As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Exemplo de implementação de uma estratégia moderna de dados de saúde
AWS fornece arquiteturas de referência que as organizações de saúde podem usar para entender e criar plataformas de dados que ofereçam suporte a uma abordagem ágil aos dados. A arquitetura de referência a seguir ilustra uma arquitetura de malha de dados
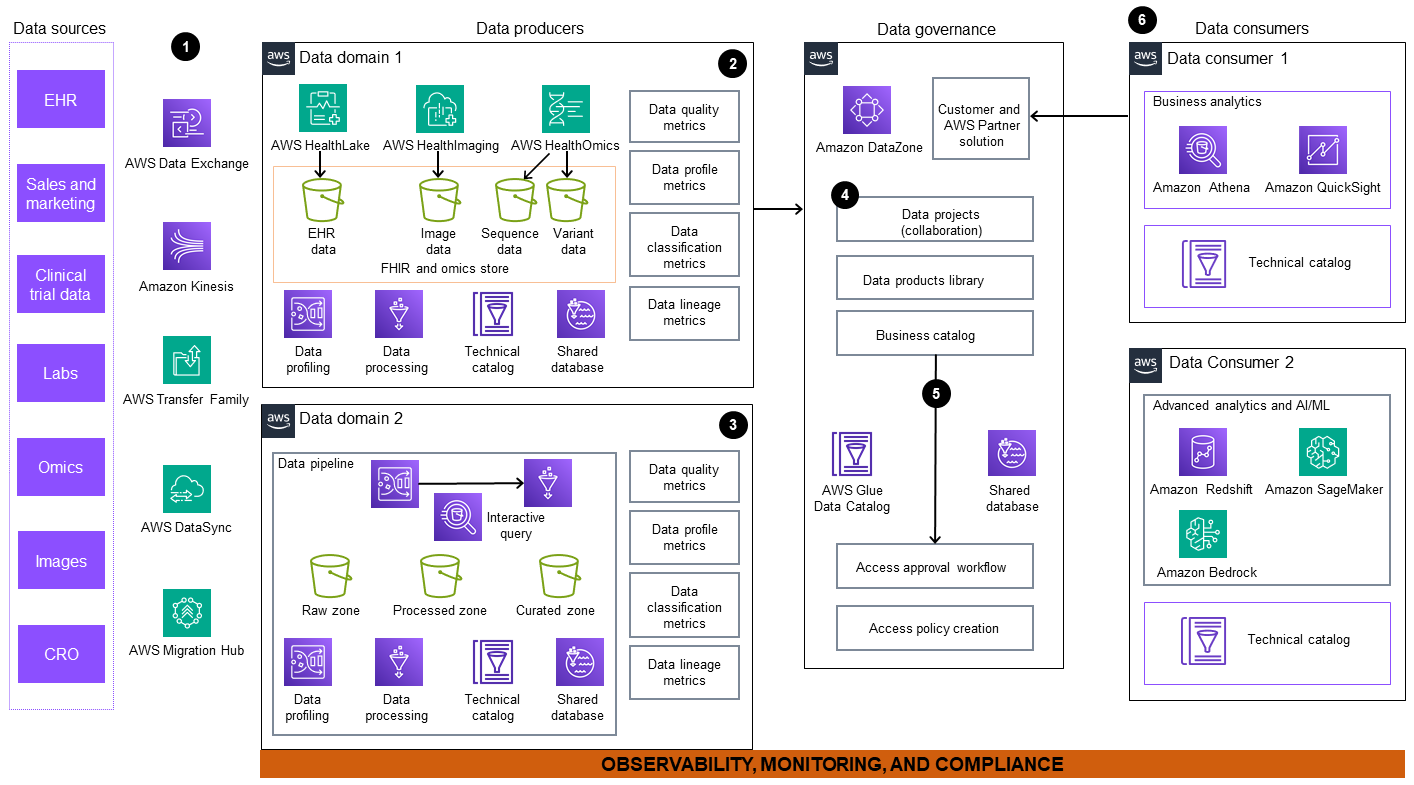
O diagrama de arquitetura inclui os seguintes componentes:
-
Os dados são ingeridos de fontes de dados externas e internas. Essas fontes incluem, mas não estão limitadas a, sistemas de Registro Eletrônico de Saúde (EHR), laboratórios, instalações de sequenciamento e centros de imagem. AWS oferece um conjunto de serviços como Amazon Kinesis AWS Data Exchange
,,,, AWS Transfer FamilyAWS DataSyncAWS Migration HubAWS HealthLake , e AWS Glue (ETL). Você pode usar esses serviços para ajudar a migrar seu conjunto de dados interno e assinar conjuntos de dados internos e externos. -
O domínio de dados 1 compreende um fluxo de trabalho abrangente para o processamento de dados multimodais orientados ao paciente, incluindo dados clínicos, ômicos e de imagem. Os dados clínicos do EHR são ingeridos e armazenados em um armazenamento de HealthLake dados, um serviço gerenciado específico para dados clínicos. AWS HealthOmics
, um serviço desenvolvido especificamente para dados ômicos, gerencia o armazenamento de sequências e variantes e o fluxo de trabalho. Os dados de imagem são ingeridos e armazenados em AWS HealthImaging . Esses dados são então transformados em produtos prontos para consumo e publicados em um mercado de dados corporativo para ampla acessibilidade e uso. -
No domínio de dados 2, Amazon Kinesis, AWS Glue, e AWS Data Exchange ingere dados brutos em um pipeline de dados. As fontes dos dados podem incluir registros públicos, monitoramento remoto de pacientes e programas de Planejamento de Recursos Empresariais (ERP). O pipeline carrega os dados brutos nos buckets do Amazon Simple Storage Service (Amazon S3
). Esses dados são limpos, selecionados, transformados e armazenados para publicação como um produto de dados. O Amazon Athena oferece um mecanismo de consulta interativo que os produtores de dados podem usar para transformar dados usando SQL. AWS Glue DataBrew fornece recursos visuais de transformação, normalização e criação de perfil de dados. -
A Amazon DataZone
gerencia a publicação de metadados, projetos de dados colaborativos e a biblioteca de produtos de dados no catálogo central de negócios. -
Um portal unificado de análise de dados permite a colaboração em torno dos dados, fornecendo uma visão dos produtos de dados por meio de governança federada. A Amazon DataZone permite um fluxo de trabalho de AWS Glue Data Catalog autoatendimento com o backby AWS Lake Formation, para que os usuários possam compartilhar, pesquisar, descobrir dados e solicitar permissão para consumo.
-
Os consumidores de dados podem acessar dados, criar visualizações downstream e usar ferramentas específicas, como Amazon Athena, Amazon, Amazon Redshift
, Amazon AI e QuickSight Amazon Bedrock, para fazer o SageMaker seguinte : -
Análise operacional
-
Informática clínica
-
Pesquisa
-
Engajamento clínico e do paciente
Os consumidores de dados também podem desenvolver aplicativos inovadores usando IA generativa e podem publicar produtos de dados no catálogo comercial.
-
Para obter mais informações sobre a arquitetura de malha de dados, consulte O que é uma malha de dados?
IA generativa
As organizações de saúde estão usando a IA generativa para uma variedade de aplicações, desde a automatização da interpretação de imagens médicas até a geração de recomendações de diagnóstico e planos de tratamento com base em dados textuais e de imagem. A adoção da IA generativa está acelerando a inovação e aumentando a eficiência em todo o processo de atendimento. O novo foco na IA generativa forçou a área de saúde a expandir seu foco em dados para incluir mais formas de dados não estruturados, expandindo o número e a variedade de casos de uso relacionados à IA. Em geral, há quatro padrões que as organizações podem escolher, dependendo do caso de uso, para implementar soluções generativas de IA:
-
Engenharia rápida — Na engenharia rápida, os usuários fornecem dados relevantes como contexto, orientando o modelo generativo de IA para criar o conteúdo que desejam. Organizações com uma estratégia moderna de dados de saúde podem garantir que os dados relevantes sejam facilmente detectáveis, compartilháveis e consumíveis.
-
Geração Aumentada de Recuperação (RAG) — O padrão RAG se baseia na engenharia imediata. Em vez de um usuário fornecer dados relevantes, um programa intercepta a pergunta ou a entrada do usuário. O programa pesquisa em um repositório de dados para recuperar conteúdo relevante para a pergunta ou entrada. O programa envia os dados encontrados ao modelo generativo de IA para gerar conteúdo. Uma estratégia moderna de dados de saúde permite a curadoria e a indexação de dados corporativos. Os dados podem então ser pesquisados e usados como contexto para solicitações ou perguntas, auxiliando um modelo de linguagem grande (LLM) na geração de respostas.
Sua organização pode usar os dois padrões a seguir para concentrar os resultados do modelo de IA generativo na geração de conteúdo apropriado ao contexto de seus dados.
-
Ajuste fino — Usando esse padrão, sua organização pode dar um passo adiante personalizando modelos generativos de IA. Isso envolve o ajuste fino dos modelos em uma pequena amostra de dados específicos da organização. Como o tamanho da amostra é pequeno, esse padrão fornece um equilíbrio entre custo e personalização. Para evitar vieses nas saídas do modelo, use um pequeno conjunto de dados de amostra que seja o mais diverso e representativo possível dos padrões de dados da sua organização. Uma estratégia moderna de dados de saúde oferece acesso eficiente a uma ampla variedade de dados para preparar os conjuntos de dados de amostra.
-
Crie seu próprio modelo — Se sua organização precisar gerar conteúdo em grandes volumes de dados altamente especializados e os três padrões anteriores não forem adequados, você poderá criar seus próprios modelos.
Uma estratégia de dados moderna desempenha um papel fundamental nas soluções generativas de IA, ajudando a garantir que os dados tenham as seguintes características:
-
Dados de alta qualidade para apoiar a precisão
-
Dados em tempo real ou quase em tempo real para ajudar a garantir que as saídas do modelo sejam relevantes
-
Várias modalidades de dados em uma variedade de fontes de dados para fornecer ao modelo acesso a conjuntos de dados enriquecidos para gerar conteúdo
O diagrama a seguir mostra a implementação de uma estratégia moderna de dados de saúde que usa uma arquitetura de malha de dados para dar suporte a soluções generativas de IA.
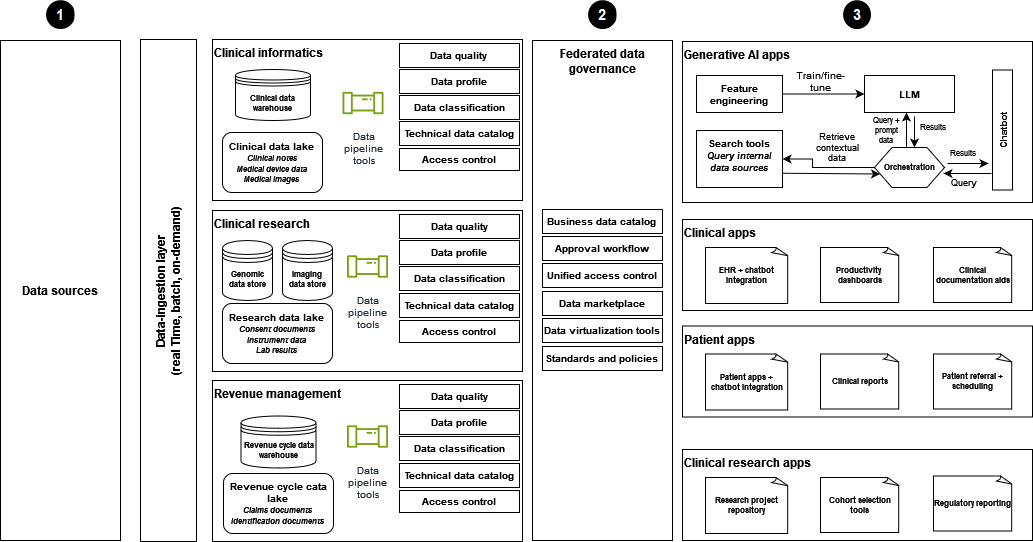
-
Os dados são ingeridos de diversas fontes de dados nos domínios de Informática Clínica, Pesquisa Clínica e Gerenciamento de Receita, e os dados são disponibilizados para a organização de saúde.
-
A governança de dados federados ajuda a garantir um controle de acesso rigoroso para compartilhamento de dados e acesso unificado.
-
Os consumidores de dados incluem o seguinte:
-
Aplicativos generativos de IA, especialmente aqueles que usam dados para treinar e ajustar LLMs. Esses aplicativos usam dados corporativos para chatbots de perguntas e respostas para aprimorar a eficiência operacional e as experiências de pacientes e provedores.
-
Aplicativos clínicos equipados com ferramentas como chatbots integrados ao EHR, painéis de produtividade e auxílios de documentação.
-
Aplicativos centrados no paciente para melhorar as experiências dos pacientes. Esses aplicativos apresentam interações de chatbots, relatórios clínicos e processos eficientes de encaminhamento e agendamento.
-
Pesquisa clínica, com um repositório de projetos de pesquisa e aplicativos projetados para análise de coorte e relatórios regulatórios.
-
Com essa arquitetura, as partes interessadas em sua organização podem se concentrar na curadoria e no gerenciamento dos dados coletados de outras fontes, ao mesmo tempo em que tornam seus próprios dados acessíveis ao resto da organização. Eles podem usar ferramentas que estão disponíveis na camada de governança de dados federados para definir metadados, gerenciar fluxos de trabalho de aprovação de acesso e definir e aplicar políticas. Além disso, a camada de governança de dados federados fornece controle de acesso centralizado. Isso cria um ambiente para organizar uma variedade de fontes de dados e atualizar ativos de dados de alta qualidade em uma frequência especificada para manter a relevância. AWS oferece um conjunto abrangente de recursos para atender às suas necessidades generativas de IA. O Amazon Bedrock
