As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Use métricas avançadas em suas análises
A seção a seguir descreve como encontrar e interpretar as métricas avançadas do seu modelo no Amazon SageMaker Canvas.
nota
As métricas avançadas estão disponíveis atualmente somente para modelos de predição numérica e categórica.
Para encontrar a guia Métricas avançadas, faça o seguinte:
-
Abra o aplicativo SageMaker Canvas.
-
No painel de navegação à esquerda, selecione Meus modelos.
-
Escolha o modelo que você construiu.
-
No painel de navegação, escolha a guia Analisar.
-
Na guia Analisar, escolha a guia Métricas avançadas.
Na guia Métricas avançadas, você pode encontrar a guia Desempenho. A tela deve ser algo semelhante ao exibido a seguir.
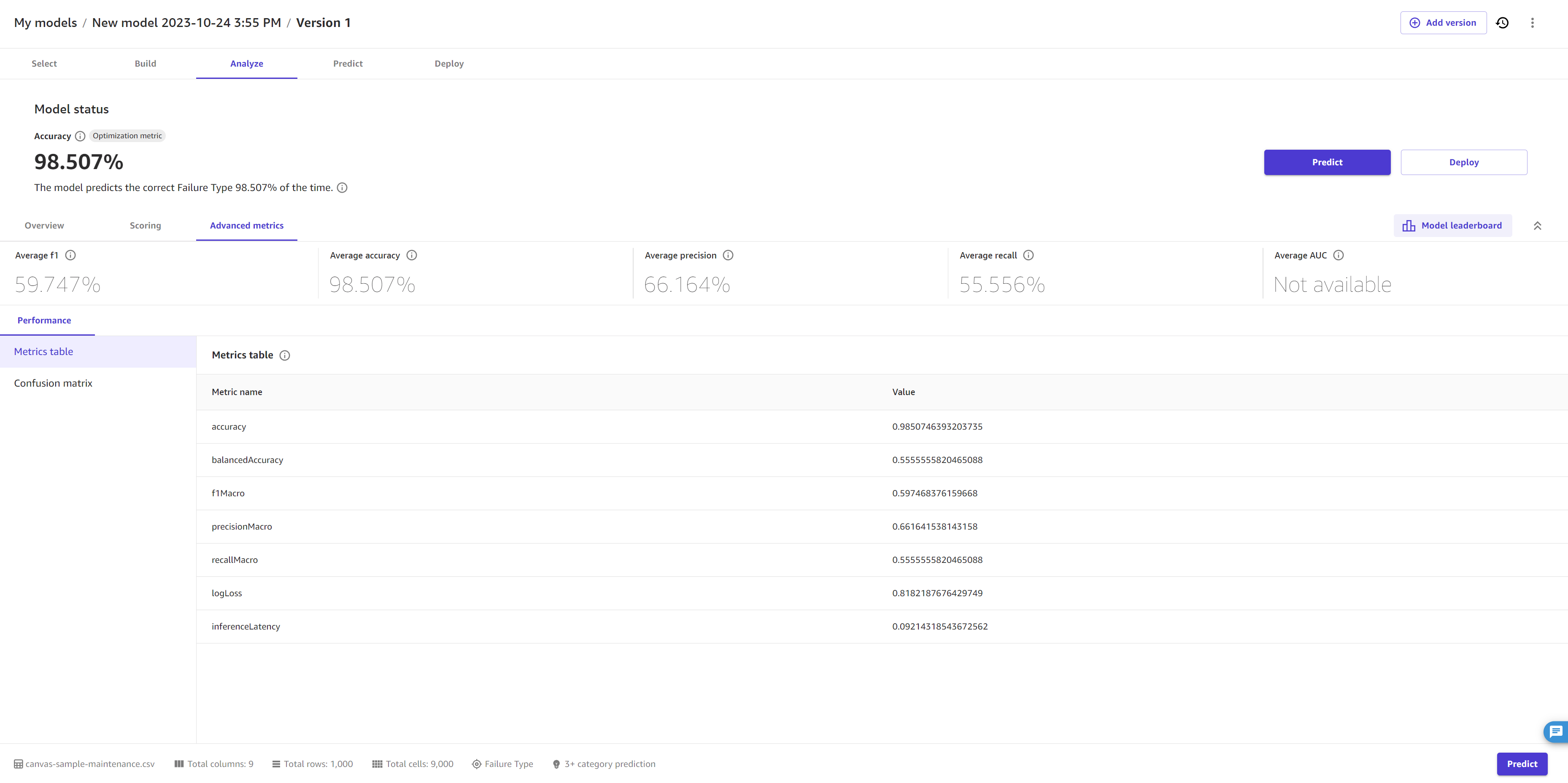
Na parte superior, você pode ver uma visão geral das pontuações métricas, incluindo a métrica de otimização, que é a métrica que você selecionou (ou a que o Canvas selecionou por padrão) para otimizar ao criar o modelo.
As seções a seguir descrevem informações mais detalhadas da guia Desempenho nas métricas avançadas.
Performance
Na guia Desempenho, você verá uma tabela de métricas, junto com as visualizações que o Canvas cria com base no seu tipo de modelo. Para modelos de predição categórica, o Canvas fornece uma matriz de confusão, enquanto para modelos de predição numérica, o Canvas fornece gráficos de resíduos e densidade de erros.
Na tabela Métricas, você recebe uma lista completa das pontuações do seu modelo para cada métrica avançada, que é mais abrangente do que a visão geral das pontuações na parte superior da página. As métricas mostradas aqui dependem do seu tipo de modelo. Para obter uma referência para ajudá-lo a entender e interpretar cada métrica, consulteReferência de métricas.
Para entender as visualizações que podem aparecer com base no seu tipo de modelo, consulte as seguintes opções:
-
Matriz de confusão: O Canvas usa matrizes de confusão para ajudar você a visualizar quando um modelo faz predições corretamente. Em uma matriz de confusão, seus resultados são organizados para comparar os valores previstos com os valores reais. O seguinte exemplo explica como uma matriz de confusão funciona para um modelo de predição de 2 categorias que prevê rótulos positivos e negativos:
-
Positivo verdadeiro: O modelo previu corretamente o positivo quando o rótulo verdadeiro era positivo.
-
Negativo verdadeiro: O modelo previu corretamente o negativo quando o rótulo verdadeiro era negativo.
-
Falso-positivo: O modelo previu incorretamente o positivo previsto quando o rótulo verdadeiro era negativo.
-
Falso-negativo: O modelo previu incorretamente o negativo previsto quando o rótulo verdadeiro era positivo.
-
-
Curva de recuperação de precisão: A curva de recuperação de precisão é uma visualização da pontuação de precisão do modelo traçada em relação à pontuação de recuperação do modelo. Geralmente, um modelo que pode fazer predições perfeitas teria pontuações de precisão e recall que são ambas 1. A curva de recuperação de precisão para um modelo decentemente preciso é bastante alta em precisão e recuperação.
-
Resíduos: Resíduos são a diferença entre os valores reais e os valores previstos pelo modelo. Um gráfico de resíduos representa graficamente os resíduos em relação aos valores correspondentes para visualizar sua distribuição e quaisquer padrões ou valores discrepantes. Uma distribuição normal de resíduos em torno de zero indica que o modelo é adequado para os dados. No entanto, se os resíduos estiverem significativamente distorcidos ou apresentarem valores discrepantes, isso pode indicar que o modelo está ajustando demais os dados ou que há outros problemas que precisam ser resolvidos.
-
Densidade de erro: Um gráfico de densidade de erro é uma representação da distribuição dos erros cometidos por um modelo. Ele mostra a densidade de probabilidade dos erros em cada ponto, ajudando você a identificar quaisquer áreas onde o modelo pode estar com ajuste excessivo ou cometendo erros sistemáticos.
