As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Dimensione a capacidade do cluster
Se seu trabalho está demorando muito, mas os executores estão consumindo recursos suficientes e o Spark está criando um grande volume de tarefas em relação aos núcleos disponíveis, considere escalar a capacidade do cluster. Para avaliar se isso é apropriado, use as métricas a seguir.
CloudWatch métricas
-
Verifique a carga da CPU e a utilização da memória para determinar se os executores estão consumindo recursos suficientes.
-
Verifique há quanto tempo o trabalho foi executado para avaliar se o tempo de processamento é muito longo para atender às suas metas de desempenho.
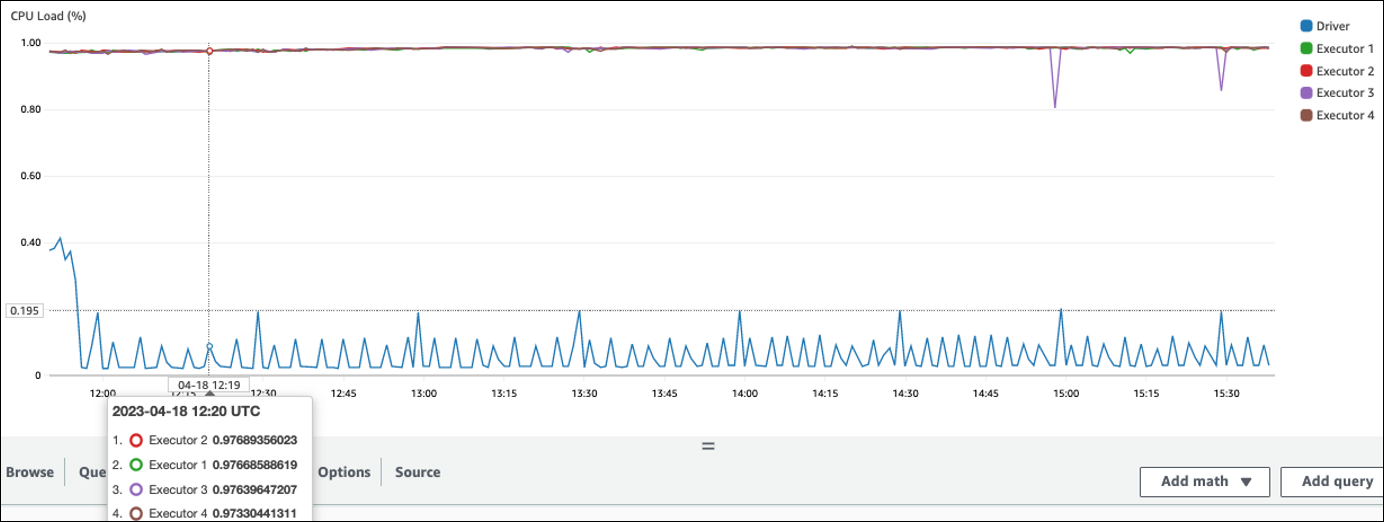
No exemplo a seguir, quatro executores estão sendo executados com mais de 97% da carga da CPU, mas o processamento não foi concluído após cerca de três horas.
nota
Se a carga da CPU for baixa, você provavelmente não se beneficiará com a escalabilidade da capacidade do cluster.
IU do Spark
Na guia Job ou na guia Stage, você pode ver o número de tarefas para cada trabalho ou estágio. No exemplo a seguir, o Spark criou 58100 tarefas.

Na guia Executor, você pode ver o número total de executores e tarefas. Na captura de tela a seguir, cada executor do Spark tem quatro núcleos e pode realizar quatro tarefas simultaneamente.
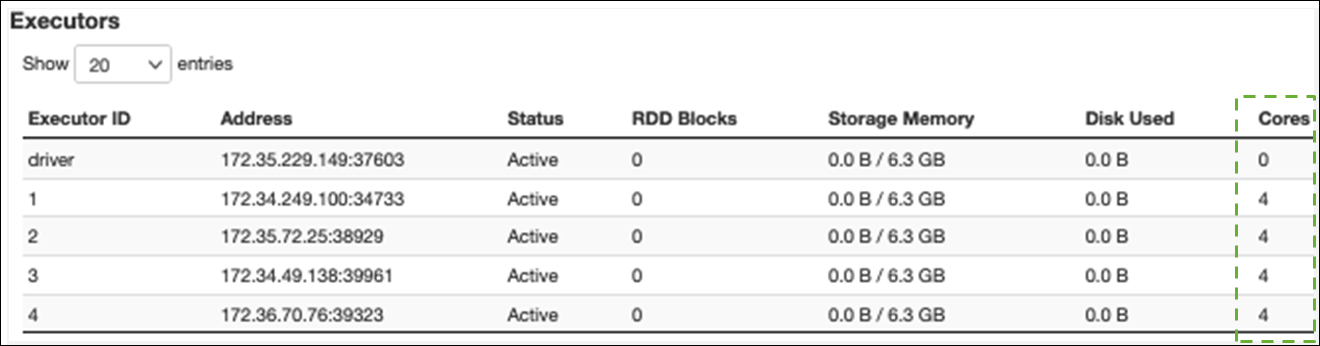
Neste exemplo, o número de tarefas do Spark () 58100) é muito maior do que as 16 tarefas que os executores podem processar simultaneamente (4 executores × 4 núcleos).
Se você observar esses sintomas, considere escalar o cluster. Você pode escalar a capacidade do cluster usando as seguintes opções:
-
Ativar AWS Glue Auto Scaling — O Auto Scaling está disponível para AWS Glue suas tarefas de extração, transformação e carregamento (ETL) e streaming AWS Glue na versão 3.0 ou posterior. AWS Glue adiciona e remove automaticamente os trabalhadores do cluster, dependendo do número de partições em cada estágio ou da taxa na qual os microlotes são gerados na execução do trabalho.
Se você observar uma situação em que o número de trabalhadores não aumenta mesmo que o Auto Scaling esteja ativado, considere adicionar trabalhadores manualmente. No entanto, observe que escalar manualmente para um estágio pode fazer com que muitos trabalhadores fiquem ociosos durante os estágios posteriores, custando mais sem nenhum ganho de desempenho.
Depois de ativar o Auto Scaling, você pode ver o número de executores nas métricas do executor. CloudWatch Use as seguintes métricas para monitorar a demanda por executores nos aplicativos Spark:
-
glue.driver.ExecutorAllocationManager.executors.numberAllExecutors -
glue.driver.ExecutorAllocationManager.executors.numberMaxNeededExecutors
Para obter mais informações sobre métricas, consulte Monitoramento AWS Glue usando CloudWatch métricas da Amazon.
-
-
Expandir: aumente o número de AWS Glue trabalhadores — Você pode aumentar manualmente o número de AWS Glue trabalhadores. Adicione trabalhadores somente até observar trabalhadores ociosos. Nesse ponto, adicionar mais trabalhadores aumentará os custos sem melhorar os resultados. Para obter mais informações, consulte Paralelizar tarefas.
-
Amplie: use um tipo de trabalhador maior — você pode alterar manualmente o tipo de instância de seus AWS Glue trabalhadores para usar trabalhadores com mais núcleos, memória e armazenamento. Tipos de trabalhadores maiores possibilitam que você escale verticalmente e execute trabalhos intensivos de integração de dados, como transformações de dados que consomem muita memória, agregações distorcidas e verificações de detecção de entidades envolvendo petabytes de dados.
A ampliação também ajuda nos casos em que o driver do Spark precisa de maior capacidade, por exemplo, porque o plano de consulta de tarefas é muito grande. Para obter mais informações sobre tipos de trabalhadores e desempenho, consulte a postagem do blog AWS Big Data Dimensione suas AWS Glue tarefas do Apache Spark com novos tipos de trabalhadores maiores G.4X e G.8X.
O uso de trabalhadores maiores também pode reduzir o número total de trabalhadores necessários, o que aumenta o desempenho ao reduzir a confusão em operações intensivas, como junção.
