As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Como definir os conjuntos de dados
A forma como os conjuntos de dados de treinamento e teste são treinados no projeto determina o tipo de modelo criado. Com o Amazon Rekognition Custom Labels, é possível criar modelos que façam o seguinte:
Encontre objetos, cenas e conceitos
O modelo classifica os objetos, cenas e conceitos associados a uma imagem inteira.
É possível criar dois tipos de modelo de classificação, classificação de imagem e classificação de vários rótulos. Para os dois tipos de modelo de classificação, o modelo encontra um ou mais rótulos correspondentes no conjunto completo de rótulos usados para treinamento. Os conjuntos de dados de treinamento e teste exigem pelo menos dois rótulos.
Classificação de imagens
O modelo classifica as imagens como pertencentes a um conjunto de rótulos predefinidos. Por exemplo, convém um modelo que determine se uma imagem contém uma sala de estar. A imagem a seguir pode ter um rótulo de nível de imagem sala_de_estar.

Para este tipo de modelo, adicione um rótulo único em nível de imagem para cada uma das imagens do conjunto de dados de treinamento e teste. Para obter um objeto de exemplo, consulte Classificação de imagens.
Classificação com vários rótulos
O modelo classifica as imagens em várias categorias, como o tipo de flor e se ela tem folhas ou não. Por exemplo, a imagem a seguir pode ter rótulos de nível de imagem mediterranean_spurge e no_leaves.

Para esse tipo de modelo, atribua rótulos em nível de imagem para cada categoria às imagens do conjunto de dados de treinamento e teste. Para obter um objeto de exemplo, consulte Classificação de imagens com vários rótulos.
Como atribuir rótulos em nível de imagem
Se suas imagens estiverem armazenadas em um bucket do Amazon S3, será possível usar nomes de pastas para adicionar automaticamente rótulos em nível de imagem. Para obter mais informações, consulte Importar imagens de um bucket do Amazon S3. Também é possível adicionar rótulos em nível de imagem às imagens depois de criar um conjunto de dados. Para obter mais informações, consulte Como atribuir rótulos em nível de imagem em uma imagem. É possível adicionar novos rótulos conforme necessário. Para obter mais informações, consulte Como gerenciar rótulos.
Encontre localizações de objetos
Para criar um modelo que preveja a localização de objetos em suas imagens, você define caixas delimitadoras e rótulos de localização de objetos para as imagens em seus conjuntos de dados de treinamento e teste. Uma caixa delimitadora é uma caixa que envolve firmemente um objeto. Por exemplo, a imagem a seguir mostra as caixas delimitadoras ao redor de um Amazon Echo e um Amazon Echo Dot. Cada caixa delimitadora tem um rótulo atribuído (Amazon Echo ou Amazon Echo Dot).

Para encontrar a localização dos objetos, seus conjuntos de dados precisam de pelo menos um rótulo. Durante o treinamento do modelo, um rótulo adicional é criado automaticamente, representando a área fora das caixas delimitadoras em uma imagem.
Como atribuir caixas delimitadoras
Ao criar seu conjunto de dados, é possível incluir informações da caixa delimitadora para suas imagens. Por exemplo, você pode importar um arquivo de manifesto no formato SageMaker AI Ground Truth que contém caixas delimitadoras. Também é possível adicionar caixas delimitadoras depois de criar um conjunto de dados. Para obter mais informações, consulte Como rotular objetos com caixas delimitadoras. É possível adicionar novos rótulos conforme necessário. Para obter mais informações, consulte Como gerenciar rótulos.
Encontre localizações de marcas
Se quiser encontrar a localização de marcas, como logotipos e personagens animados, é possível usar dois tipos diferentes de imagens para as imagens do seu conjunto de dados de treinamento.
As imagens que são somente do logotipo. Cada imagem precisa de um único rótulo em nível de imagem que represente o nome do logotipo. Por exemplo, o rótulo em nível de imagem para a imagem a seguir pode ser Lambda.

As imagens que contêm o logotipo em locais naturais, como um jogo de futebol ou um diagrama arquitetônico. Cada imagem de treinamento precisa de caixas delimitadoras que envolvam cada instância do logotipo. Por exemplo, a imagem a seguir mostra um diagrama arquitetônico com caixas delimitadoras rotuladas ao redor dos logotipos do Lambda AWS e do Amazon Pinpoint.
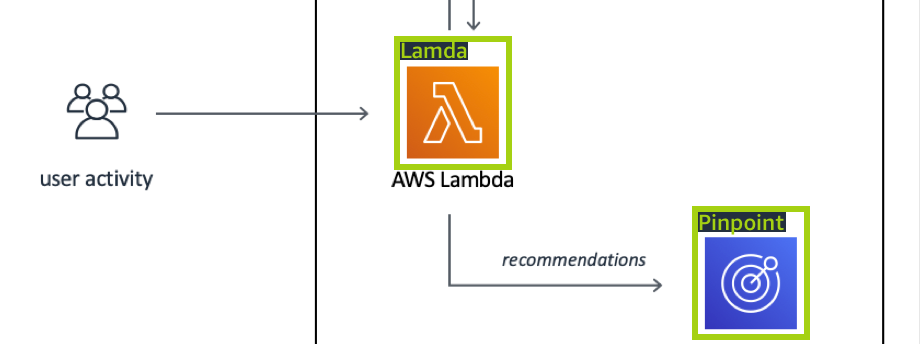
É recomendável não misturar rótulos em nível de imagem e caixas delimitadoras em suas imagens de treinamento.
As imagens de teste devem ter caixas delimitadoras ao redor das instâncias da marca que você deseja encontrar. É possível dividir o conjunto de dados de treinamento para criar o conjunto de dados de teste, somente se as imagens de treinamento incluírem caixas delimitadoras rotuladas. Se as imagens de treinamento tiverem apenas rótulos em nível de imagem, você deverá criar um conjunto de dados de teste que inclua imagens com caixas delimitadoras rotuladas. Se treinar um modelo para encontrar localizações de marcas, faça Como rotular objetos com caixas delimitadoras e Como atribuir rótulos em nível de imagem em uma imagem de acordo com a forma como você rotula suas imagens.
O projeto de exemplo Detecção de marca mostra como o Amazon Rekognition Custom Labels usa caixas delimitadoras rotuladas para treinar um modelo que encontra a localização dos objetos.
Requisitos de rótulo para tipos de modelo
Use a tabela a seguir para determinar como rotular suas imagens.
É possível combinar rótulos no nível da imagem e imagens rotuladas na caixa delimitadora em um único conjunto de dados. Neste caso, o Amazon Rekognition Custom Labels escolhe se deseja criar um modelo em nível de imagem ou um modelo de localização de objetos.
| Exemplo | Imagens de treinamento | Imagens de teste |
|---|---|---|
|
1 Rótulo em nível de imagem por imagem |
1 Rótulo em nível de imagem por imagem |
|
|
Vários rótulos em nível de imagem por imagem |
Vários rótulos em nível de imagem por imagem |
|
|
rótulos de nível de imagem (também é possível usar caixas delimitadoras rotuladas) |
Caixas delimitadoras rotuladas |
|
|
Caixas delimitadoras rotuladas |
Caixas delimitadoras rotuladas |
