O Amazon Redshift não permitirá mais a criação de funções definidas pelo usuário (UDFs) do Python a partir de 1.º de novembro de 2025. Se quiser usar UDFs do Python, você deve criá-las antes dessa data. As UDFs do Python existentes continuarão a funcionar normalmente. Para ter mais informações, consulte a publicação de blog
Armazenamento colunar
Esta seção descreve o armazenamento colunar, que é o método que o Amazon Redshift usa para armazenar dados tabulares de forma eficiente.
O armazenamento colunar para tabelas de bancos de dados é um fator importante na otimização da performance de consulta analítica, pois reduz drasticamente os requisitos de E/S de disco gerais. Ele reduz a quantidade de dados que você precisa carregar do disco.
A série de ilustrações a seguir descreve como o armazenamento de dados colunar implementa eficiências e se converte em eficiências durante a recuperação de dados na memória.
A primeira ilustração mostra como registros de tabelas de banco de dados normalmente são armazenados em blocos de discos por linha.
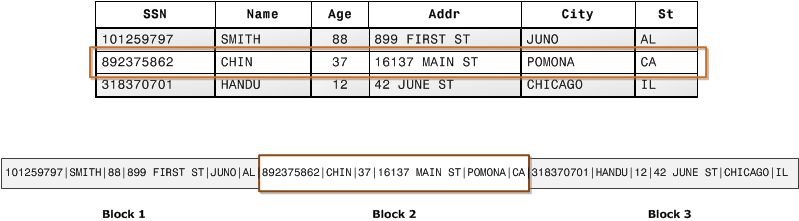
Em uma tabela de banco de dados relacional típica, cada linha contém valores de campo para um único registro. No armazenamento de banco de dados compatível com linha, os blocos de dados armazenam valores sequencialmente para cada coluna consecutiva que compõe toda a linha. Se o tamanho do bloco for menor que o tamanho de um registro, o armazenamento de um registro inteiro poderá usar mais de um bloco. Se o tamanho do bloco for maior que o tamanho de um registro, o armazenamento de um registro inteiro poderá usar menos de um bloco, resultando em um uso ineficiente do espaço em disco. Em aplicativos OLTP, a maioria das transações envolve sempre leitura e gravação de todos os valores de registros inteiros, normalmente um registro ou um pequeno número de registros por vez. Dessa forma, o armazenamento compatível com linha é ideal para bancos de dados OLTP.
A próxima ilustração mostra como, com armazenamento colunar, os valores de cada coluna são armazenados sequencialmente em blocos em disco.
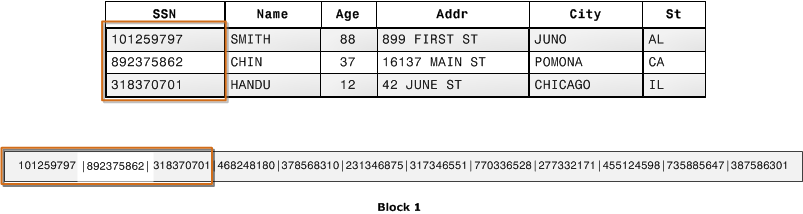
Usando armazenamento columnar, cada bloco de dados armazena valores de uma única coluna de várias linhas. Conforme os registros entram no sistema, o Amazon Redshift converte de forma transparente os dados em armazenamento colunar para cada uma das colunas.
Neste exemplo simplificado, usando armazenamento colunar, cada bloco de dados mantém valores de campo da coluna até três vezes mais do que muitos registros de armazenamento baseado em linha. Isso significa que ler o mesmo número de valores do campo de coluna para o mesmo número de registros exige um terço das operações de E/S em comparação com o armazenamento compatível com linha. Na prática, usando tabelas com números de colunas e contagens de linhas muito grandes, a eficiência do armazenamento é ainda maior.
Uma vantagem adicional é que, como cada bloco contém o mesmo tipo de dados, os dados do bloco podem usar um esquema de compactação selecionado especificamente para o tipo de dados da coluna, reduzindo ainda mais o espaço em disco e E/S. Para obter mais informações sobre codificações de compactação com base em tipos de dados, consulte Codificações de compactação.
A economia em termos de espaço para armazenar dados em disco também chega à recuperação e ao armazenamento desses dados na memória. Como muitas operações de banco de dados precisam somente acessar ou operar uma ou um pequeno número de coluna por vez, você pode economizar espaço na memória somente recuperando blocos para colunas de que realmente precisa para uma consulta. Quando as transações OLTP normalmente envolvem a maioria ou todas as colunas em uma linha para um número pequeno de registros, as consultas de data warehouse normalmente leem somente algumas colunas para um número muito grande de linhas. Isso significa que ler o mesmo número de valores do campo de coluna para o mesmo número de linhas exige uma fração das operações de E/S. Ele usa uma fração da memória que seria necessária para processar blocos em linha. Na prática, usando tabelas com números de colunas e contagens de linhas muito grandes, os ganhos de eficiência são proporcionalmente maiores. Por exemplo, suponhamos que uma tabela contenha 100 colunas. Uma consulta que usa cinco colunas precisará ler somente cerca de cinco por cento dos dados contidos na tabela. Essa economia se repete possivelmente para bilhões ou até mesmo trilhões de registros para bancos de dados grandes. Por outro lado, um banco de dados compatível com linha também leria blocos que contivessem as 95 colunas indesejadas.
Os tamanhos típicos de blocos de banco de dados variam de 2 KB a 32 KB. O Amazon Redshift usa um tamanho de bloco de 1 MB, o que é mais eficiente e reduz ainda mais o número de solicitações de E/S necessárias para executar qualquer carregamento de banco de dados ou outras operações que façam parte da execução de consultas.
