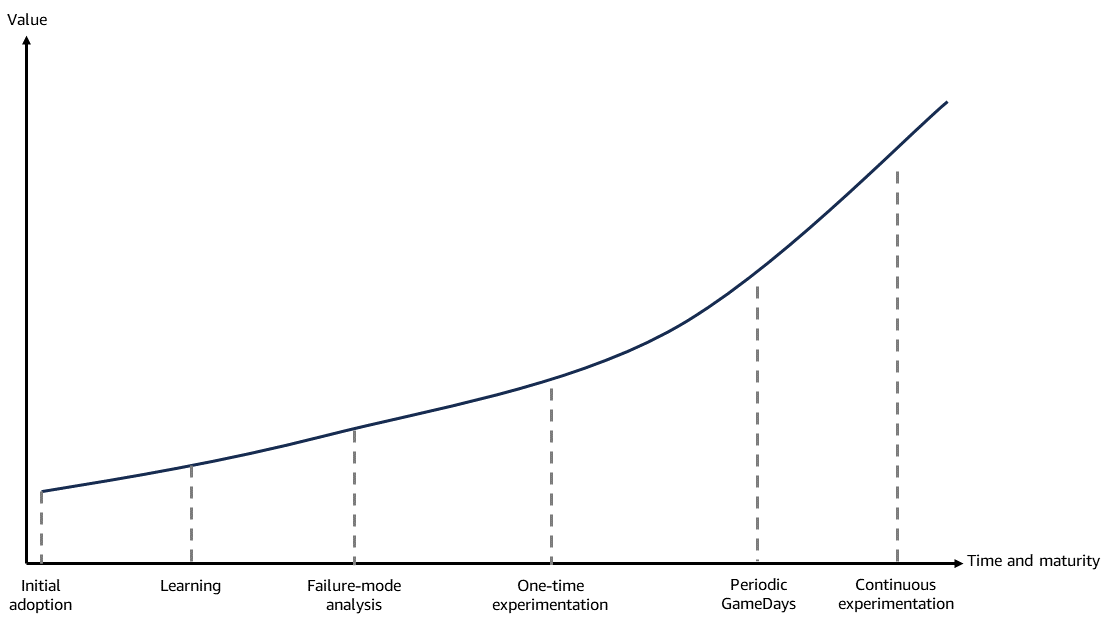
Conforme mostrado no diagrama, os benefícios da engenharia do caos geralmente começam antes que qualquer falha seja injetada no sistema. O processo de planejar e projetar experimentos de caos em si fornece valor imediato. Identificar possíveis cenários de falha, pontos únicos de falha e áreas de incerteza no sistema leva a melhorias.
Por exemplo, escrever cenários de falha e discutir os possíveis efeitos em cascata, um processo chamado modo de falha e análise de efeitos (FMEA), ajuda a descobrir fraquezas ou lacunas óbvias que podem ter sido negligenciadas. Sua organização pode resolver esses problemas de forma proativa, mesmo antes de sujeitar o sistema a qualquer interrupção intencional. Para obter mais informações, consulte a estrutura de análise de resiliência.
Além disso, o maior foco na observabilidade e monitoramento do sistema, que geralmente acompanha as iniciativas de engenharia do caos, começa a gerar benefícios imediatamente. Melhorar a visibilidade do comportamento do sistema e dos modos de falha ajuda a equipe a entender melhor as condições operacionais normais do sistema. Uma maior visibilidade também ajuda a equipe a entender como as condições operacionais se degradam, se adaptam e falham quando levadas ao limite.
Tanto o experimento único quanto o GameDay modo periódico são abordagens mais manuais em comparação com o modo de experimentação contínua. Eles exigem um processo mais prático e exploratório, no qual os engenheiros moldam e refinam ativamente as hipóteses por meio de suas observações e experimentos.
O modo de experimentação contínua é, por outro lado, mais automatizado por natureza. Esse modo se concentra na execução de hipóteses aprovadas e validadas de forma controlada e iterativa. Ele usa automação e integração no processo de desenvolvimento por meio de um pipeline de caos dedicado
