As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Introdução à biblioteca de paralelismo de dados distribuídos de SageMaker IA
A biblioteca SageMaker AI Distributed Data Parallelism (SMDDP) é uma biblioteca de comunicação coletiva que melhora o desempenho computacional do treinamento paralelo de dados distribuídos. A biblioteca SMDDP aborda a sobrecarga de comunicação das principais operações de comunicação coletiva, oferecendo os seguintes itens:
-
A biblioteca oferece opções
AllReduceotimizadas para AWS.AllReduceé uma operação chave usada para sincronizar gradientes GPUs no final de cada iteração de treinamento durante o treinamento de dados distribuídos. -
A biblioteca oferece opções
AllGatherotimizadas para AWS.AllGatheré outra operação importante usada no treinamento paralelo de dados fragmentados, que é uma técnica de paralelismo de dados com eficiência de memória oferecida por bibliotecas populares, como a biblioteca SageMaker AI model paralelism (SMP), DeepSpeed Zero Redundancy Optimizer (Zero) e Fully Sharded Data Parallelism (FSDP). PyTorch -
A biblioteca realiza uma node-to-node comunicação otimizada utilizando totalmente a infraestrutura de AWS rede e a topologia da EC2 instância da Amazon.
A biblioteca SMDDP pode aumentar a velocidade de treinamento oferecendo melhoria de desempenho à medida que você escala seu cluster de treinamento, com eficiência de ajuste de escala quase linear.
nota
As bibliotecas de treinamento distribuídas por SageMaker IA estão disponíveis por meio dos contêineres de aprendizado AWS profundo PyTorch e do Hugging Face na plataforma de treinamento. SageMaker Para usar as bibliotecas, você deve usar o SageMaker Python SDK ou o SageMaker APIs Through SDK for Python (Boto3) ou. AWS Command Line Interface Em toda a documentação, as instruções e os exemplos se concentram em como usar as bibliotecas de treinamento distribuídas com o SDK do SageMaker Python.
Operações de comunicação coletiva SMDDP otimizadas para recursos AWS computacionais e infraestrutura de rede
A biblioteca SMDDP fornece implementações AllReduce e operações AllGather coletivas que são otimizadas para recursos AWS computacionais e infraestrutura de rede.
Operação coletiva do SMDDP AllReduce
A biblioteca SMDDP alcança a sobreposição ideal da operação AllReduce com o retrocesso, melhorando significativamente a utilização da GPU. Ele alcança eficiência de escalonamento quase linear e velocidade de treinamento mais rápida, otimizando as operações do kernel entre e. CPUs GPUs A biblioteca executa AllReduce em paralelo enquanto a GPU calcula gradientes sem eliminar ciclos adicionais da GPU, o que faz a biblioteca alcançar treinamento mais rápido.
-
Aproveitamentos CPUs: a biblioteca usa dois CPUs
AllReducegradientes, descarregando essa tarefa do. GPUs -
Melhor uso da GPU: o GPUs foco do cluster nos gradientes de computação, melhorando sua utilização durante o treinamento.
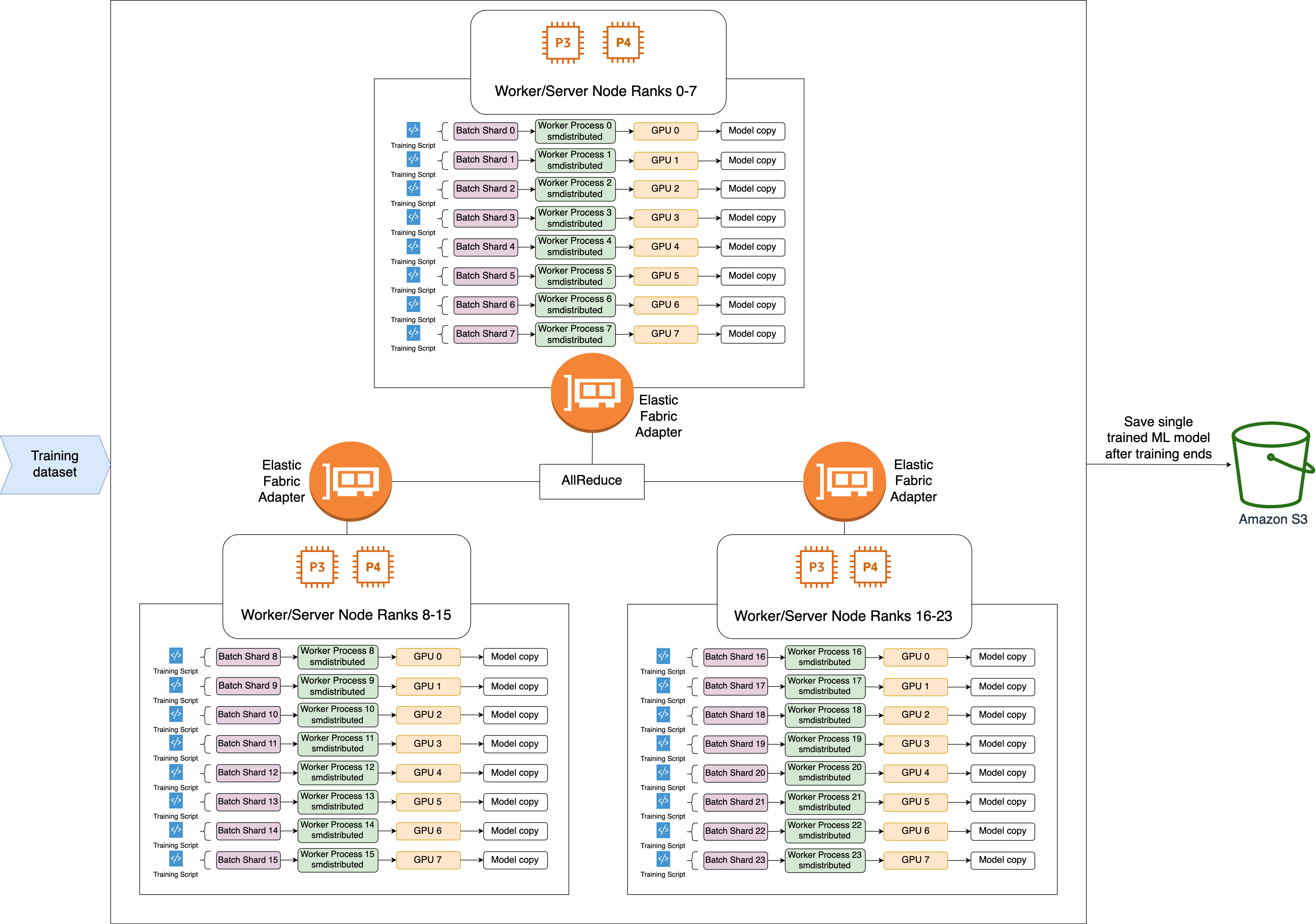
A seguir, é apresentado o fluxo de trabalho de alto nível da operação SMDDP AllReduce.
-
A biblioteca atribui classificações a GPUs (trabalhadores).
-
Em cada iteração, a biblioteca divide cada lote global pelo número total de operadores (tamanho mundial) e atribui pequenos lotes (fragmentos de lote) aos operadores.
-
O tamanho do lote global é
(number of nodes in a cluster) * (number of GPUs per node) * (per batch shard). -
Um fragmento de lote (ou lote pequeno) é um subconjunto do conjunto de dados atribuído a cada GPU (operador) por iteração.
-
-
A biblioteca inicia um script de treinamento em cada operador.
-
A biblioteca gerencia cópias dos pesos do modelo e gradientes dos operadores ao final de cada iteração.
-
A biblioteca sincroniza os pesos e gradientes do modelo entre os operadores para agregar um único modelo treinado.
O diagrama de arquitetura a seguir mostra um exemplo de como a biblioteca configura o paralelismo de dados para um cluster de 3 nós.
Operação coletiva do SMDDP AllGather
AllGather é uma operação coletiva em que cada operador começa com um buffer de entrada e, em seguida, concatena ou reúne os buffers de entrada de todos os outros operadores em um buffer de saída.
nota
A operação AllGather coletiva SMDDP está disponível em AWS Deep Learning Containers (DLC) para PyTorch v2.0.1 smdistributed-dataparallel>=2.0.1 e versões posteriores.
AllGather é muito usado em técnicas de treinamento distribuído, como paralelismo de dados fragmentados, em que cada operador individual detém uma fração de um modelo ou uma camada fragmentada. Os operadores chamam AllGather antes de avançar e retroceder para reconstruir as camadas fragmentadas. Os avanços e retrocessos continuam progressivamente depois que os parâmetros são todos reunidos. Durante o retrocesso, cada operador também chama ReduceScatter para coletar (reduzir) gradientes e dividi-los (dispersá-los) em fragmentos de gradiente para atualizar a camada fragmentada correspondente. Para obter mais detalhes sobre o papel dessas operações coletivas no paralelismo de dados fragmentados, consulte a implementação do paralelismo de dados fragmentados na biblioteca SMP, ZeRO
Como as operações coletivas AllGather são chamadas em cada iteração, elas são as principais responsáveis pela sobrecarga de comunicação da GPU. A computação mais rápida dessas operações coletivas reflete diretamente em um tempo de treinamento mais curto, sem efeitos colaterais na convergência. Para conseguir isso, a biblioteca SMDDP oferece AllGather otimizado para instâncias P4d
O SMDDP AllGather usa as seguintes técnicas para melhorar o desempenho computacional em instâncias P4d:
-
Transfere dados entre instâncias (entre nós) por meio da rede Elastic Fabric Adapter (EFA)
com uma topologia de malha. O EFA é a solução AWS de rede de baixa latência e alto rendimento. Uma topologia de malha para comunicação de rede entre nós é mais adaptada às características do EFA e AWS da infraestrutura de rede. Em comparação com a topologia em anel NCCL ou árvore que envolve vários saltos de pacotes, o SMDDP evita o acúmulo de latência de vários saltos, pois precisa apenas de um salto. O SMDDP implementa um algoritmo de controle de taxa de rede que equilibra a workload para cada nível de comunicação em uma topologia de malha e atinge uma taxa maior de throughput da rede global. -
Ele adota uma biblioteca de cópias de memória de GPU de baixa latência baseada na tecnologia NVIDIA GPUDirect RDMA (GDRCopy)
para coordenar o tráfego de rede local e EFA. NVLink GDRCopy, uma biblioteca de cópias de memória de GPU de baixa latência oferecida pela NVIDIA, fornece comunicação de baixa latência entre os processos da CPU e os kernels CUDA da GPU. Com essa tecnologia, a biblioteca SMDDP é capaz de canalizar a movimentação de dados dentro e entre nós. -
Reduz o uso de multiprocessadores de streaming de GPU para aumentar a potência computacional para executar kernels de modelos. As instâncias P4d e P4de são equipadas com NVIDIA A100 GPUs, cada uma com 108 multiprocessadores de streaming. Enquanto o NCCL usa até 24 multiprocessadores de streaming para executar operações coletivas, o SMDDP usa menos de 9 multiprocessadores de streaming. Os kernels de computação do modelo coletam os multiprocessadores de streaming salvos para uma computação mais rápida.
