As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Obtenha insights sobre dados e qualidade dos dados
Use o Relatório de qualidade dos dados e insights para realizar uma análise dos dados que você importou para o Data Wrangler. Recomendamos que você crie o relatório após importar o conjunto de dados. Você pode usar o relatório para ajudar você a limpar e processar seus dados. Ele fornece informações como o número de valores ausentes e o número de valores atípicos. Caso tenha problemas com seus dados, como vazamento ou desequilíbrio de destino, o relatório de insights pode chamar sua atenção para esses problemas.
Use o procedimento a seguir para criar um relatório de qualidade dos dados e insights. Ele pressupõe que você já tenha importado um conjunto de dados para o fluxo do Data Wrangler.
Para criar um relatório de qualidade dos dados e insights
-
Escolha um + próximo ao um nó em seu fluxo do Data Wrangler.
-
Selecione Obter insights de dados.
-
Em Nome da análise, especifique um nome para o relatório de insights.
-
(Opcional) Para Coluna de destino, especifique a coluna de destino.
-
Para Tipo de problema, especifique Regressão ou Classificação.
-
Para Tamanho dos dados, especifique uma das opções a seguir:
-
50 mil — Usa as primeiras 50000 linhas do conjunto de dados que você importou para criar o relatório.
-
Conjunto de dados inteiro — Usa o conjunto de dados inteiro que você importou para criar o relatório.
nota
A criação de um relatório de qualidade de dados e insights sobre todo o conjunto de dados usa um trabalho de SageMaker processamento da Amazon. Um trabalho SageMaker de processamento provisiona os recursos computacionais adicionais necessários para obter insights sobre todos os seus dados. Para obter mais informações sobre trabalhos SageMaker de processamento, consulteUse trabalhos de processamento para executar cargas de trabalho de transformação de dados.
-
-
Escolha Criar.
Os tópicos a seguir mostram as seções do relatório:
Você pode fazer download do relatório ou visualizá-lo online. Para fazer download do relatório, escolha o botão de download no canto superior direito da tela. A imagem a seguir mostra o botão.

Resumo
O relatório de insights tem um breve resumo dos dados que inclui informações gerais, como valores ausentes, valores inválidos, tipos de recursos, contagens de valores atípicos e muito mais. Ele também pode incluir avisos de severidade alta que apontam para prováveis problemas com os dados. Recomendamos que você investigue os avisos.
Veja a seguir um exemplo de um resumo de relatório.

Coluna de destino
Quando você cria o relatório de qualidade dos dados e insights, o Data Wrangler oferece a opção de selecionar uma coluna de destino. Uma coluna de destino é uma coluna que você está tentando prever. Quando você escolhe uma coluna de destino, o Data Wrangler cria automaticamente uma análise da coluna de destino. Ele também classifica os recursos na ordem de seu poder preditivo. Ao selecionar uma coluna de destino, você deve especificar se está tentando resolver um problema de regressão ou classificação.
Para classificação, o Data Wrangler mostra uma tabela e um histograma das classes mais comuns. Uma classe é uma categoria. Ele também apresenta observações, ou linhas, com um valor de destino ausente ou inválido.
A imagem a seguir mostra um exemplo de análise de coluna de destino para um problema de classificação.
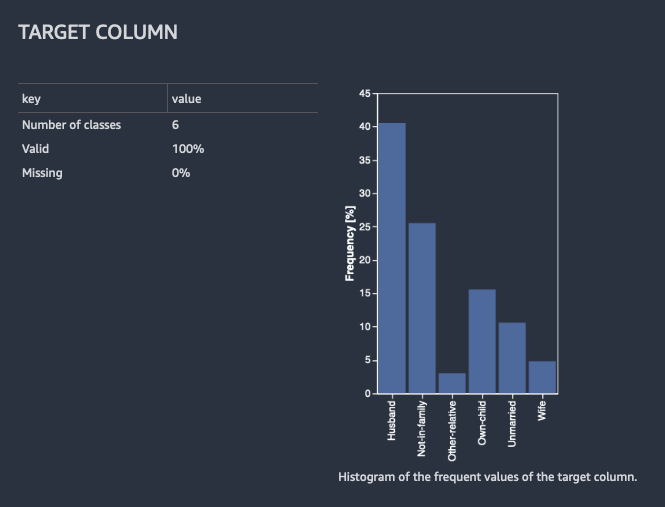
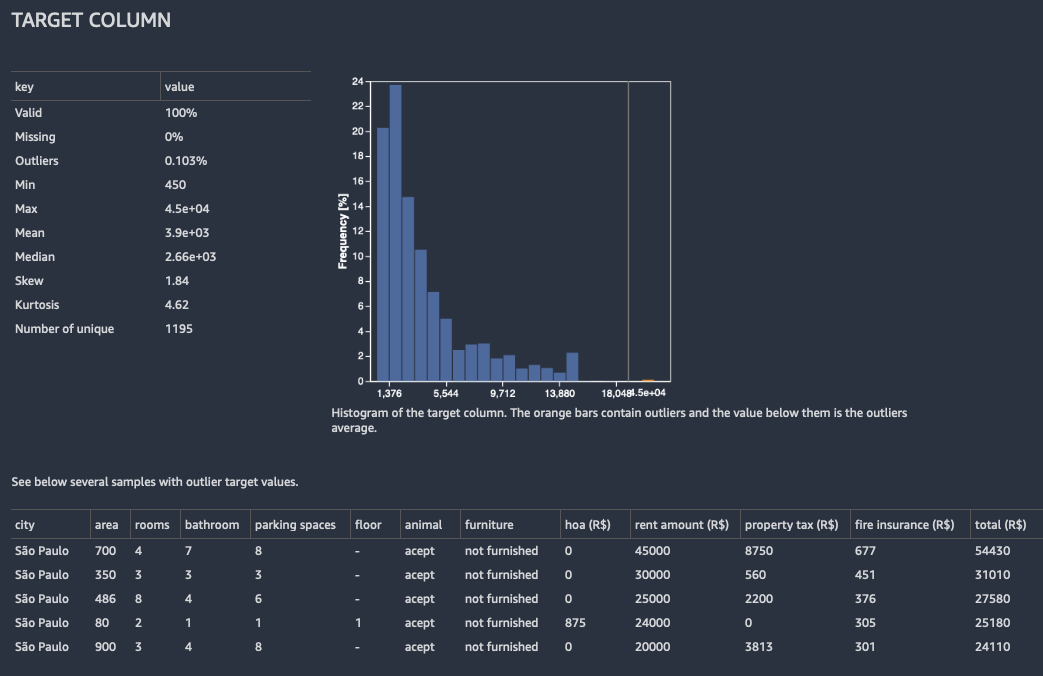
Para regressão, o Data Wrangler mostra um histograma de todos os valores na coluna de destino. Ele também apresenta observações, ou linhas, com um valor de destino ausente, inválido ou atípico.
A imagem a seguir mostra um exemplo de análise de coluna de destino para um problema de regressão.
Modelo rápido
O modelo rápido fornece uma estimativa da qualidade prevista esperada de um modelo que você treina em seus dados.
O Data Wrangler divide seus dados em folds de treinamento e validação. Ele usa 80% das amostras para treinamento e 20% dos valores para validação. Para classificação, a amostra é dividida estratificada. Para uma divisão estratificada, cada partição de dados tem a mesma proporção de rótulos. Para problemas de classificação, é importante ter a mesma proporção de rótulos entre os folds de treinamento e classificação. O Data Wrangler treina o modelo XGBoost com os hiperparâmetros padrão. Ele aplica a interrupção antecipada dos dados de validação e executa o mínimo de pré-processamento de recursos.
Para modelos de classificação, o Data Wrangler retorna um resumo do modelo e uma matriz de confusão.
Este é um exemplo de resumo de modelo de classificação. Para saber mais sobre as informações que ele retorna, consulte Definições.

Este é um exemplo de matriz de confusão que o modelo rápido retorna.

Uma matriz de confusão fornece as seguintes informações:
-
O número de vezes que o rótulo previsto corresponde ao rótulo verdadeiro.
-
O número de vezes que o rótulo previsto não corresponde ao rótulo verdadeiro.
O rótulo verdadeiro representa uma observação real em seus dados. Por exemplo, se você está usando um modelo para detectar transações fraudulentas, o rótulo verdadeiro representa uma transação que é realmente fraudulenta ou não fraudulenta. O rótulo previsto representa o rótulo que seu modelo atribui aos dados.
Você pode usar a matriz de confusão para ver o quão bem o modelo prevê a presença ou a ausência de uma condição. Se você está prevendo transações fraudulentas, pode usar a matriz de confusão para ter uma ideia da sensibilidade e da especificidade do modelo. A sensibilidade se refere à capacidade do modelo de detectar transações fraudulentas. A especificidade se refere à capacidade do modelo de evitar a detecção de transações não fraudulentas como fraudulentas.
Este é um exemplo de resultados do modelo rápido para um problema de regressão.

Resumo de recursos
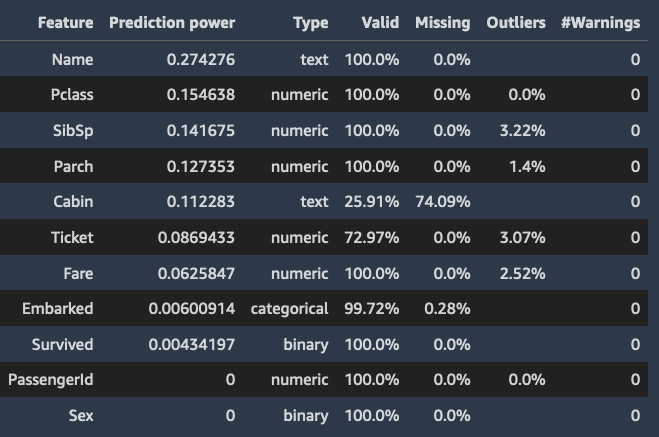
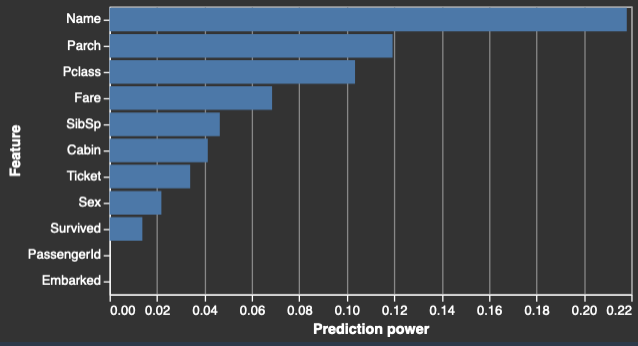
Quando você especifica uma coluna de destino, o Data Wrangler ordena os recursos de acordo com seu poder de previsão. O poder de previsão é medido nos dados após serem divididos em folds de 80% de treinamento e 20% de validação. O Data Wrangler ajusta um modelo para cada recurso separadamente no fold de treinamento. Ele aplica o mínimo de pré-processamento de recursos e mede a performance da previsão nos dados de validação.
Ele normaliza as pontuações para o intervalo [0,1]. Pontuações de previsão mais altas indicam colunas mais úteis para prever o destino sozinhas. Pontuações mais baixas apontam para colunas não preditivas da coluna de destino.
É incomum que uma coluna que não seja preditiva por si só seja preditiva quando usada em conjunto com outras colunas. Você pode usar com confiança as pontuações de previsão para determinar se um recurso em seu conjunto de dados é preditivo.
Uma pontuação baixa geralmente indica que o recurso é redundante. Uma pontuação de 1 indica habilidades preditivas perfeitas, o que geralmente indica vazamento do destino. O vazamento do destino geralmente ocorre quando o conjunto de dados contém uma coluna que não está disponível no momento da previsão. Por exemplo, pode ser uma duplicata da coluna de destino.
Veja a seguir exemplos da tabela e do histograma que mostram o valor de previsão de cada recurso.
Amostras
O Data Wrangler fornece informações sobre se suas amostras são anômalas ou se há duplicatas em seu conjunto de dados.
O Data Wrangler detecta amostras anômalas usando o algoritmo de floresta de isolamento. A floresta de isolamento associa uma pontuação de anomalias a cada amostra (linha) do conjunto de dados. Pontuações de anomalias baixas indicam amostras anômalas. Pontuações altas estão associadas a amostras não anômalas. Amostras com pontuação de anomalias negativas geralmente são consideradas anômalas, e amostras com pontuação de anomalias positivas são consideradas não anômalas.
Ao analisar uma amostra que pode ser anômala, recomendamos que você preste atenção aos valores incomuns. Por exemplo, você pode ter valores anômalos resultantes de erros na coleta e no processamento dos dados. A seguir está um exemplo das amostras mais anômalas de acordo com a implementação do algoritmo de floresta de isolamento do Data Wrangler. Recomendamos usar o conhecimento do domínio e a lógica de negócios ao examinar as amostras anômalas.
O Data Wrangler detecta linhas duplicadas e calcula a proporção de linhas duplicadas em seus dados. Algumas fontes de dados podem incluir duplicatas válidas. Outras fontes de dados podem ter duplicatas que apontam para problemas na coleta de dados. Amostras duplicadas resultantes de uma coleta de dados incorreta podem interferir nos processos de machine learning que dependem da divisão dos dados em folds de treinamento e validação independentes.
A seguir estão os elementos do relatório de insights que podem ser impactados por amostras duplicadas:
-
Modelo rápido
-
Estimativa do poder de previsão
-
Ajuste automático de hiperparâmetros
Você pode remover amostras duplicadas do conjunto de dados usando a transformação Descartar duplicata em Gerenciar linhas. O Data Wrangler mostra as linhas duplicadas com mais frequência.
Definições
Estas são as definições dos termos técnicos usados no relatório de insights de dados.
