Carregamento de dados por ordem de chave de classificação
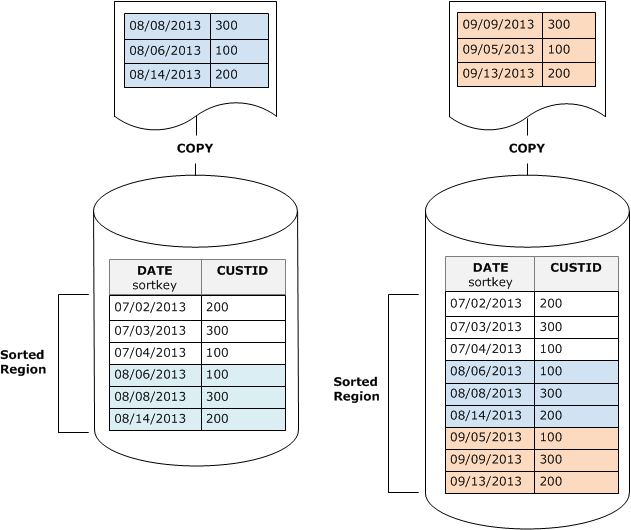
Se você carregar os dados na ordem da chave de classificação usando o comando COPY, poderá reduzir ou até mesmo eliminar a necessidade de limpeza.
COPY adiciona automaticamente linhas novas à região classificada da tabela quando todas as seguintes opções são verdadeiras:
-
A tabela usa uma chave de classificação composta com somente uma coluna de classificação.
-
A coluna de classificação é NOT NULL.
-
A tabela está 100 por cento classificada ou vazia.
-
Todas as linhas novas são mais altas na ordem de classificação que as linhas existentes, incluindo as linhas marcadas para exclusão. Nesse caso, o Amazon Redshift usa os primeiros oito bytes da chave de classificação para determinar a ordem de classificação.
Por exemplo, suponha que você tenha uma tabela que registre eventos de clientes usando um ID de cliente e hora. Se você classificar pelo ID de cliente, é provável que o intervalo de chaves de classificação de novas linhas adicionadas por carregamentos incrementais se sobreponha ao intervalo existente, conforme mostrado no exemplo anterior, resultando em uma operação de limpeza dispendiosa.
Se você definir sua chave de classificação como uma coluna de carimbo de data/hora, suas novas linhas serão anexadas por ordem de classificação no final da tabela, conforme exibido no diagrama a seguir, reduzindo ou até eliminando a necessidade de limpeza.