Revisar as etapas do plano de consulta
Você pode visualizar as etapas em um plano de consulta executando o comando EXPLAIN. O exemplo a seguir mostra uma consulta SQL e explica a saída. Ao ler o plano de consulta de baixo para cima, você verá cada uma das operações lógicas usadas para executar a consulta. Para obter mais informações, consulte Criar e interpretar um plano de consulta.
explain select eventname, sum(pricepaid) from sales, event where sales.eventid = event.eventid group by eventname order by 2 desc;
XN Merge (cost=1002815366604.92..1002815366606.36 rows=576 width=27) Merge Key: sum(sales.pricepaid) -> XN Network (cost=1002815366604.92..1002815366606.36 rows=576 width=27) Send to leader -> XN Sort (cost=1002815366604.92..1002815366606.36 rows=576 width=27) Sort Key: sum(sales.pricepaid) -> XN HashAggregate (cost=2815366577.07..2815366578.51 rows=576 width=27) -> XN Hash Join DS_BCAST_INNER (cost=109.98..2815365714.80 rows=172456 width=27) Hash Cond: ("outer".eventid = "inner".eventid) -> XN Seq Scan on sales (cost=0.00..1724.56 rows=172456 width=14) -> XN Hash (cost=87.98..87.98 rows=8798 width=21) -> XN Seq Scan on event (cost=0.00..87.98 rows=8798 width=21)
Como parte da geração de um plano de consulta, o otimizador de consulta divide o plano em fluxos, segmentos e etapas. O otimizador de consulta divide o plano para se preparar para distribuir os dados e o workload da consulta para os nós de computação. Para obter mais informações sobre segmentos e etapas, consulte Planejamento de consulta e fluxo de trabalho de execução.
A ilustração a seguir mostra a consulta anterior e o plano de consulta associado. Ele exibe como as operações de consulta envolvidas são mapeadas para as etapas que o Amazon Redshift usa para gerar o código compilado para as fatias do nó de computação. Cada operação do plano de consulta mapeia para várias etapas dentro dos segmentos e, às vezes, para vários segmentos dentro dos fluxos.
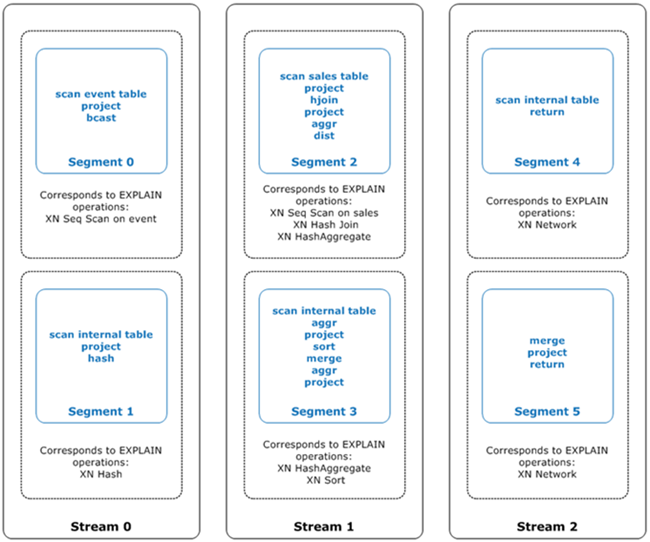
Nesta ilustração, o otimizador de consulta executa o plano de consulta da seguinte forma:
No
Stream 0, a consulta executaSegment 0com uma operação de varredura sequencial para verificar a tabelaevents. A consulta continua paraSegment 1com uma operação de hash para criar a tabela de hash para a tabela interna na junção.No
Stream 1, a consulta executaSegment 2com uma operação de varredura sequencial para verificar a tabelasales. Ele continua comSegment 2com uma junção hash para unir tabelas onde as colunas de junção não são chaves de distribuição e chaves de classificação. Ele continua novamente comSegment 2com um agregado de hash para agregar resultados. Depois, a consulta executaSegment 3com uma operação de agregação de hash para executar funções agregadas agrupadas não classificadas e uma operação de classificação para avaliar a cláusula ORDER BY e outras operações de classificação.Em
Stream 2, a consulta executa uma operação de rede noSegment 4eSegment 5, para enviar resultados intermediários para o nó líder para processamento posterior.
O último segmento de uma consulta retorna os dados. Se o conjunto de retorno for agregado ou classificado, cada um dos nós de computação enviará sua parte do resultado intermediário para o nó líder. O nó líder mescla então os dados para que o resultado final possa ser enviado de volta para o cliente solicitante.
Para obter mais informações sobre operadores EXPLAIN, consulte EXPLAIN.
