As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Arquitetura para um sistema escalável de rastreamento da web em AWS
O diagrama de arquitetura a seguir mostra um sistema de rastreador da Web projetado para extrair de forma ética dados ambientais, sociais e de governança (ESG) dos sites. Você usa um Pythonrastreador baseado que é otimizado para AWS infraestrutura. Você usa AWS Batch para orquestrar os trabalhos de rastreamento em grande escala e usa o Amazon Simple Storage Service (Amazon S3) para armazenamento. Os aplicativos downstream podem ingerir e armazenar os dados do bucket do Amazon S3.
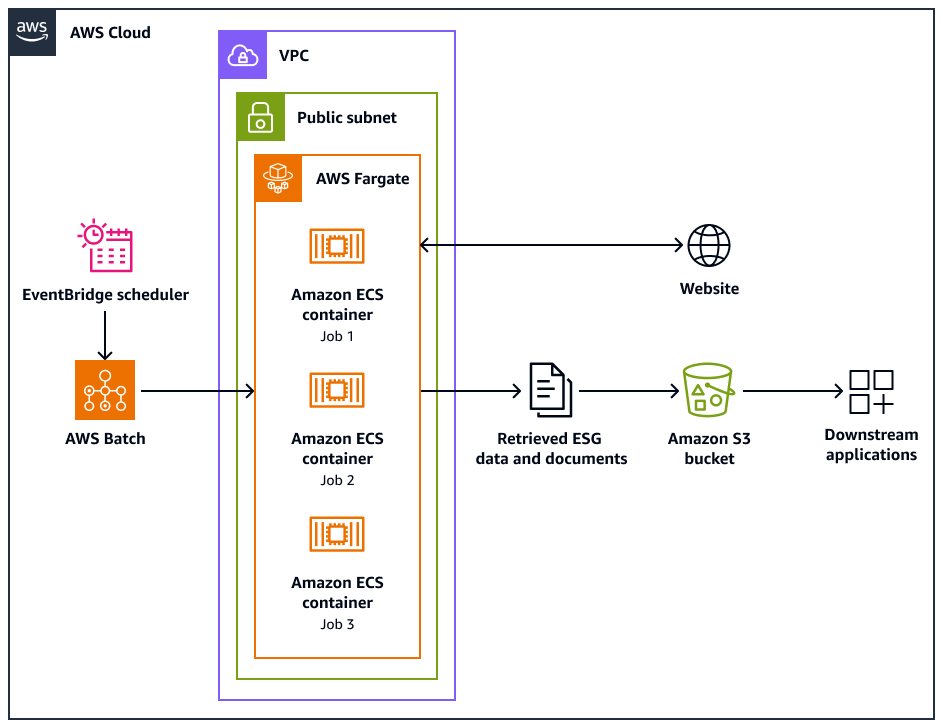
O diagrama mostra o seguinte fluxo de trabalho:
-
O Amazon EventBridge Scheduler inicia o processo de rastreamento em um intervalo programado por você.
-
AWS Batch gerencia a execução dos trabalhos do rastreador da web. A fila de AWS Batch trabalhos retém e orquestra os trabalhos de rastreamento pendentes.
-
Os trabalhos de rastreamento da web são executados em contêineres do Amazon Elastic Container Service (Amazon ECS) em. AWS Fargate Os trabalhos são executados em uma sub-rede pública de uma nuvem privada virtual (VPC).
-
O rastreador da web rastreia o site de destino e recupera dados e documentos do ESG, como PDF, CSV ou outros arquivos de documentos.
-
O rastreador da web armazena os dados recuperados e os arquivos brutos em um bucket do Amazon S3.
-
Outros sistemas ou aplicativos ingerem ou processam os dados e arquivos armazenados no bucket do Amazon S3.
Design e operações de rastreadores da Web
Alguns sites são projetados especificamente para serem executados em desktops ou dispositivos móveis. O rastreador da Web foi projetado para oferecer suporte ao uso de um agente de usuário de desktop ou de um agente de usuário móvel. Esses agentes ajudam você a fazer solicitações com sucesso ao site de destino.
Depois que o rastreador da web é inicializado, ele executa as seguintes operações:
-
O rastreador da web chama o
setup()método. Esse método busca e analisa o arquivo robots.txt.nota
Você também pode configurar o rastreador da web para buscar e analisar o mapa do site.
-
O rastreador da web processa o arquivo robots.txt. Se um atraso de rastreamento for especificado no arquivo robots.txt, o rastreador da Web extrairá o atraso de rastreamento para o agente de usuário de desktop. Se um atraso de rastreamento não for especificado no arquivo robots.txt, o rastreador da Web usará um atraso aleatório.
-
O rastreador da web chama o
crawl()método, que inicia o processo de rastreamento. Se não URLs houver nenhum na fila, ele adiciona a URL inicial.nota
O rastreador continua até atingir o número máximo de páginas ou ficar sem espaço URLs para rastrear.
-
O rastreador processa o. URLs Para cada URL na fila, o rastreador verifica se a URL já foi rastreada.
-
Se um URL não tiver sido rastreado, o rastreador chama o método da
crawl_url()seguinte forma:-
O rastreador verifica o arquivo robots.txt para determinar se ele pode usar o agente de usuário de desktop para rastrear a URL.
-
Se permitido, o rastreador tentará rastrear o URL usando o agente de usuário de desktop.
-
Se não for permitido ou se o user agent de desktop falhar no rastreamento, o rastreador verificará o arquivo robots.txt para determinar se ele pode usar o agente de usuário móvel para rastrear o URL.
-
Se permitido, o rastreador tentará rastrear o URL usando o agente de usuário móvel.
-
-
O rastreador chama o
attempt_crawl()método, que recupera e processa o conteúdo. O rastreador envia uma solicitação GET para o URL com os cabeçalhos apropriados. Se a solicitação falhar, o rastreador usa a lógica de repetição. -
Se o arquivo estiver no formato HTML, o rastreador chamará o
extract_esg_data()método. Ele usa Beautiful Souppara analisar o conteúdo HTML. Ele extrai dados ambientais, sociais e de governança (ESG) usando a correspondência de palavras-chave. Se o arquivo for um PDF, o rastreador chamará o
save_pdf()método. O rastreador baixa e salva o arquivo PDF no bucket do Amazon S3. -
O rastreador chama o
extract_news_links()método. Isso encontra e armazena links para artigos de notícias, comunicados à imprensa e postagens de blog. -
O rastreador chama o
extract_pdf_links()método. Isso identifica e armazena links para documentos PDF. -
O rastreador chama o
is_relevant_to_sustainable_finance()método. Isso verifica se as notícias ou artigos estão relacionados a finanças sustentáveis usando palavras-chave predefinidas. -
Depois de cada tentativa de rastreamento, o rastreador implementa um atraso usando o método.
delay()Se um atraso foi especificado no arquivo robots.txt, ele usa esse valor. Caso contrário, ele usa um atraso aleatório entre 1 e 3 segundos. -
O rastreador chama o
save_esg_data()método para salvar os dados do ESG em um arquivo CSV. O arquivo CSV é salvo no bucket do Amazon S3. -
O rastreador chama o
save_news_links()método para salvar os links de notícias em um arquivo CSV, incluindo informações relevantes. O arquivo CSV é salvo no bucket do Amazon S3. -
O rastreador chama o
save_pdf_links()método para salvar os links do PDF em um arquivo CSV. O arquivo CSV é salvo no bucket do Amazon S3.
Tratamento em lotes e processamento de dados
O processo de rastreamento é organizado e executado de forma estruturada. AWS Batch atribui os trabalhos de cada empresa para que sejam executados paralelamente, em lotes. Cada lote se concentra no domínio e nos subdomínios de uma única empresa, conforme você os identificou em seu conjunto de dados. No entanto, os trabalhos no mesmo lote são executados sequencialmente para que não inundem o site com muitas solicitações. Isso ajuda o aplicativo a gerenciar a carga de trabalho de rastreamento com mais eficiência e a garantir que todos os dados relevantes sejam capturados para cada empresa.
Ao organizar o rastreamento da web em lotes específicos da empresa, isso conteineriza os dados coletados. Isso ajuda a evitar que os dados de uma empresa sejam misturados com dados de outras empresas.
O processamento em lotes ajuda o aplicativo a coletar dados da web de forma eficiente, mantendo uma estrutura clara e uma separação de informações com base nas empresas-alvo e seus respectivos domínios da web. Essa abordagem ajuda a garantir a integridade e a usabilidade dos dados coletados, pois estão bem organizados e associados à empresa e aos domínios apropriados.
