As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Relatório de exploração de dados do Autopilot
O Amazon SageMaker Autopilot limpa e pré-processa automaticamente seu conjunto de dados. Dados de alta qualidade melhoram a eficiência do machine learning e produzem modelos que fazem predições mais precisas.
Há problemas com conjuntos de dados fornecidos pelo cliente que não podem ser corrigidos automaticamente sem o benefício de algum conhecimento do domínio. Grandes valores discrepantes na coluna de destino para problemas de regressão, por exemplo, podem causar predições abaixo do ideal para valores não atípicos. Valores atípicos podem precisar ser removidos, dependendo do objetivo do modelo. Se uma coluna de destino for incluída acidentalmente como uma dos atributos de entrada, o modelo final será validado adequadamente, mas terá pouco valor para predições futuras.
Para ajudar os clientes a descobrir esse tipo de problema, o Autopilot fornece um relatório de exploração de dados que contém informações sobre possíveis problemas com seus dados. O relatório também sugere como lidar com os problemas.
Um caderno de exploração de dados contendo o relatório é gerado para cada trabalho do Autopilot. O relatório é armazenado em um bucket do Amazon S3 e pode ser acessado a partir do seu caminho de saída. O caminho do relatório de exploração de dados geralmente segue o padrão a seguir.
[s3 output path]/[name of the automl job]/sagemaker-automl-candidates/[name of processing job used for data analysis]/notebooks/SageMaker AIAutopilotDataExplorationNotebook.ipynb
A localização do notebook de exploração de dados pode ser obtida na API do Autopilot usando a resposta da DescribeAutoMLJoboperação, que é armazenada em DataExplorationNotebookLocation.
Ao executar o Autopilot a partir do SageMaker Studio Classic, você pode abrir o relatório de exploração de dados usando as seguintes etapas:
-
Escolha o ícone Início no painel
 de navegação esquerdo para ver o menu de navegação de nível superior do Amazon SageMaker Studio Classic.
de navegação esquerdo para ver o menu de navegação de nível superior do Amazon SageMaker Studio Classic. -
Selecione o cartão AutoML na área de trabalho principal. Isso abre uma nova guia do Autopilot.
-
Na seção Nome, selecione o job do Autopilot que possui o caderno de exploração de dados que você deseja examinar. Isso abre uma nova guia de trabalhos do Autopilot.
-
Selecione Abrir caderno de exploração de dados na seção superior direita da guia de tarefas do Autopilot.
O relatório de exploração de dados é gerado a partir de seus dados antes do início do processo de treinamento. Isso permite que você interrompa os trabalhos do Autopilot que podem resultar em resultados sem sentido. Da mesma forma, você pode lidar com quaisquer problemas ou melhorias em seu conjunto de dados antes de executar novamente o Autopilot. Dessa forma, você pode utilizar sua expertise de domínio para aprimorar manualmente a qualidade dos dados antes de treinar um modelo em um conjunto de dados mais bem curado.
O relatório de dados contém apenas markdown estática e pode ser aberto em qualquer ambiente Jupyter. O caderno que contém o relatório pode ser convertido em outros formatos, como PDF ou HTML. Para obter mais informações sobre conversões, consulte Usando o script nbconvert para converter cadernos Jupyter
Tópicos
Resumo do conjunto de dados
Este resumo do conjunto de dados fornece as principais estatísticas que caracterizam seu conjunto de dados, incluindo o número de linhas, colunas, porcentagem de linhas duplicadas e valores de destino ausentes. O objetivo é fornecer um alerta rápido quando houver um problema com seu conjunto de dados que o Amazon SageMaker Autopilot detectou e que provavelmente exigirá sua intervenção. As informações são apresentadas como avisos classificados como de gravidade “alta” ou “baixa”. A classificação depende do nível de confiança de que o problema afetará negativamente o desempenho do modelo.
As informações de gravidade alta e baixa aparecem no resumo como pop-ups. Para a maioria das informações, são oferecidas recomendações sobre como confirmar se há um problema com o conjunto de dados que requer sua atenção. Também são fornecidas propostas sobre como resolver os problemas.
O Autopilot fornece estatísticas adicionais sobre valores ausentes ou inválidos no destino em nosso conjunto de dados para ajudar a detectar outros problemas que podem não ser capturados pelos insights de alta gravidade. Um número inesperado de colunas de um determinado tipo pode indicar que algumas colunas que você deseja usar podem estar ausentes do conjunto de dados. Também pode indicar que houve um problema com a forma como os dados foram preparados ou armazenados. A correção desses problemas de dados trazidos à sua atenção pelo Autopilot pode melhorar o desempenho dos modelos de machine learning treinados em seus dados.
Os insights de alta gravidade são mostrados na seção de resumo e em outras seções relevantes do relatório. Geralmente, são fornecidos exemplos de insights de gravidade baixa e alta, dependendo da seção do relatório de dados.
Análise do destino
Vários insights de gravidade baixa e alta são mostrados nesta seção relacionados à distribuição de valores na coluna de destino. Verifique se a coluna de destino contém os valores corretos. Valores incorretos na coluna de destino provavelmente resultarão em um modelo de machine learning que não atende à finalidade comercial pretendida. Vários insights de dados de gravidade baixa e alta estão presentes nesta seção. Aqui estão alguns exemplos:
-
Valores de destino atípicos - Distribuição de destinos distorcida ou incomum para regressão, como destinos com cauda pesada.
-
Cardinalidade destino alta ou baixa - Número infrequente de rótulos de classe ou um grande número de classes exclusivas para classificação.
Para os tipos de problemas de regressão e classificação, valores inválidos, como infinito numérico, NaN ou espaço vazio na coluna de destino, aparecem. Dependendo do tipo de problema, diferentes estatísticas do conjunto de dados são apresentadas. Uma distribuição dos valores da coluna de destino para um problema de regressão permite verificar se a distribuição é a esperada.
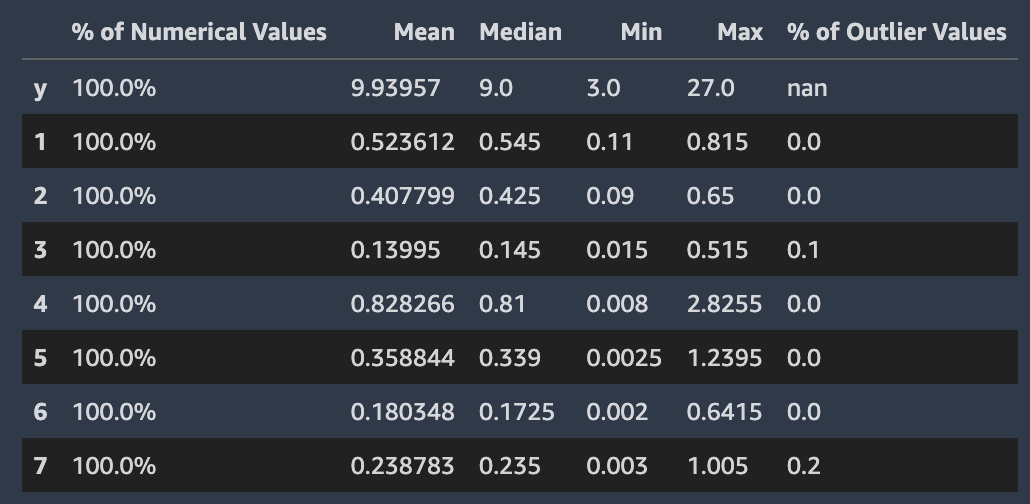
A captura de tela a seguir mostra um relatório de dados do Autopilot, que inclui estatísticas como média, mediana, mínimo, máximo e porcentagem de valores atípicos em seu conjunto de dados. A captura de tela também inclui um histograma mostrando a distribuição dos rótulos na coluna de destino. O histograma mostra os valores da coluna de destino no eixo horizontal e a contagem no eixo vertical. Uma caixa destaca a seção Porcentagem de valores atípicos da captura de tela para indicar onde essa estatística aparece.
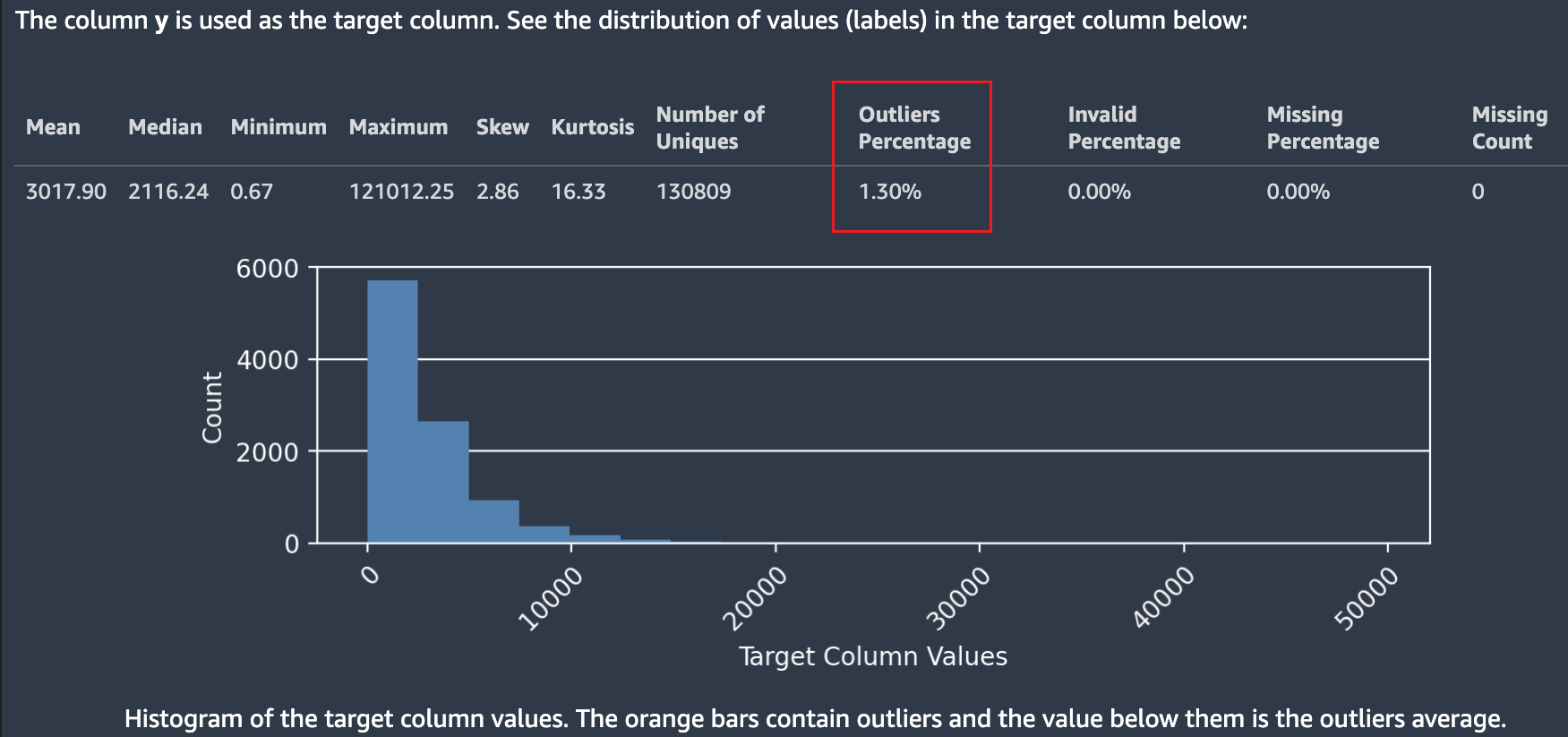
Várias estatísticas são mostradas em relação aos valores de destino e sua distribuição. Se algum dos valores atípicos, valores inválidos ou porcentagens ausentes for maior que zero, esses valores serão exibidos para que você possa investigar por que seus dados contêm valores de destino inutilizáveis. Alguns valores de destino inutilizáveis são destacados como um aviso de visão de gravidade baixa.
Na captura de tela a seguir, um símbolo ` foi adicionado acidentalmente à coluna de destino, o que impediu que o valor numérico do destino fosse analisado. Uma visão de gravidade baixa: aparece o aviso “Valores de destino inválidos”. O aviso neste exemplo indica que "0,14% dos rótulos na coluna de destino não puderam ser convertidos em valores numéricos. Os valores não numéricos mais comuns são: ["-3.8e-05", "-9-05", "-4.7e-05", "-1.4999999999999999e-05", "-4.3e-05"]. Isso geralmente indica que há problemas com a coleta ou o processamento de dados. O Amazon SageMaker Autopilot ignora todas as observações com uma etiqueta de destino inválida.”

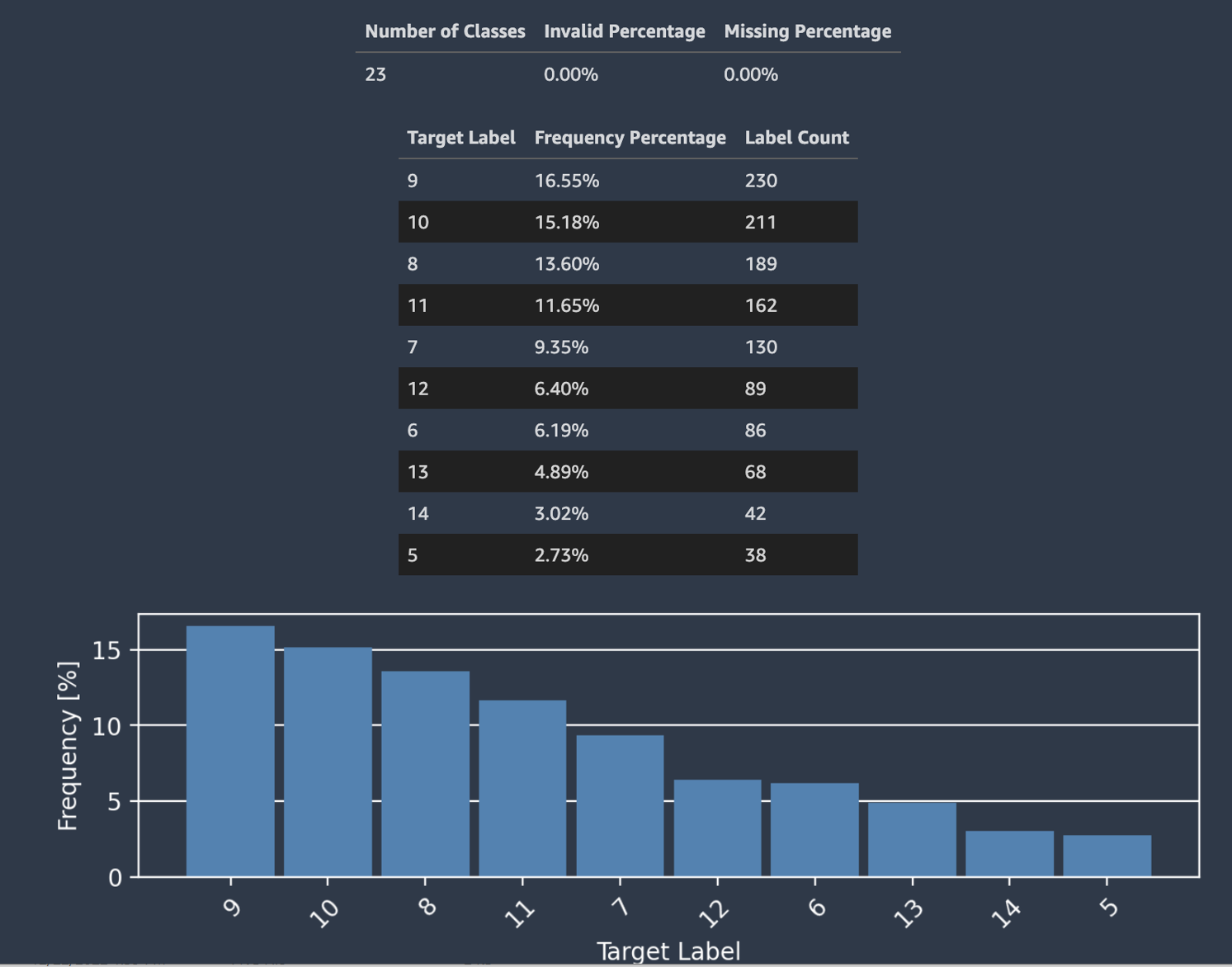
O Autopilot também fornece um histograma mostrando a distribuição dos rótulos para classificação.
A captura de tela a seguir mostra um exemplo de estatísticas fornecidas para sua coluna de destino, incluindo o número de classes, valores ausentes ou não válidos. Um histograma com Rótulo de destino no eixo horizontal e Frequência no eixo vertical mostra a distribuição de cada categoria de rótulo.
nota
Você pode encontrar definições de todos os termos apresentados nesta e em outras seções na seção Definições na parte inferior do caderno de relatórios.
Exemplo de dados
O Autopilot apresenta uma amostra real de seus dados para ajudá-lo a identificar problemas com seu conjunto de dados. A tabela de amostra rola horizontalmente. Inspecione os dados da amostra para verificar se todas as colunas necessárias estão presentes no conjunto de dados.
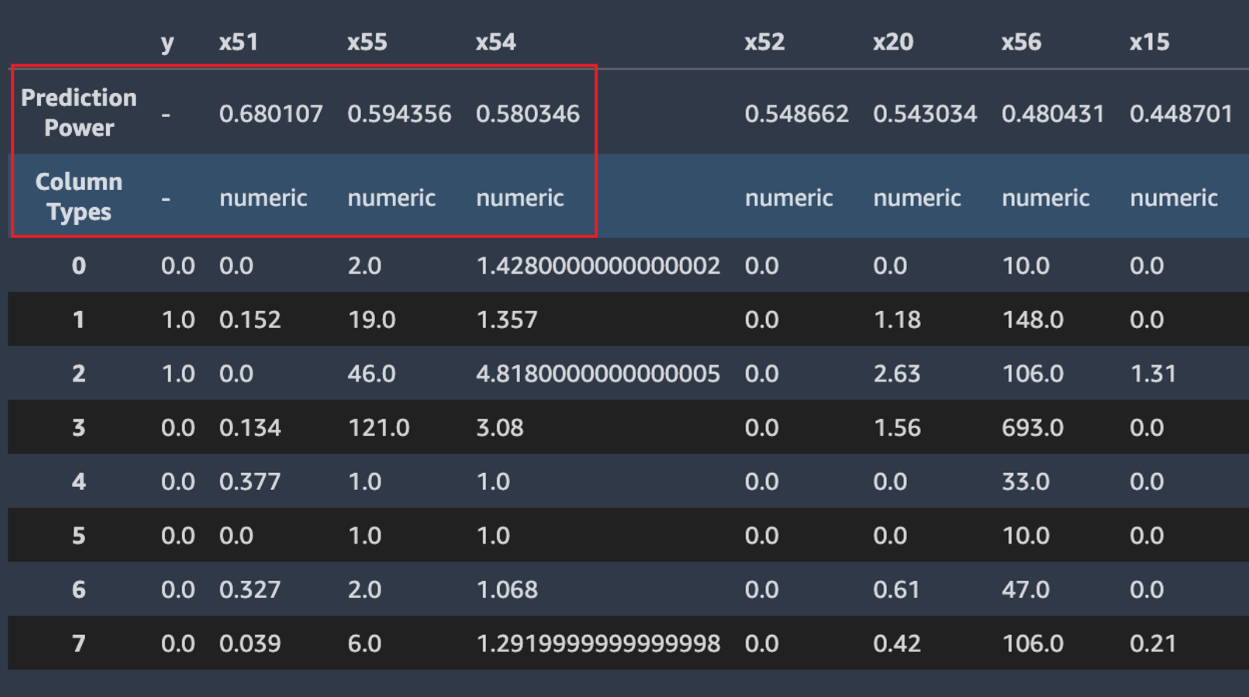
O Autopilot também calcula uma medida do poder de predição, que pode ser usada para identificar uma relação linear ou não linear entre um atributo e a variável destino. Um valor de 0 indica que o atributo não tem valor preditivo na previsão da variável destino. Um valor de 1 indica o maior poder preditivo para a variável destino. Para obter mais informações sobre poder preditivo, consulte a seção Definições.
nota
Não é recomendável usar o poder de predição como substituto da importância do atributo. Use-o somente se tiver certeza de que o poder de predição é uma medida apropriada para seu caso de uso.
A captura de tela a seguir mostra um exemplo de amostra de dados. A linha superior contém o poder de predição de cada coluna em seu conjunto de dados. A segunda linha contém o tipo de dados de coluna. As linhas subsequentes contêm os rótulos. As colunas contêm a coluna de destino seguida por cada coluna de atributo. Cada coluna de atributo tem um poder de predição associado, destacado nesta captura de tela, com uma caixa. Neste exemplo, a coluna que contém o atributo x51 tem um poder preditivo de 0.68 para a variável y de destino. O atributo x55 é um pouco menos preditivo com um poder de predição de 0.59.
Linhas duplicadas
Se houver linhas duplicadas no conjunto de dados, o Amazon SageMaker Autopilot exibirá uma amostra delas.
nota
Não é recomendável balancear um conjunto de dados aumentando a amostragem antes de fornecê-lo ao Autopilot. Isso pode resultar em pontuações de validação imprecisas para os modelos treinados pelo Autopilot, e os modelos produzidos podem ficar inutilizáveis.
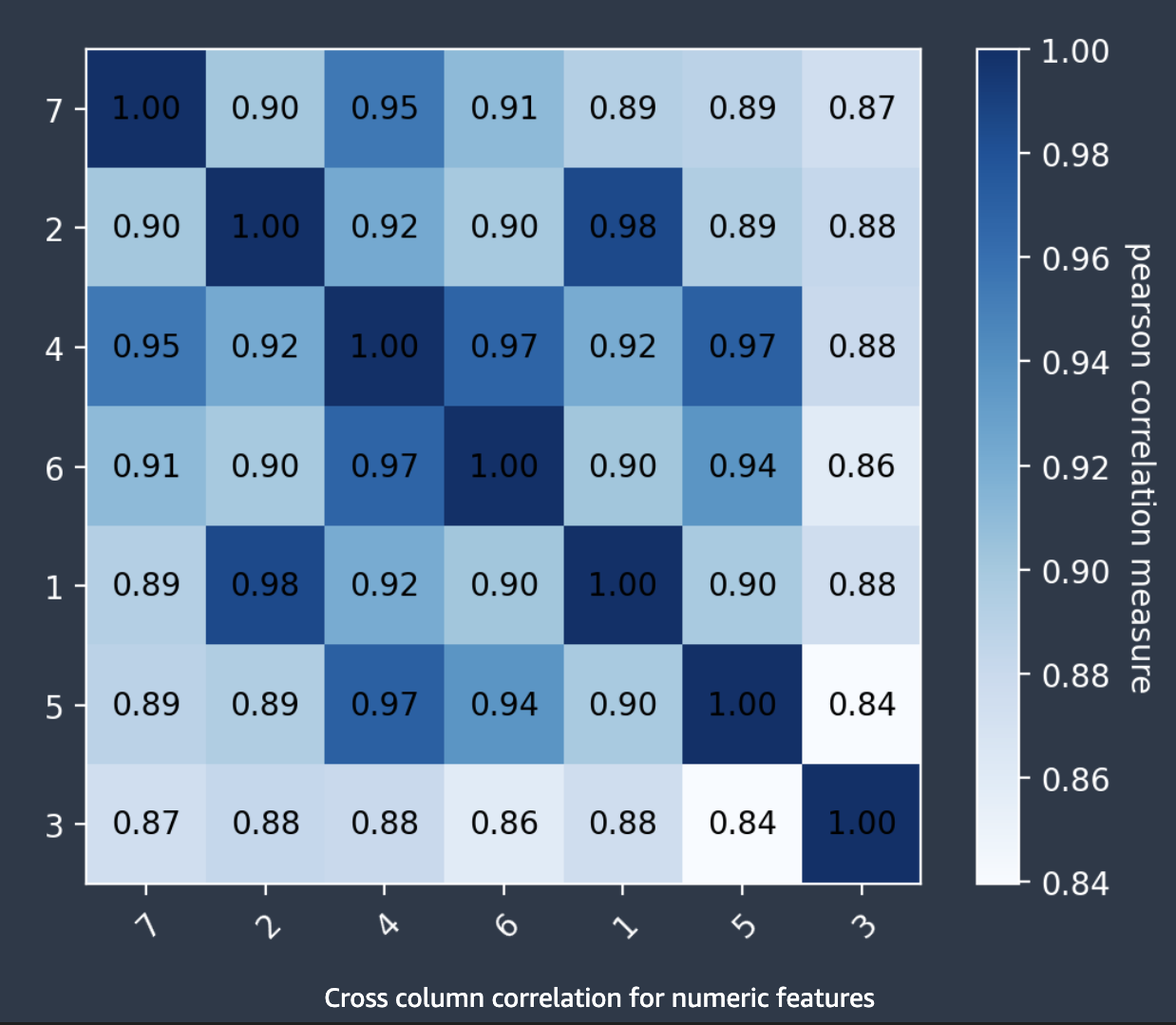
Correlações entre colunas
O Autopilot usa o coeficiente de correlação de Pearson, uma medida de correlação linear entre dois atributos, para preencher uma matriz de correlação. Na matriz de correlação, os atributos numéricos são plotadas nos eixos horizontal e vertical, com o coeficiente de correlação de Pearson traçado em suas interseções. Quanto maior a correlação entre dois atributos, maior o coeficiente, com um valor máximo de |1|.
-
Um valor de
-1indica que os atributos estão perfeitamente correlacionados negativamente. -
Um valor de
1, que ocorre quando um atributo está correlacionado consigo mesmo, indica uma correlação positiva perfeita.
Você pode usar as informações na matriz de correlação para remover atributos altamente correlacionados. Um número menor de atributos reduz as chances de sobreajuste de um modelo e pode reduzir os custos de produção de duas maneiras. Isso diminui o runtime do Autopilot necessário e, para alguns aplicações, pode tornar os procedimentos de coleta de dados mais baratos.
A captura de tela a seguir mostra um exemplo de uma matriz de correlação entre 7 atributos. Cada atributo é exibido em uma matriz nos eixos horizontal e vertical. O coeficiente de correlação de Pearson é exibido na interseção entre dois atributos. Cada interseção de atributos tem um tom de cor associado a ela. Quanto maior a correlação, mais escuro é o tom. Os tons mais escuros ocupam a diagonal da matriz, onde cada atributo está correlacionado consigo mesmo, representando uma correlação perfeita.
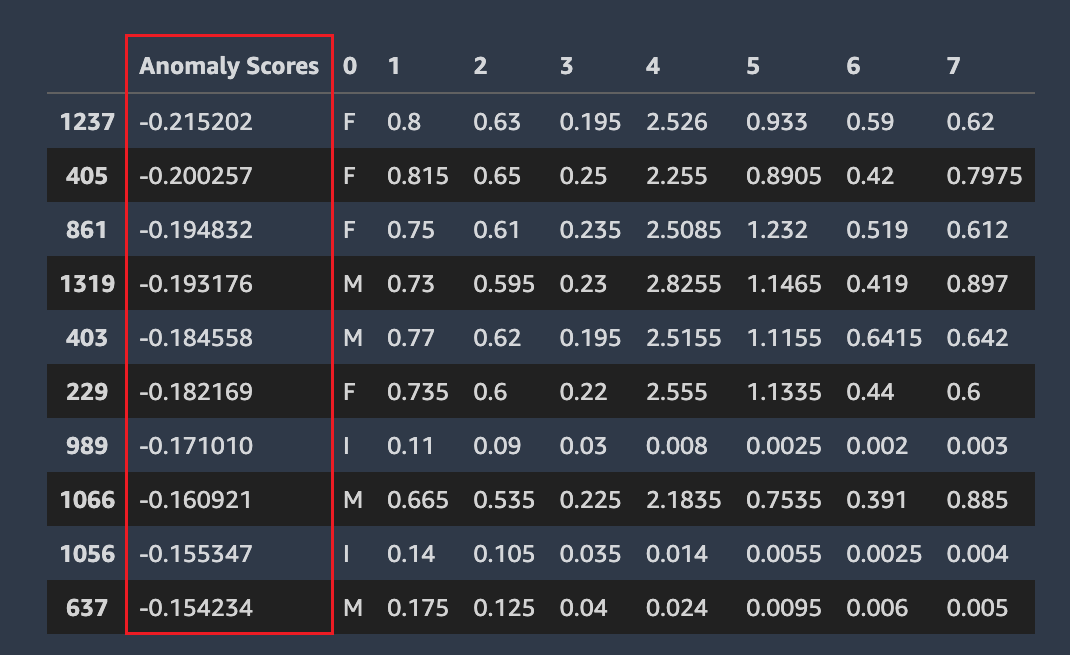
Linhas anômalas
O Amazon SageMaker Autopilot detecta quais linhas em seu conjunto de dados podem ser anômalas. Em seguida, atribui uma pontuação de anomalia a cada linha. As linhas com pontuações negativas de anomalia são consideradas anômalas.
A captura de tela a seguir mostra a saída de uma análise do Autopilot para linhas contendo anomalias. Uma coluna contendo uma pontuação anômala aparece ao lado das colunas do conjunto de dados de cada linha.
Valores ausentes, cardinalidade e estatística descritiva
O Amazon SageMaker Autopilot examina e relata as propriedades das colunas individuais do seu conjunto de dados. Em cada seção do relatório de dados que apresenta essa análise, o conteúdo é organizado em ordem. Isso é para que você possa verificar primeiro os valores mais “suspeitos”. Usando essas estatísticas, você pode melhorar o conteúdo de colunas individuais e melhorar a qualidade do modelo produzido pelo Autopilot.
O Autopilot calcula várias estatísticas sobre os valores categóricos nas colunas que os contêm. Isso inclui o número de entradas exclusivas e, para texto, o número de palavras exclusivas.
O Autopilot calcula várias estatísticas padrão sobre os valores numéricos nas colunas que os contêm. A imagem a seguir mostra essas estatísticas, incluindo a média, a mediana, os valores mínimo e máximo e as porcentagens dos tipos numéricos e dos valores discrepantes.