As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Transformar dados
O Amazon SageMaker Data Wrangler fornece várias transformações de dados de ML para agilizar a limpeza, a transformação e a caracterização de seus dados. Quando você adiciona uma transformação, ela adiciona uma etapa ao fluxo de dados. Cada transformação que você adiciona modifica seu conjunto de dados e gera um novo dataframe. Todas as transformações subsequentes se aplicam ao dataframe resultante.
O Data Wrangler inclui transformações embutidas, que você pode usar para transformar colunas sem a necessidade de código. Você também pode adicionar transformações personalizadas usando PySpark Python (função definida pelo usuário), pandas e SQL. PySpark Algumas transformações operam no local, enquanto outras criam uma nova coluna de saída no seu conjunto de dados.
Você pode aplicar transformações em várias colunas ao mesmo tempo. Por exemplo, você pode excluir várias colunas em uma única etapa.
Você pode aplicar o processo numérico e lidar com as transformações ausentes somente em uma única coluna.
Use esta página para saber mais sobre essas transformações integradas e personalizadas.
Interface de usuário da transformação
A maioria das transformações integradas está localizada na guia Preparar interface do usuário do Data Wrangler. Você pode acessar as transformações de união e concatenação através da visualização do fluxo de dados. Use a tabela a seguir para ter uma prévia dessas duas visualizações.



Unir conjuntos de dados
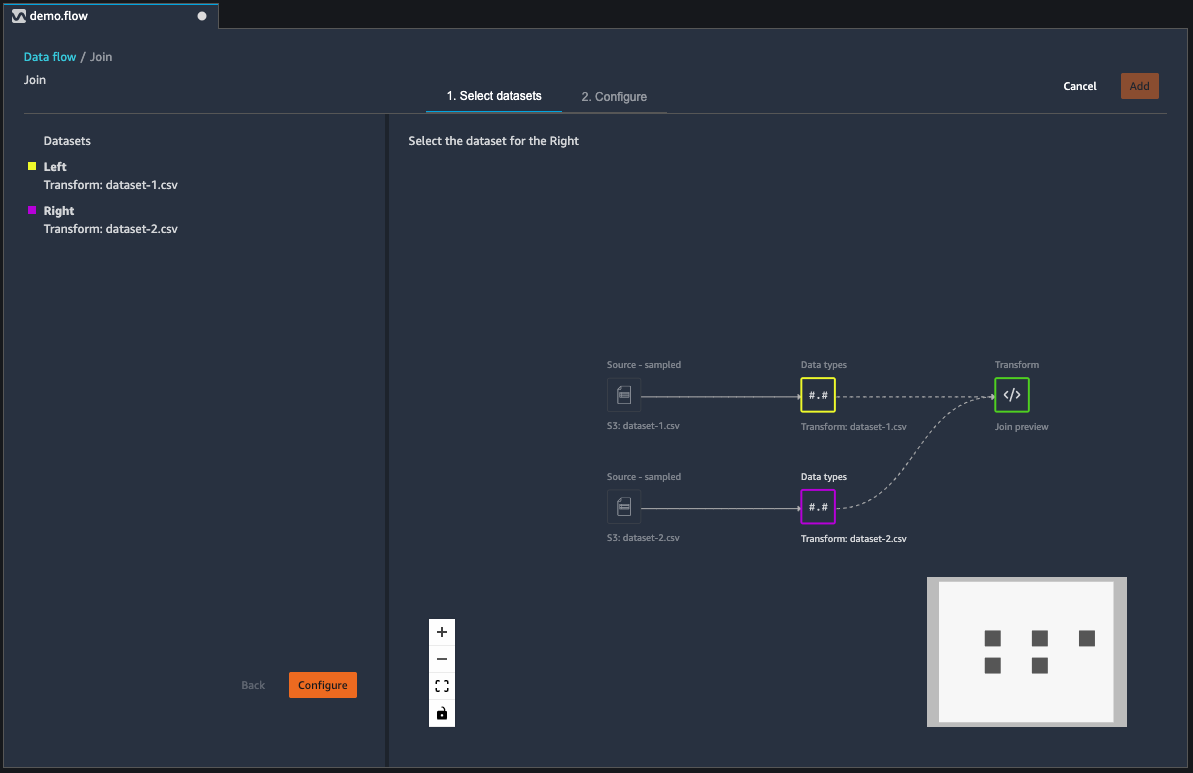
Você uni dataframes diretamente em seu fluxo de dados. Quando você associa dois conjuntos de dados, o conjunto resultante aparece no seu fluxo. Os seguintes tipos de união são compatíveis com o Data Wrangler:
-
Externo esquerdo - Inclua todas as linhas da tabela esquerda. Se o valor para a coluna na qual a associação foi feita em uma linha da tabela da esquerda não corresponder a nenhum valor nas linhas da tabela da direita, essa linha conterá valores nulos para todas as colunas da tabela da direita na tabela resultante.
-
Anti esquerdo: Inclui linhas da tabela à esquerda que não contêm valores na tabela à direita para a coluna unida.
-
Semi esquerda: Inclui uma única linha da tabela à esquerda para todas as linhas idênticas que atendem aos critérios na instrução de união. Isso exclui linhas duplicadas da tabela à esquerda que correspondam aos critérios da união.
-
Externo direito: Inclua todas as linhas da tabela à direita. Se o valor da coluna unida em uma linha direita da tabela não corresponder a nenhum valor da linha esquerda da tabela, essa linha conterá valores nulos para todas as colunas da tabela esquerda na tabela unida.
-
Interno - Inclua linhas das tabelas esquerda e direita que contêm valores correspondentes na coluna unida.
-
Exterior completo: Inclua todas as linhas das tabelas esquerda e direita. Se o valor da linha para a coluna de união em qualquer uma das tabelas não coincidir, linhas separadas são criadas na tabela resultante da união. Se uma linha não tiver um valor para uma coluna na tabela unida, será inserido um valor nulo para essa coluna.
-
Produto Cartesiano - Inclui as linhas que combinam cada linha da primeira tabela com cada linha da segunda tabela. Esse é um produto cartesiano
de linhas de tabelas na união. O resultado desse produto é o tamanho da tabela da esquerda multiplicado pelo tamanho da tabela da direita. Portanto, recomendamos cautela ao usar essa união entre conjuntos de dados muito grandes.
Use o procedimento a seguir para unir dois dataframes.
-
Selecione + ao lado do dataframe esquerdo que você deseja unir. O primeiro dataframe que você seleciona é sempre a tabela à esquerda em sua união.
-
Selecionar Unir.
-
Selecione o dataframe correto. O segundo dataframe que você seleciona é sempre a tabela à direita em sua união.
-
Escolha Configurar para configurar sua união.
-
Dê um nome ao conjunto de dados unido usando o campo Nome.
-
Selecione um Unir tipo.
-
Selecione uma coluna das tabelas esquerda e direita para unir.
-
Escolha Aplicar para visualizar o conjunto de dados unido à direita.
-
Para adicionar a tabela unida ao seu fluxo de dados, escolha Adicionar.
Concatenar conjuntos de dados
Concatenar dois conjuntos de dados:
-
Selecione + ao lado do dataframe esquerdo que você deseja unir. O primeiro dataframe que você seleciona é sempre a tabela à esquerda em sua união.
-
Escolha Concatenar.
-
Selecione o dataframe correto. O segundo dataframe que você seleciona é sempre a tabela à direita em sua união.
-
Escolha Configurar para configurar sua concatenação.
-
Dê um nome ao conjunto de dados unido usando o campo Nome.
-
(Opcional) Marque a caixa de seleção ao lado de Remover duplicatas após a concatenação para remover colunas duplicadas.
-
(Opcional) Marque a caixa de seleção ao lado de Adicionar coluna para indicar o dataframe de origem se, para cada coluna no novo conjunto de dados, você quiser adicionar um indicador da origem da coluna.
-
Escolha Aplicar para visualizar o novo conjunto de dados.
-
Escolha Adicionar para adicionar um novo conjunto de dados ao seu fluxo de dados.
Dados da balança
Você pode equilibrar os dados dos conjuntos de dados com uma categoria sub-representada. O balanceamento de um conjunto de dados pode ajudar você a criar modelos melhores para classificação binária.
nota
Você não pode balancear conjuntos de dados contendo vetores de coluna.
Você pode usar a operação Balancear dados para equilibrar seus dados usando um dos seguintes operadores:
-
Sobreamostragem aleatória: Duplica aleatoriamente amostras na categoria minoritária. Por exemplo, se você está tentando detectar fraudes, talvez só tenha casos de fraude em 10% dos seus dados. Para uma proporção igual de casos fraudulentos e não fraudulentos, esse operador duplica aleatoriamente os casos de fraude no conjunto de dados 8 vezes.
-
Subamostragem aleatória: Aproximadamente equivalente à sobreamostragem aleatória. Remove aleatoriamente amostras da categoria super-representada para obter a proporção de amostras desejada.
-
Técnica de Oversampling Sintético de Minorias (SMOTE): Usa amostras da categoria sub-representada para interpolar novas amostras sintéticas de minorias. Para obter mais informações sobre o SMOTE, consulte a descrição a seguir.
Você pode usar todas as transformações para conjuntos de dados contendo atributos numéricos e não numéricos. O SMOTE interpola valores usando amostras vizinhas. O Data Wrangler utiliza a distância R-quadrado para determinar o entorno no qual interpolar as amostras adicionais. O Data Wrangler usa somente atributos numéricos para calcular as distâncias entre amostras no grupo sub-representado.
Para dois exemplos reais no grupo sub-representado, o Data Wrangler interpola os atributos numéricos usando uma média ponderada. Ele atribui pesos aleatoriamente a essas amostras na faixa de [0, 1]. Para atributos numéricos, o Data Wrangler interpola amostras usando uma média ponderada das amostras. Para as amostras A e B, o Data Wrangler pode atribuir aleatoriamente um peso de 0,7 a A e 0,3 a B. A amostra interpolada tem um valor de 0,7A + 0,3B.
O Data Wrangler interpola atributos não numéricos copiando de qualquer uma das amostras reais interpoladas. Ele copia as amostras com uma probabilidade que é atribuída aleatoriamente a cada amostra. Para as amostras A e B, ele pode atribuir probabilidades de 0,8 a A e 0,2 a B. Para as probabilidades atribuídas, ele copia A 80% das vezes.
Transformações personalizadas
O grupo Transformações personalizadas permite que você use Python (função definida pelo usuário) PySpark, pandas PySpark ou (SQL) para definir transformações personalizadas. Para todas as três opções, você usa a variável df para acessar o dataframe ao qual deseja aplicar a transformação. Para aplicar seu código personalizado ao seu dataframe, atribua ao dataframe as transformações que você fez na variável df. Se você não estiver usando Python (função definida pelo usuário), você não precisará incluir uma instrução de retorno. Escolha Visualizar para visualizar o resultado da transformação personalizada. Escolha Adicionar para adicionar a transformação personalizada à sua lista de etapas anteriores.
Você pode importar as bibliotecas mais conhecidas com uma import instrução no bloco de código de transformação personalizado, como a seguinte:
-
NumPy versão 1.19.0
-
scikit-learn versão 0.23.2
-
SciPy versão 1.5.4
-
pandas versão 1.0.3
-
PySpark versão 3.0.0
Importante
A opção Personalizar transformação não é compatível com colunas com espaços ou caracteres especiais no nome. Recomendamos que você especifique nomes de colunas que tenham somente caracteres alfanuméricos e sublinhados. Você pode usar a transformação Renomear coluna no grupo Gerenciar transformação de colunas para remover espaços do nome de uma coluna. Você também pode adicionar uma transformação personalizada em Python (Pandas) semelhante à seguinte para remover espaços de várias colunas em uma única etapa: Este exemplo altera as colunas nomeadas A
column e B column para A_column e B_column respectivamente.
df.rename(columns={"A column": "A_column", "B column": "B_column"})
Se você incluir instruções de impressão no bloco de código, o resultado será exibido quando você selecionar Visualizar. Você pode redimensionar o painel do transformador de código personalizado. O redimensionamento do painel fornece mais espaço para escrever código. A seguinte imagem mostra o redimensionamento do painel:
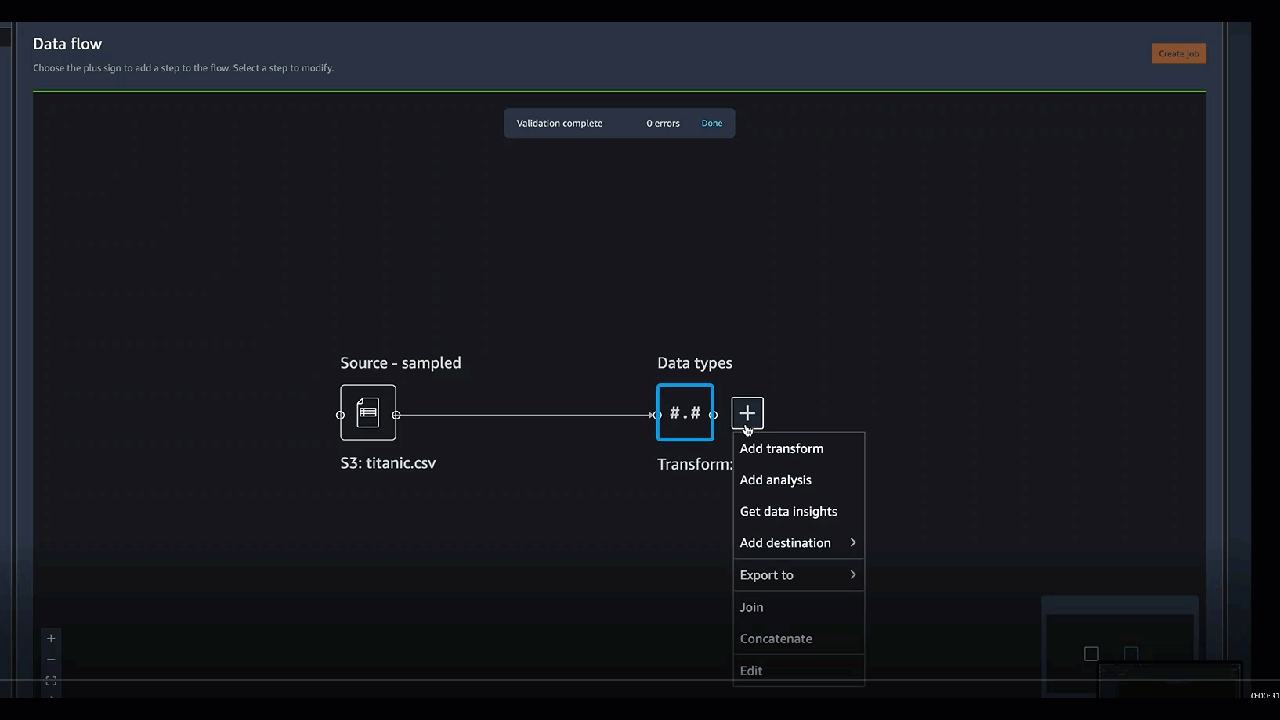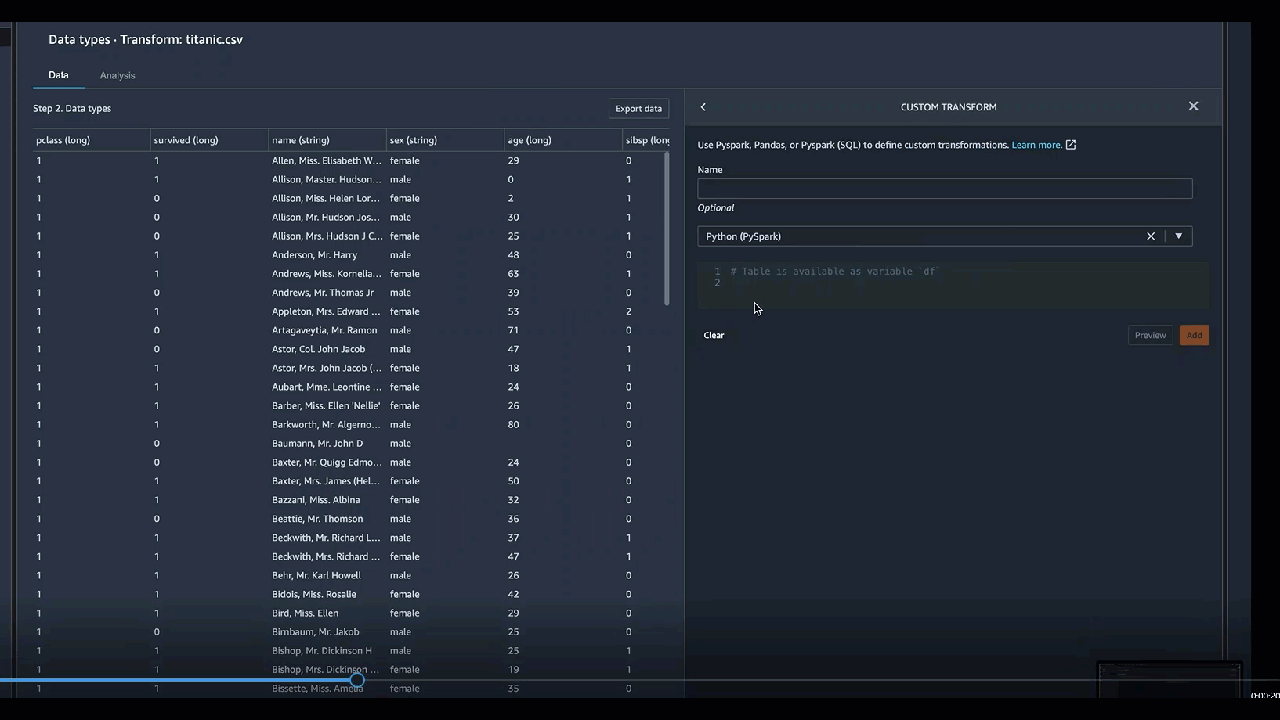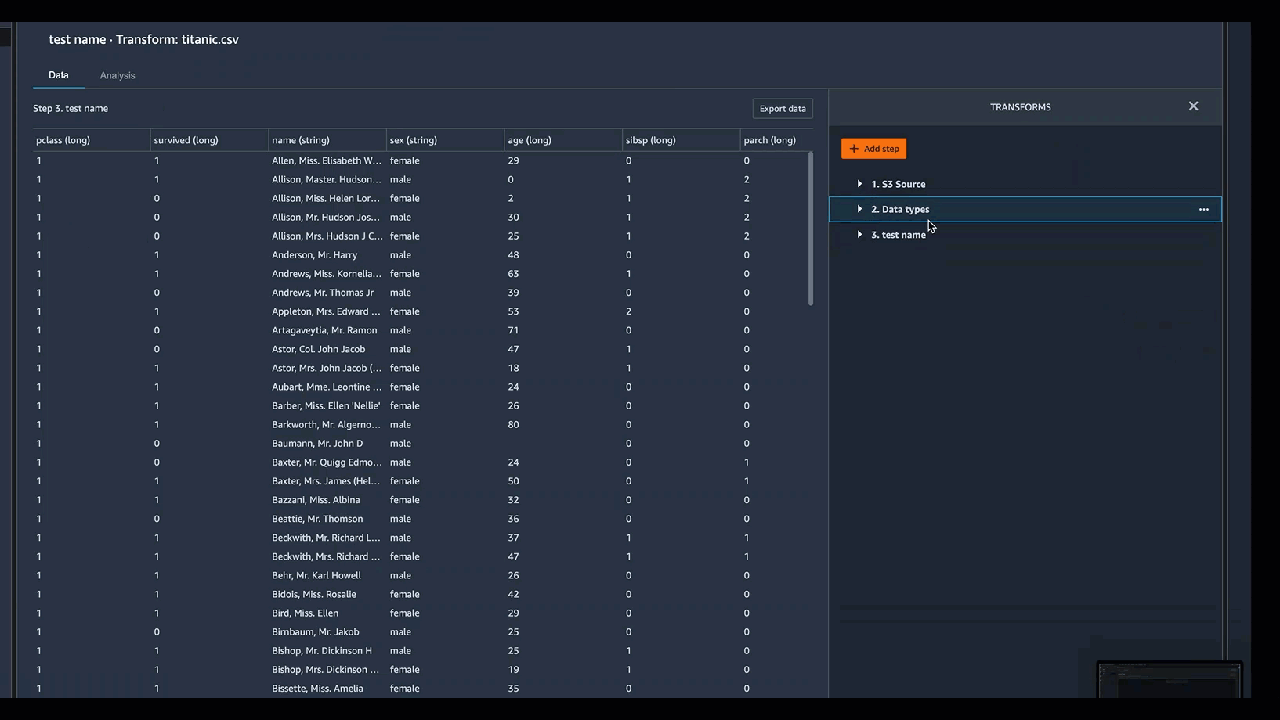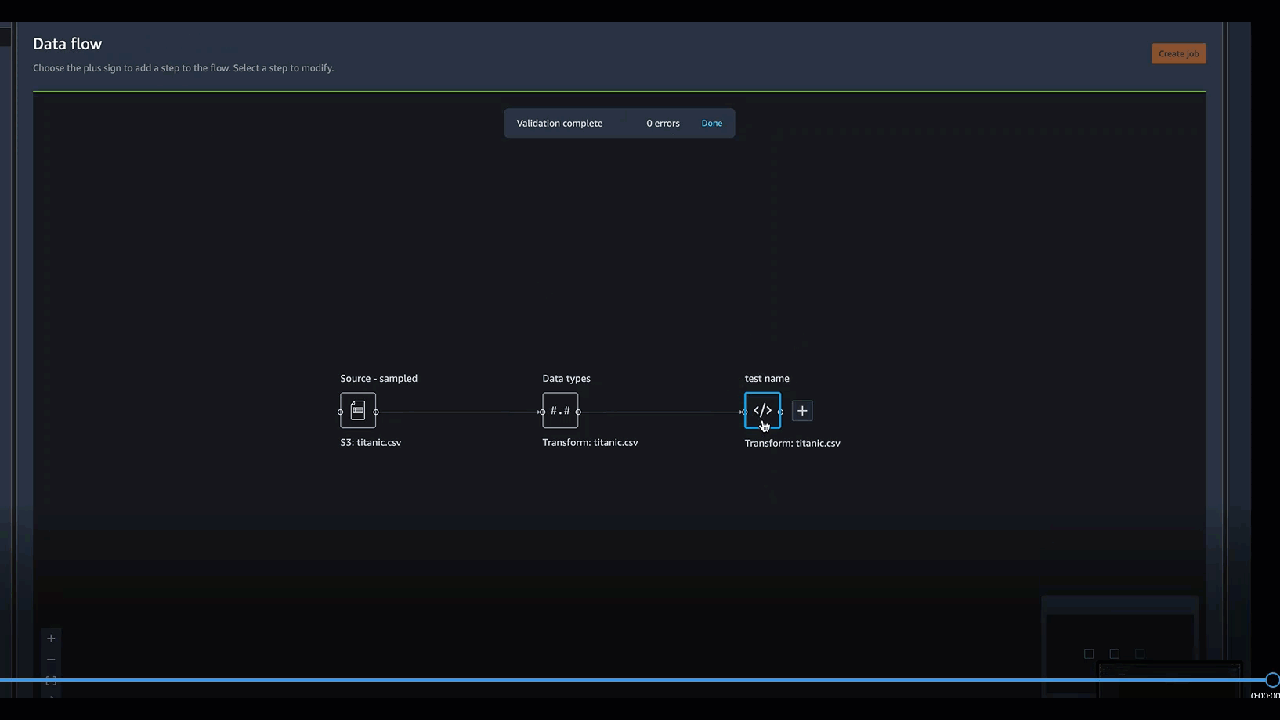
As seções a seguir fornecem contexto adicional e exemplos para escrever código de transformação personalizado.
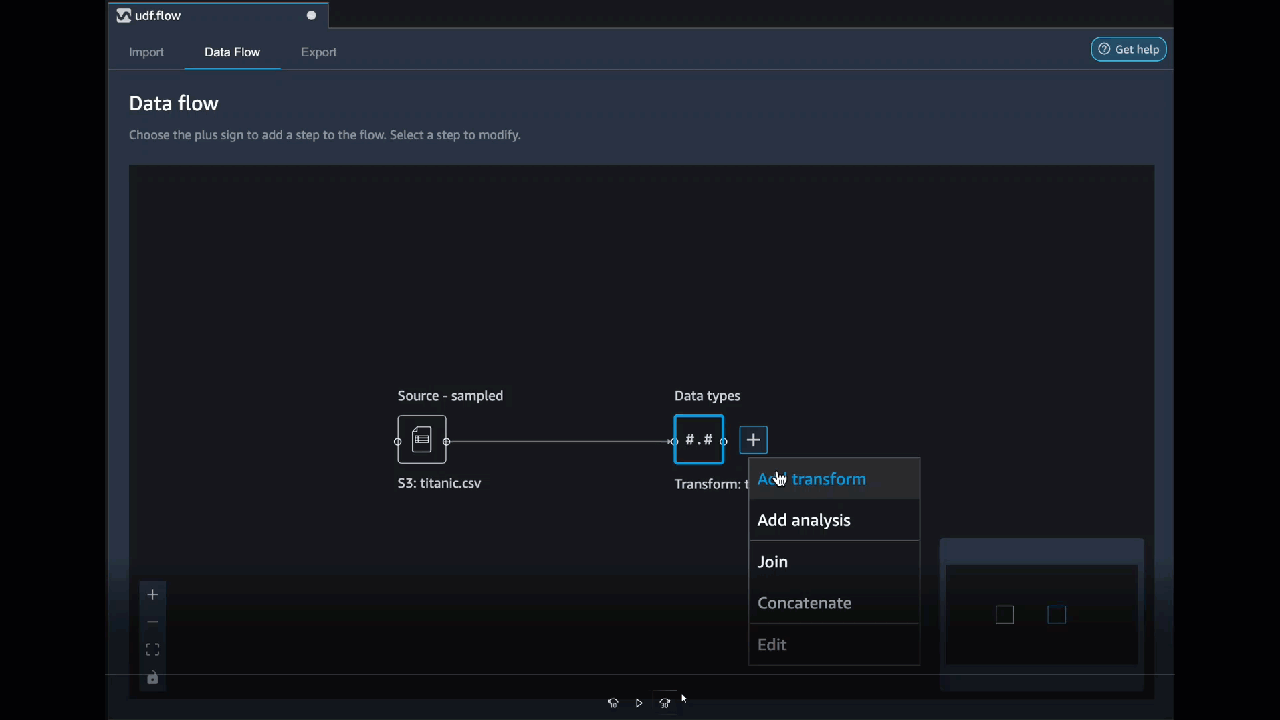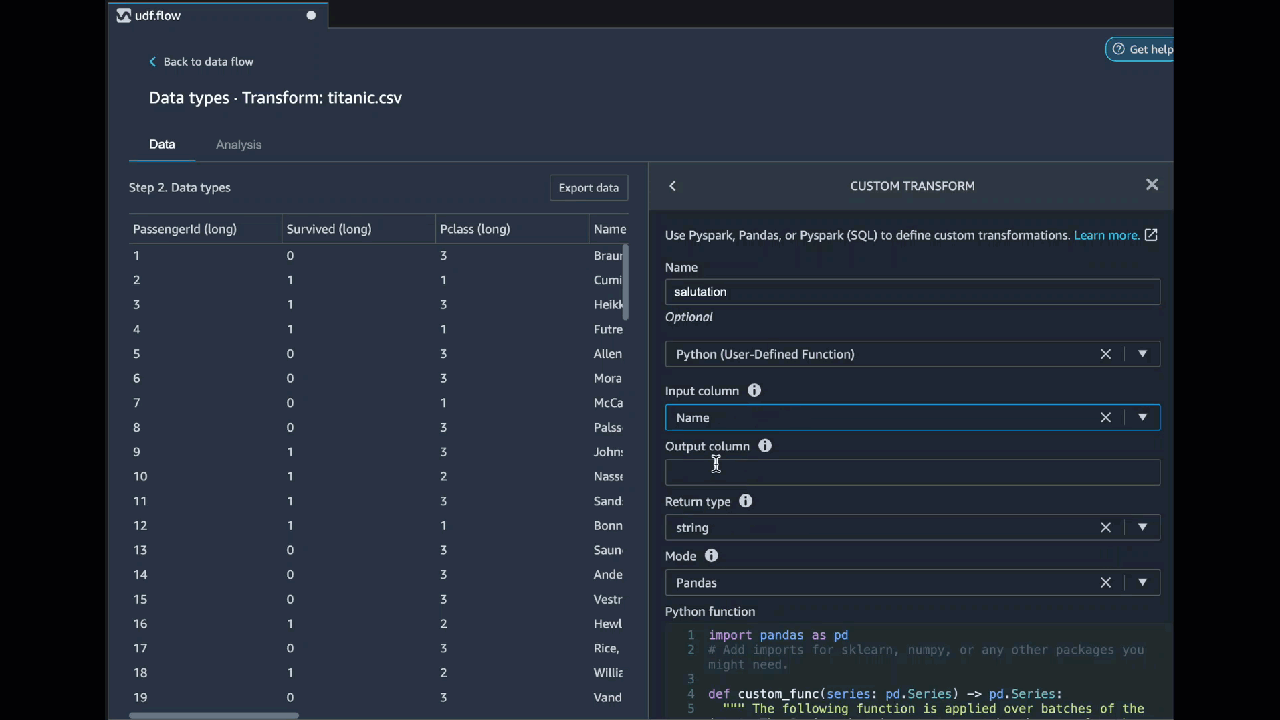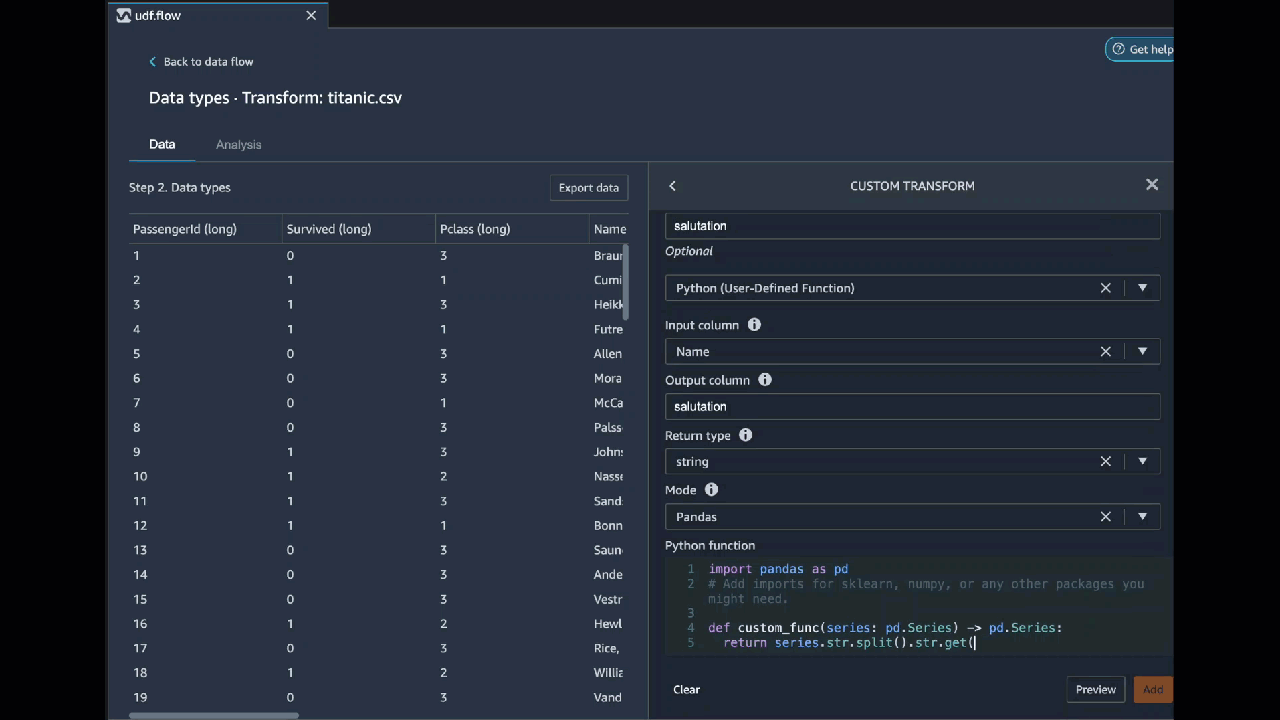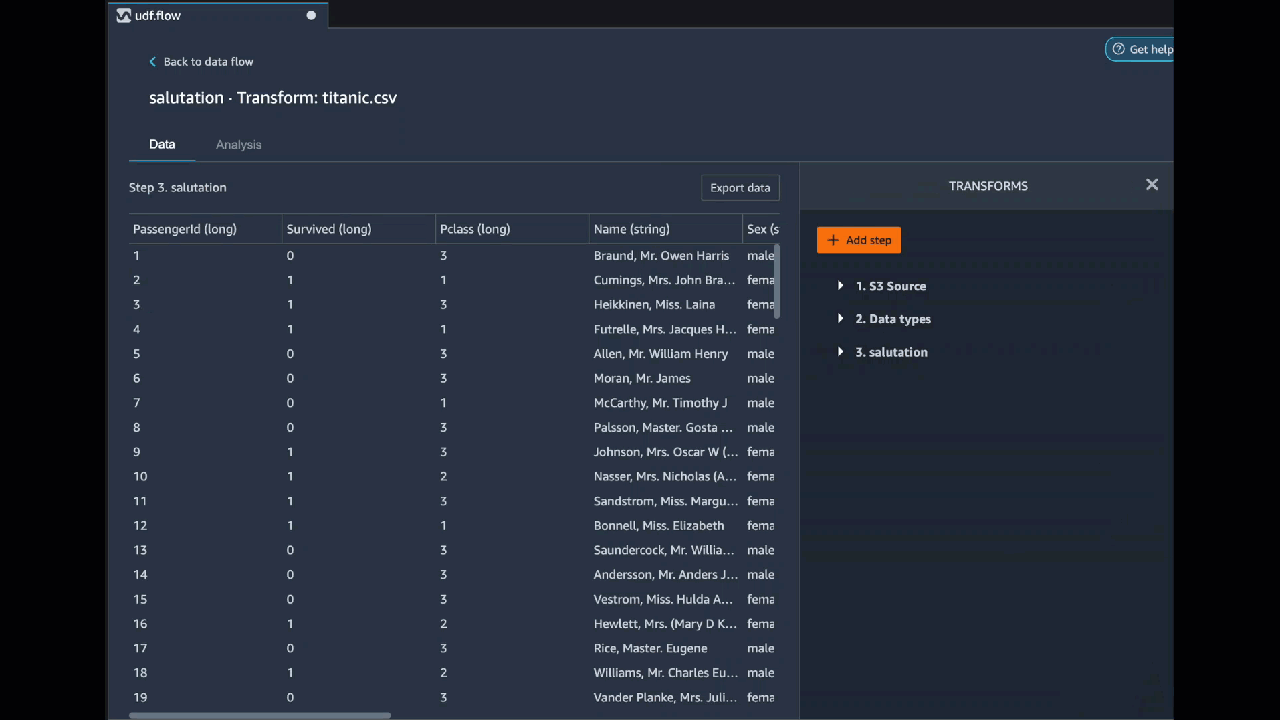
Python (função definida pelo usuário)
A função Python oferece a capacidade de escrever transformações personalizadas sem precisar conhecer o Apache Spark ou os pandas. O Data Wrangler é otimizado para executar seu código personalizado rapidamente. Você obtém desempenho semelhante usando código Python personalizado e um plug-in Apache Spark.
Para usar o bloco de código Python (função definida pelo usuário), você especifica o seguinte:
-
Coluna de entrada: A coluna de entrada na qual você está aplicando a transformação.
-
Modo: O modo de script, pandas ou Python.
-
Tipo de retorno: O tipo de dados do valor que você está retornando.
Usar o modo pandas oferece melhor desempenho. O modo Python facilita a escrita de transformações ao permitir o uso de funções puramente em Python.
O vídeo a seguir mostra um exemplo de como usar código personalizado para criar uma transformação. Ele usa o conjunto de dados do Titanic
PySpark
O exemplo a seguir extrai data e hora de um timestamp.
from pyspark.sql.functions import from_unixtime, to_date, date_format df = df.withColumn('DATE_TIME', from_unixtime('TIMESTAMP')) df = df.withColumn( 'EVENT_DATE', to_date('DATE_TIME')).withColumn( 'EVENT_TIME', date_format('DATE_TIME', 'HH:mm:ss'))
pandas
O exemplo a seguir fornece uma visão geral do dataframe ao qual você está adicionando transformações.
df.info()
PySpark (SQL)
O seguinte exemplo cria um novo dataframe com quatro colunas: nome, tarifa, classe, sobreviveu.
SELECT name, fare, pclass, survived FROM df
Se você não sabe como usar PySpark, pode usar trechos de código personalizados para ajudar você a começar.
O Data Wrangler tem uma coleção que pode ser pesquisada de trechos de código. Você pode usar trechos de código para realizar tarefas como descartar colunas, agrupar por colunas ou modelar.
Para usar um trecho de código, escolha Pesquisar trechos de exemplo e especifique uma consulta na barra de pesquisa. O texto especificado na consulta não precisa corresponder exatamente ao nome do trecho de código.
O exemplo a seguir mostra um trecho de código Excluir linhas duplicadas que pode excluir linhas com dados semelhantes no seu conjunto de dados. Você pode encontrar o trecho de código pesquisando uma das seguintes opções:
-
Duplica
-
Idêntico
-
Remover
O trecho a seguir tem comentários para ajudar você a entender as alterações que você precisa fazer. Para a maioria dos trechos, você deve especificar os nomes das colunas do seu conjunto de dados no código.
# Specify the subset of columns # all rows having identical values in these columns will be dropped subset = ["col1", "col2", "col3"] df = df.dropDuplicates(subset) # to drop the full-duplicate rows run # df = df.dropDuplicates()
Para usar um trecho, copie e cole seu conteúdo no campo Transformação personalizada. Você pode copiar e colar vários trechos de código no campo de transformação personalizado.
Personalizar fórmula
Use a opção Personalizar fórmula para definir uma nova coluna usando uma expressão do Spark SQL para consultar dados no dataframe atual. A consulta deve usar as convenções das expressões SQL do Spark.
Importante
A opção Personalizar transformação não é compatível com colunas com espaços ou caracteres especiais no nome. Recomendamos que você especifique nomes de colunas que tenham somente caracteres alfanuméricos e sublinhados. Você pode usar a transformação Renomear coluna no grupo Gerenciar transformação de colunas para remover espaços do nome de uma coluna. Você também pode adicionar uma transformação personalizada em Python (Pandas) semelhante à seguinte para remover espaços de várias colunas em uma única etapa: Este exemplo altera as colunas nomeadas A
column e B column para A_column e B_column respectivamente.
df.rename(columns={"A column": "A_column", "B column": "B_column"})
Você pode usar essa transformação para realizar operações em colunas, referenciando as colunas pelo nome. Por exemplo, supondo que o dataframe atual contenha colunas chamadas col_a e col_b, você pode usar a operação a seguir para produzir uma coluna de saída que seja o produto dessas duas colunas com o código a seguir:
col_a * col_b
Outras operações comuns incluem as seguintes, supondo que um dataframe contenha col_a colunas: col_b
-
Concatene duas colunas:
concat(col_a, col_b) -
Adicione duas colunas:
col_a + col_b -
Subtraia duas colunas:
col_a - col_b -
Divida duas colunas:
col_a / col_b -
Pegue o valor absoluto de uma coluna:
abs(col_a)
Para obter mais informações, consulte a documentação do Spark
Reduza a dimensionalidade em um conjunto de dados
Reduza a dimensionalidade em seus dados usando a Análise de Componentes Principais (PCA). A dimensionalidade do seu conjunto de dados corresponde ao número de atributos. Ao usar a redução de dimensionalidade no Data Wrangler, você obtém um novo conjunto de atributos chamados componentes. Cada componente é responsável por alguma variabilidade nos dados.
O primeiro componente é responsável pela maior quantidade de variação nos dados. O segundo componente é responsável pela segunda maior variação nos dados e assim por diante.
Você pode usar a redução de dimensionalidade para diminuir o tamanho dos conjuntos de dados usados para treinar modelos. Em vez de usar os atributos do seu conjunto de dados, você pode usar os componentes principais.
Para realizar o PCA, o Data Wrangler cria eixos para seus dados. Um eixo é uma combinação afim de colunas no seu conjunto de dados. O primeiro componente principal é o valor no eixo que tem a maior quantidade de variância. O segundo componente principal é o valor no eixo que possui a segunda maior quantidade de variação. O enésimo componente principal é o valor no eixo que possui a enésima maior quantidade de variação.
Você pode configurar o número de componentes principais que o Data Wrangler retorna. Você pode especificar diretamente o número de componentes principais ou especificar a porcentagem do limite de variação. Cada componente principal explica uma quantidade de variação nos dados. Por exemplo, você pode ter um componente principal com um valor de 0,5. O componente explicaria 50% da variação nos dados. Quando você especifica uma porcentagem de limite de variação, o Data Wrangler retorna o menor número de componentes que atendem à porcentagem especificada.
A seguir estão exemplos de componentes principais com a quantidade de variação que eles explicam nos dados.
-
Componente 1: 0,5
-
Componente 2: 0,45
-
Componente 3: 0,05
Se você especificar uma porcentagem de limite de variação de 94 ou 95, o Data Wrangler retornará o Componente 1 e o Componente 2. Se você especificar uma porcentagem de limite de variação de 96, o Data Wrangler retornará todos os três componentes principais.
É possível usar o procedimento a seguir para executar o PCA em seu conjunto de dados.
Para executar o PCA em seu conjunto de dados, faça o seguinte:
-
Abra seu fluxo de dados do Data Wrangler.
-
Escolha o + e selecione Adicionar transformação.
-
Escolha Adicionar etapa.
-
Escolha Redução de Dimensionalidade.
-
Em Colunas de entrada, escolha os atributos que você está reduzindo aos componentes principais.
-
(Opcional) Em Número de componentes principais, escolha o número de componentes principais que o Data Wrangler retorna em seu conjunto de dados. Se especificar um valor para o campo, você não poderá especificar um valor para a porcentagem do limite de variação.
-
(Opcional) Para Porcentagem do limite de variação, especifique a porcentagem de variação nos dados que você deseja explicar pelos componentes principais. O Data Wrangler usará o valor padrão de
95se você não especificar um valor para o limite de variância. Você não pode especificar uma porcentagem de limite de variação se tiver especificado um valor para Número de componentes principais. -
(Opcional) Desmarque a opção Centralizar para não usar a média das colunas como centro dos dados. Por padrão, o Data Wrangler centraliza os dados com a média antes do escalonamento.
-
(Opcional) Desmarque a opção Escalar para não dimensionar os dados com o desvio padrão da unidade.
-
(Opcional) Escolha Colunas para produzir os componentes em colunas separadas. Escolha Vetor para gerar os componentes como um único vetor.
-
(Opcional) Em Coluna de saída, especifique um nome para uma coluna de saída. Se você estiver enviando os componentes em colunas separadas, o nome especificado será um prefixo. Se você estiver enviando os componentes para um vetor, o nome especificado será o nome da coluna vetorial.
-
(Opcional) Selecione Manter colunas de entrada. Não recomendamos selecionar essa opção se você planeja usar apenas os componentes principais para treinar seu modelo.
-
Escolha Pré-visualizar.
-
Escolha Adicionar.
Codificar categórico
Os dados categóricos geralmente são compostos por um número finito de categorias, onde cada categoria é representada por um segmento. Por exemplo, se você tiver uma tabela de dados de clientes, uma coluna que indica o país em que a pessoa mora é categórica. As categorias seriam Afeganistão, Albânia, Argélia e assim por diante. Os dados categóricos podem ser nominais ou ordinais. As categorias ordinais têm uma ordem inerente e as categorias nominais não. O grau mais alto obtido (ensino médio, bacharelado, mestrado, etc.) é um exemplo de categorias ordinais.
A codificação de dados categóricos é o processo de criação de uma representação numérica para categorias. Por exemplo, se suas categorias são Cachorro e Gato, você pode codificar essas informações em dois vetores, [1,0] para representar Cachorro e [0,1] para representar Gato.
Ao codificar categorias ordinais, talvez seja necessário traduzir a ordem natural das categorias em sua codificação. Por exemplo, você pode representar o grau mais alto obtido com o seguinte mapa: {"High school": 1, "Bachelors": 2,
"Masters":3}.
Use codificação categórica para codificar dados categóricos que estão no formato de segmento em matrizes de números inteiros.
Os codificadores categóricos do Data Wrangler criam codificações para todas as categorias que existem em uma coluna no momento em que a etapa é definida. Se novas categorias foram adicionadas a uma coluna quando você inicia uma tarefa do Data Wrangler para processar seu conjunto de dados no momento t, e essa coluna foi a entrada para uma transformação da codificação categórica do Data Wrangler no momento t-1, essas novas categorias serão consideradas ausentes na tarefa do Data Wrangler. A opção selecionada para Estratégia de tratamento inválida é aplicada a esses valores ausentes. Exemplos de quando isso pode ocorrer são:
-
Quando você usa um arquivo.flow para criar uma tarefa do Data Wrangler para processar um conjunto de dados que foi atualizado após a criação do fluxo de dados. Por exemplo, você pode usar um fluxo de dados para processar regularmente os dados de vendas a cada mês. Se esses dados de vendas forem atualizados semanalmente, novas categorias poderão ser introduzidas em colunas para as quais uma etapa categórica de codificação é definida.
-
Quando você seleciona Amostragem ao importar seu conjunto de dados, algumas categorias podem ser deixadas de fora da amostra.
Nessas situações, essas novas categorias são consideradas valores ausentes no trabalho do Data Wrangler.
Você pode escolher e configurar uma codificação ordinal e uma codificação única. Use as seguintes seções para saber mais sobre essas opções:
Ambas as transformações criam uma nova coluna chamada Nome da coluna de saída. Você especifica o formato de saída dessa coluna com o estilo de saída:
-
Selecione Vetor para produzir uma única coluna com um vetor esparso.
-
Selecione Colunas para criar uma coluna para cada categoria com uma variável indicadora para determinar se o texto na coluna original contém um valor igual a essa categoria.
Codificação ordinal
Selecione Codificação ordinal para codificar categorias em um número inteiro entre 0 e o número total de categorias na coluna de entrada selecionada.
Estratégia de tratamento inválida: selecione um método para lidar com valores inválidos ou ausentes.
-
Escolha Ignorar se quiser omitir as linhas com valores ausentes.
-
Escolha Manter para reter os valores ausentes como a última categoria.
-
Escolha Erro se quiser que o Data Wrangler gere um erro se forem encontrados valores ausentes na coluna de entrada.
-
Escolha Substituir por NaN para substituir o ausente por NaN. Essa opção é recomendada se seu algoritmo de ML puder processar valores ausentes. Caso contrário, as três primeiras opções dessa lista podem produzir melhores resultados.
Codificação One-Hot
Selecione Codificação única para Transformar para usar a codificação única. Configure essa transformação usando o seguinte:
-
Eliminar a última categoria: se
Truea última categoria não tiver um índice correspondente na codificação one-hot. Quando valores ausentes são possíveis, uma categoria ausente é sempre a última e definir issoTruesignifica que um valor ausente resulta em um vetor totalmente zero. -
Estratégia de tratamento inválida: selecione um método para lidar com valores inválidos ou ausentes.
-
Escolha Ignorar se quiser omitir as linhas com valores ausentes.
-
Escolha Manter para reter os valores ausentes como a última categoria.
-
Escolha Erro se quiser que o Data Wrangler gere um erro se forem encontrados valores ausentes na coluna de entrada.
-
-
A entrada é codificada ordinalmente: selecione essa opção se o vetor de entrada contiver dados codificados ordinais. Essa opção exige que os dados de entrada contenham números inteiros não negativos. Se Verdadeiro, a entrada i é codificada como um vetor com um valor diferente de zero no local i.
Codificação de similaridade
Use a codificação de similaridade quando você tiver o seguinte:
-
Um grande número de variáveis categóricas
-
Dados ruidosos
O codificador de similaridade cria incorporações para colunas com dados categóricos. Uma incorporação é uma correspondência de objetos discretos, como palavras, para vetores de números reais. Codifica segmentos semelhantes em vetores contendo valores semelhantes. Por exemplo, ele cria codificações muito semelhantes para “California” e “Calfornia”.
O Data Wrangler converte cada categoria em seu conjunto de dados em um conjunto de tokens usando um tokenizador de 3 gramas. Ele converte os tokens em uma incorporação usando a codificação min-hash.
O exemplo a seguir mostra como o codificador de similaridade cria vetores a partir de segmentos.
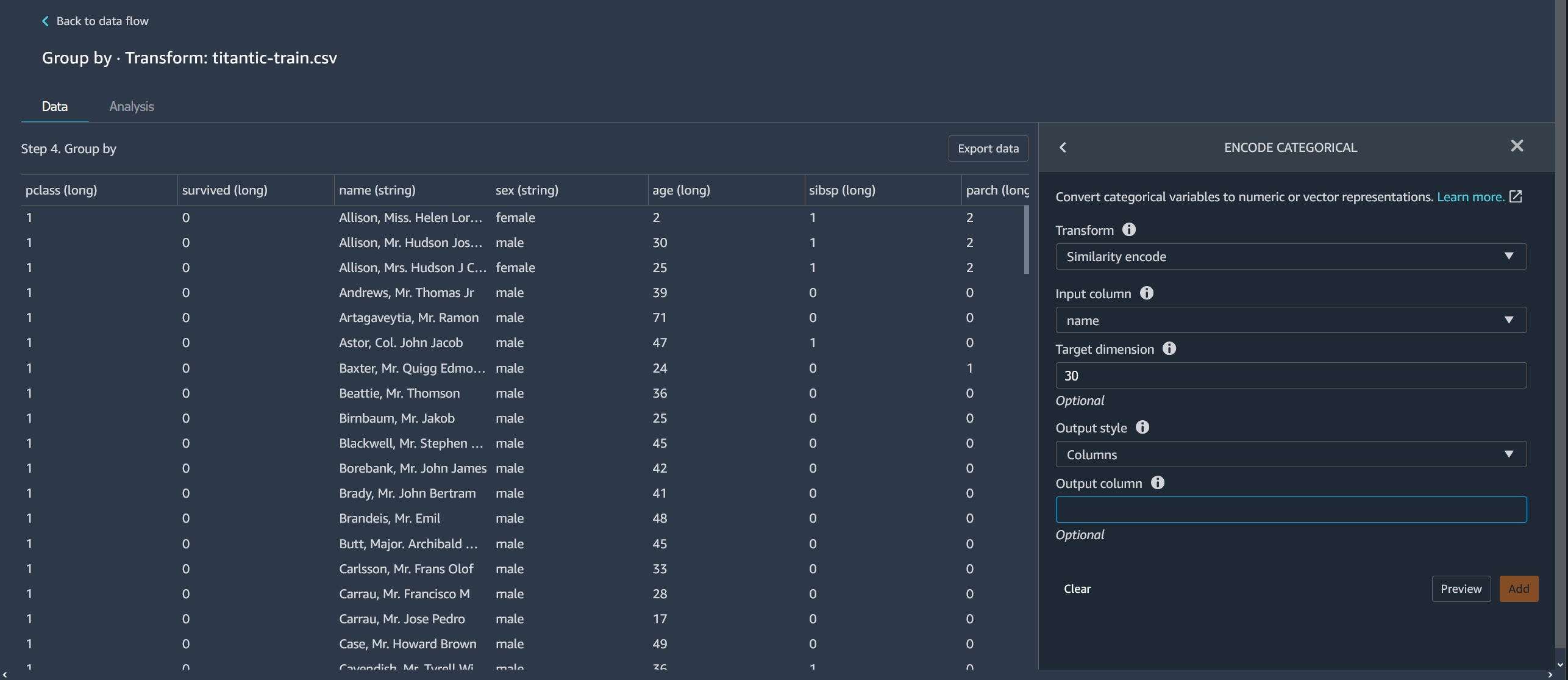

As codificações de similaridade que o Data Wrangler cria:
-
Têm baixa dimensionalidade
-
São escaláveis para um grande número de categorias
-
São robustos e resistentes ao ruído
Pelas razões anteriores, a codificação por similaridade é mais versátil do que a codificação one-hot.
Para adicionar a transformação de codificação de similaridade ao seu conjunto de dados, use o procedimento a seguir.
Para usar a codificação de similaridade, faça o seguinte:
-
Faça login no Amazon SageMaker AI Console
. -
Escolha Abrir Studio Classic.
-
Escolha Iniciar aplicação.
-
Escolha Studio.
-
Especifique seu fluxo de dados.
-
Escolha uma etapa com uma transformação.
-
Escolha Adicionar etapa.
-
Escolha Codificar categórico.
-
Especifique o seguinte:
-
Transformação: Codificação por similaridade
-
Coluna de entrada: A coluna que contém os dados categóricos que você está codificando.
-
Dimensão de destino: (Opcional) A dimensão do vetor de incorporação categórica. O valor padrão é 30. Recomendamos usar uma dimensão alvo maior se você tiver um grande conjunto de dados com muitas categorias.
-
Estilo de saída: Escolha Vetor para um único vetor com todos os valores codificados. Escolha Coluna para ter os valores codificados em colunas separadas.
-
Coluna de saída: (Opcional) O nome da coluna de saída para uma saída codificada em vetor. Para uma saída codificada em coluna, esse é o prefixo dos nomes das colunas seguido pelo número listado.
-
Caracterizar texto
Use o grupo de transformação Caracterizar texto para inspecionar colunas digitadas por segmento e use a incorporação de texto para destacar essas colunas.
Esse grupo de atributos contém dois atributos, estatísticas de caracteres e vetorização. Use as seções a seguir para saber mais sobre essas transformações. Para ambas as opções, a coluna de entrada deve conter dados de texto (tipo segmento).
Estatísticas de personagens
Use estatísticas de caracteres para gerar estatísticas para cada linha em uma coluna contendo dados de texto.
Essa transformação calcula as seguintes proporções e contagens para cada linha e cria uma nova coluna para relatar o resultado: A nova coluna é nomeada usando o nome da coluna de entrada como um prefixo e um sufixo específico da proporção ou contagem.
-
Número de palavras: o número total de palavras nessa linha. O sufixo dessa coluna de saída é
-stats_word_count. -
Número de caracteres: o número total de caracteres nessa linha. O sufixo dessa coluna de saída é
-stats_char_count. -
Proporção maior: o número de caracteres maiúsculos, de A a Z, dividido por todos os caracteres na coluna. O sufixo dessa coluna de saída é
-stats_capital_ratio. -
Proporção menor: o número de caracteres minúsculos, de a a z, dividido por todos os caracteres da coluna. O sufixo dessa coluna de saída é
-stats_lower_ratio. -
Proporção de dígitos: A proporção de dígitos em uma única linha sobre a soma dos dígitos na coluna de entrada. O sufixo dessa coluna de saída é
-stats_digit_ratio. -
Proporção de caracteres especiais: a proporção de caracteres não alfanuméricos (como #$&%:@) em relação à soma de todos os caracteres na coluna de entrada. O sufixo dessa coluna de saída é
-stats_special_ratio.
Vetorizar
A incorporação de texto envolve o mapeamento de palavras ou frases de um vocabulário para vetores de números reais. Use a transformação de incorporação de texto do Data Wrangler para tokenizar e vetorizar dados de texto em vetores de frequência de documento inversa de frequência de termo (TF-IDF).
Quando o TF-IDF é calculado para uma coluna de dados de texto, cada palavra de cada frase é convertida em um número real que representa sua importância semântica. Números mais altos estão associados a palavras menos frequentes, que tendem a ser mais significativas.
Quando você define uma etapa de transformação Vetorizar, o Data Wrangler usa os dados em seu conjunto de dados para definir o vetorizador de contagem e os métodos TF-IDF. A execução de um trabalho do Data Wrangler usa esses mesmos métodos.
Você configura essa transformação usando o seguinte:
-
Nome da coluna de saída: essa transformação cria uma nova coluna com a incorporação do texto. Use esse campo para especificar um nome para essa coluna de saída.
-
Tokenizador: um tokenizador converte a frase em uma lista de palavras ou tokens.
Escolha Padrão para usar um tokenizador que divide por espaço em branco e converte cada palavra em minúsculas. Por exemplo,
"Good dog"é tokenizado para["good","dog"].Escolha Personalizar para usar um tokenizador personalizado. Se você escolher Personalizar, poderá usar os seguintes campos para configurar o tokenizador:
-
Tamanho mínimo do token: o tamanho mínimo, em caracteres, para que um token seja válido. O padrão é
1. Por exemplo, se você especificar3o tamanho mínimo do token, palavras comoa, at, insão retiradas da frase tokenizada. -
O regex deve ser dividido em lacunas: Se selecionado, o regex divide em lacunas. Caso contrário, ele corresponderá aos tokens. O padrão é
True. -
Padrão Regex: o padrão que define o processo de tokenização. O padrão é
' \\ s+'. -
Para minúsculas: se escolhido, o Data Wrangler converte todos os caracteres em minúsculas antes da tokenização. O padrão é
True.
Para saber mais, consulte a documentação do Spark sobre o Tokenizer
. -
-
Vetorizador: o vetorizador converte a lista de tokens em um vetor numérico esparso. Cada token corresponde a um índice no vetor e um valor diferente de zero indica a existência do token na frase de entrada. Você pode escolher entre duas opções de vetorização, Count e Hashing.
-
A vetorização de contagem permite personalizações que filtram tokens pouco frequentes ou muito comuns. Os parâmetros de vetorização de contagem incluem o seguinte:
-
Frequência mínima do termo: em cada linha, os termos (tokens) com menor frequência são filtrados. Se você especificar um número inteiro, este será um limite absoluto (inclusivo). Se você especificar uma fração entre 0 (inclusive) e 1, o limite será relativo à contagem total de termos. O padrão é
1. -
Frequência mínima do documento: número mínimo de linhas nas quais um termo (token) deve aparecer para ser incluído. Se você especificar um número inteiro, este será um limite absoluto (inclusivo). Se você especificar uma fração entre 0 (inclusive) e 1, o limite será relativo à contagem total de termos. O padrão é
1. -
Frequência máxima de documentos: Número máximo de documentos (linhas) nos quais um termo (token) pode aparecer incluído. Se você especificar um número inteiro, este será um limite absoluto (inclusivo). Se você especificar uma fração entre 0 (inclusive) e 1, o limite será relativo à contagem total de termos. O padrão é
0.999. -
Tamanho máximo do vocabulário: tamanho máximo do vocabulário. O vocabulário é composto por todos os termos (tokens) em todas as linhas da coluna. O padrão é
262144. -
Saídas binárias: se selecionadas, as saídas vetoriais não incluem o número de aparições de um termo em um documento, mas são um indicador binário de sua aparência. O padrão é
False.
Para saber mais sobre essa opção, consulte a documentação do Spark em CountVectorizer
. -
-
O hashing é computacionalmente mais rápido. Os parâmetros de vetorização de hashing incluem o seguinte:
-
Número de atributos durante o hash: um vetorizador de hash mapeia tokens para um índice vetorial de acordo com seu valor de hash. Esse atributo determina o número de valores de hash possíveis. Valores grandes resultam em menos colisões entre valores de hash, mas em um vetor de saída de maior dimensão.
Para saber mais sobre essa opção, consulte a documentação do Spark em FeatureHasher
-
-
-
O Apply IDF aplica uma transformação IDF, que multiplica a frequência do termo pela frequência inversa padrão do documento usada para incorporação TF-IDF. Os parâmetros IDF incluem o seguinte:
-
Frequência mínima do documento: número mínimo de documentos (linhas) nos quais um termo (token) deve aparecer para ser incluído. Se count_vectorize for o vetorizador escolhido, recomendamos que você mantenha o valor padrão e modifique somente o campo min_doc_freq nos parâmetros de vetorização de contagem. O padrão é
5.
-
-
Formato de saída: o formato de saída de cada linha.
-
Selecione Vetor para produzir uma única coluna com um vetor esparso.
-
Selecione Nivelado para criar uma coluna para cada categoria com uma variável indicadora para saber se o texto na coluna original contém um valor igual a essa categoria. Você só pode escolher achatado quando Vetorizador é definido como vetorizador de contagem.
-
Séries temporais de transformações
No Data Wrangler, você pode transformar dados de séries temporais. Os valores em um conjunto de dados de série temporal são indexados em um horário específico. Por exemplo, um conjunto de dados que mostra o número de clientes em uma loja para cada hora do dia é um conjunto de dados de séries temporais. A tabela a seguir mostra um exemplo de um conjunto de dados de séries temporais.
Número horário de clientes em uma loja
| Número de clientes | Hora (hora) |
|---|---|
| 4 | 09:00 |
| 10 | 10:00 |
| 14 | 11:00 |
| 25 | 12:00 |
| 20 | 13:00 |
| 18 | 14:00 |
Para a tabela anterior, a coluna Número de clientes contém os dados de séries temporais. Os dados da série temporal são indexados nos dados horários na coluna Tempo (hora).
Talvez seja necessário realizar uma série de transformações em seus dados para obtê-los em um formato que possa ser usado em sua análise. Use o grupo de transformação de séries temporais para transformar seus dados de séries temporais. Para obter mais informações sobre as transformações que você pode executar, consulte as seções a seguir.
Tópicos
Agrupar por uma série temporal
Você pode usar a operação agrupar por para agrupar dados de séries temporais para valores específicos em uma coluna.
Por exemplo, você tem a tabela a seguir que monitora o uso médio diário de eletricidade em uma residência.
Uso médio diário de eletricidade doméstica
| ID da residência | Timestamp diário | Uso de eletricidade (kWh) | Número de ocupantes da residência |
|---|---|---|---|
| household_0 | 1/1/2020 | 30 | 2 |
| household_0 | 1/2/2020 | 40 | 2 |
| household_0 | 1/4/2020 | 35 | 3 |
| household_1 | 1/2/2020 | 45 | 3 |
| household_1 | 1/3/2020 | 55 | 4 |
Se optar por agrupar por ID, você obterá a tabela a seguir.
Uso de eletricidade agrupado por identificação residencial
| ID da residência | Série de uso de eletricidade (kWh) | Série do número de ocupantes da residência |
|---|---|---|
| household_0 | [30, 40, 35] | [2, 2, 3] |
| household_1 | [45, 55] | [3, 4] |
Cada entrada na sequência da série temporal é ordenada pelo timestamp correspondente. O primeiro elemento da sequência corresponde ao primeiro timestamp da série. Para household_0, 30 é o primeiro valor da Série de uso de eletricidade. O valor de 30 corresponde ao primeiro timestamp de 1/1/2020.
Você pode incluir o timestamp inicial e o timestamp final. A tabela a seguir mostra como essas informações aparecem.
Uso de eletricidade agrupado por identificação residencial
| ID da residência | Série de uso de eletricidade (kWh) | Série do número de ocupantes da residência | Start_time | End_time |
|---|---|---|---|---|
| household_0 | [30, 40, 35] | [2, 2, 3] | 1/1/2020 | 1/4/2020 |
| household_1 | [45, 55] | [3, 4] | 1/2/2020 | 1/3/2020 |
Você pode usar o procedimento a seguir para agrupar por uma coluna de série temporal.
-
Abra seu fluxo de dados do Data Wrangler.
-
Se você não importou seu conjunto de dados, importe-o na guia Importar dados.
-
No seu fluxo de dados, em Tipos de dados, escolha o + e selecione Adicionar transformação.
-
Escolha Adicionar etapa.
-
Escolha Séries temporais.
-
Em Transformação, escolha Agrupar por.
-
Especifique uma coluna em Agrupar por esta coluna.
-
Em Aplicar às colunas, especifique um valor.
-
Escolha Visualizar para gerar uma visualização prévia da transformação.
-
Escolha Adicionar para adicionar a transformação ao fluxo de dados do Data Wrangler.
Reamostragem de dados de séries temporais
Os dados de séries temporais geralmente têm observações que não são feitas em intervalos regulares. Por exemplo, um conjunto de dados pode ter algumas observações que são registradas de hora em hora e outras observações que são registradas a cada duas horas.
Muitas análises, como algoritmos de previsão, exigem que as observações sejam feitas em intervalos regulares. A reamostragem permite estabelecer intervalos regulares para as observações em seu conjunto de dados.
Você pode aumentar ou diminuir a resolução de uma série temporal. O downsampling (redução da taxa de amostragem) aumenta o intervalo entre as observações no conjunto de dados. Por exemplo, se você reduzir a resolução de observações feitas a cada hora ou a cada duas horas, cada observação em seu conjunto de dados será feita a cada duas horas. As observações horárias são agregadas em um único valor usando um método de agregação, como média ou mediana.
O upsampling (aumento da taxa de amostragem) reduz o intervalo entre as observações no conjunto de dados. Por exemplo, se você transformar observações feitas a cada duas horas em observações de hora em hora, poderá usar um método de interpolação para inferir observações de hora em hora daquelas que foram feitas a cada duas horas. Para obter informações sobre métodos de interpolação, consulte pandas. DataFrame.interpolar
Você pode reamostrar dados numéricos e não numéricos.
Use a operação Reamostrar para reamostrar seus dados de séries temporais. Se você tiver várias séries temporais em seu conjunto de dados, o Data Wrangler padronizará o intervalo de tempo para cada série temporal.
A tabela a seguir mostra um exemplo de redução da amostragem de dados de séries temporais usando a média como método de agregação. Os dados são reduzidos de duas em duas horas para cada hora.
Leituras de temperatura de hora em hora durante um dia antes da redução da amostragem
| Timestamp | Temperatura (Celsius) |
|---|---|
| 12:00 | 30 |
| 1:00 | 32 |
| 2:00 | 35 |
| 3:00 | 32 |
| 4:00 | 30 |
Leituras de temperatura reduzidas para cada duas horas
| Timestamp | Temperatura (Celsius) |
|---|---|
| 12:00 | 30 |
| 2:00 | 33.5 |
| 4:00 | 35 |
Você pode usar o procedimento a seguir para reamostrar dados de série temporal.
-
Abra seu fluxo de dados do Data Wrangler.
-
Se você não importou seu conjunto de dados, importe-o na guia Importar dados.
-
No seu fluxo de dados, em Tipos de dados, escolha o + e selecione Adicionar transformação.
-
Escolha Adicionar etapa.
-
Escolha Reamostrar.
-
Em Timestamp, escolha a coluna de timestamp.
-
Em Unidade de frequência, especifique a frequência com a qual você está reamostrando.
-
(Opcional) Especifique um valor para a quantidade de frequência.
-
Configure a transformação especificando os campos restantes.
-
Escolha Visualizar para gerar uma visualização prévia da transformação.
-
Escolha Adicionar para adicionar a transformação ao fluxo de dados do Data Wrangler.
Lidar com dados de séries temporais ausentes
Se você tiver valores ausentes em seu conjunto de dados, realize um dos seguintes procedimentos:
-
Para conjuntos de dados com várias séries temporais, elimine as séries temporais com valores ausentes maiores que o limite especificado por você.
-
Impute os valores ausentes em uma série temporal usando outros valores na série temporal.
A imputação de um valor ausente envolve a substituição dos dados especificando um valor ou usando um método inferencial. A seguir estão os métodos que você pode usar para imputação:
-
Valor constante: Substitua todos os dados ausentes em seu conjunto de dados por um valor especificado por você.
-
Valor mais comum: Substitua todos os dados ausentes pelo valor que tem a maior frequência no conjunto de dados.
-
Preenchimento futuro: Use um preenchimento futuro para substituir os valores ausentes pelo valor não faltante que precede os valores ausentes. Para a sequência: [2, 4, 7, NaN, NaN, NaN, 8], todos os valores ausentes são substituídos por 7. A sequência resultante do uso de um preenchimento direto é [2, 4, 7, 7, 7, 7, 7, 8].
-
Preenchimento reverso: Use um preenchimento reverso para substituir os valores ausentes pelo valor não omisso que segue os valores ausentes. Para a sequência: [2, 4, 7, NaN, NaN, NaN, 8], todos os valores ausentes são substituídos por 8. A sequência resultante do uso de preenchimento reverso é [2, 4, 7, 8, 8, 8, 8].
-
Interpolar: Usa uma função de interpolação para imputar os valores ausentes. Para obter mais informações sobre as funções que você pode usar para interpolação, consulte pandas. DataFrame.interpolar
.
Alguns dos métodos de imputação podem não conseguir imputar todos os valores ausentes em seu conjunto de dados. Por exemplo, um Preenchimento direto não pode imputar um valor ausente que aparece no início da série temporal. Você pode imputar os valores usando um preenchimento direto ou um preenchimento reverso.
Você pode imputar valores ausentes em uma célula ou em uma coluna.
O exemplo a seguir mostra como os valores são imputados dentro de uma célula.
Uso de eletricidade com valores faltantes
| ID da residência | Série de uso de eletricidade (kWh) |
|---|---|
| household_0 | [30, 40, 35, NaN, NaN] |
| household_1 | [45, NaN, 55] |
Uso de eletricidade com valores imputados usando um preenchimento direto
| ID da residência | Série de uso de eletricidade (kWh) |
|---|---|
| household_0 | [30, 40, 35, 35, 35] |
| household_1 | [45, 45, 55] |
O exemplo a seguir mostra como os valores são imputados em uma coluna.
Uso médio diário de eletricidade doméstica com valores faltantes
| ID da residência | Uso de eletricidade (kWh) |
|---|---|
| household_0 | 30 |
| household_0 | 40 |
| household_0 | NaN |
| household_1 | NaN |
| household_1 | NaN |
Consumo médio diário de eletricidade doméstica com valores imputados usando um preenchimento direto
| ID da residência | Uso de eletricidade (kWh) |
|---|---|
| household_0 | 30 |
| household_0 | 40 |
| household_0 | 40 |
| household_1 | 40 |
| household_1 | 40 |
Você pode usar o procedimento a seguir para processar valores ausentes.
-
Abra seu fluxo de dados do Data Wrangler.
-
Se você não importou seu conjunto de dados, importe-o na guia Importar dados.
-
No seu fluxo de dados, em Tipos de dados, escolha o + e selecione Adicionar transformação.
-
Escolha Adicionar etapa.
-
Escolha Processar ausentes.
-
Para o tipo de entrada de série temporal, escolha se você deseja processar valores ausentes dentro de uma célula ou ao longo de uma coluna.
-
Em Imputar valores ausentes para esta coluna, especifique a coluna que tem os valores ausentes.
-
Em Método para imputar valores, selecione um método.
-
Configure a transformação especificando os campos restantes.
-
Escolha Visualizar para gerar uma visualização prévia da transformação.
-
Se você tiver valores ausentes, poderá especificar um método para imputá-los em Método para imputar valores.
-
Escolha Adicionar para adicionar a transformação ao fluxo de dados do Data Wrangler.
Valide o timestamp de seus dados de séries temporais
Você pode ter dados de timestamps inválidos. Você pode usar a função Validate timestamp para determinar se os timestamps no seu conjunto de dados são válidos. Seu timestamp pode ser inválido por um ou mais dos seguintes motivos:
-
Sua coluna de timestamp tem valores ausentes.
-
Os valores na coluna de timestamp não estão formatados corretamente.
Se você tiver timestamps inválidos em seu conjunto de dados, não poderá realizar sua análise com êxito. Você pode usar o Data Wrangler para identificar timestamps inválidos e entender onde você precisa limpar seus dados.
A validação da série temporal funciona de uma das duas maneiras:
Você pode configurar o Data Wrangler para executar uma das seguintes ações se ele encontrar valores ausentes em seu conjunto de dados:
-
Elimine as linhas que têm os valores ausentes ou inválidos.
-
Elimine as linhas que têm os valores ausentes ou inválidos.
-
Lance um erro se encontrar algum valor ausente ou inválido no seu conjunto de dados.
Você pode validar os timestamps em colunas que tenham o tipo timestamp ou o tipo string. Se a coluna tiver o tipo string, o Data Wrangler converterá o tipo da coluna em timestamp e executará a validação.
É possível usar o procedimento a seguir para validar os timestamps em seu conjunto de dados.
-
Abra seu fluxo de dados do Data Wrangler.
-
Se você não importou seu conjunto de dados, importe-o na guia Importar dados.
-
No seu fluxo de dados, em Tipos de dados, escolha o + e selecione Adicionar transformação.
-
Escolha Adicionar etapa.
-
Escolha Validar timestamps.
-
Na Coluna timestamp, escolha a coluna Timestamp.
-
Em Política, escolha se você deseja lidar com timestamps ausentes.
-
(Opcional) Em Coluna de saída, especifique um nome para a coluna de saída.
-
Se a coluna de data e hora estiver formatada para o tipo de segmento, escolha Transmitir para data e hora.
-
Escolha Visualizar para gerar uma visualização prévia da transformação.
-
Escolha Adicionar para adicionar a transformação ao fluxo de dados do Data Wrangler.
Padronizando a duração da série temporal
Se você tiver dados de séries temporais armazenados como matrizes, poderá padronizar cada série temporal com o mesmo tamanho. Padronizar o tamanho da matriz de séries temporais pode facilitar a realização da análise dos dados.
Você pode padronizar suas séries temporais para transformações de dados que exigem que o tamanho dos dados seja corrigido.
Muitos algoritmos de ML exigem que você nivele seus dados de séries temporais antes de usá-los. Nivelar os dados da série temporal é separar cada valor da série temporal em sua própria coluna em um conjunto de dados. O número de colunas em um conjunto de dados não pode mudar, então os comprimentos das séries temporais precisam ser padronizados entre você e nivelar cada matriz em um conjunto de atributos.
Cada série temporal é definida com o comprimento que você especifica como um quantil ou percentil do conjunto de séries temporais. Por exemplo, você pode ter três sequências com os seguintes comprimentos:
-
3
-
4
-
5
Você pode definir o comprimento de todas as sequências como o comprimento da sequência que tem o comprimento do 50º percentil.
Matrizes de séries temporais menores do que o comprimento especificado têm valores ausentes adicionados. A seguir está um exemplo de formato de padronização da série temporal para um comprimento maior: [2, 4, 5, NaN, NaN, NaN].
Você pode usar abordagens diferentes para lidar com os valores ausentes. Para obter mais informações sobre essas abordagens, consulte Lidar com dados de séries temporais ausentes.
As matrizes de séries temporais maiores que o comprimento especificado são truncadas.
É possível usar o procedimento a seguir para padronizar a duração da série temporal.
-
Abra seu fluxo de dados do Data Wrangler.
-
Se você não importou seu conjunto de dados, importe-o na guia Importar dados.
-
No seu fluxo de dados, em Tipos de dados, escolha o + e selecione Adicionar transformação.
-
Escolha Adicionar etapa.
-
Escolha Padronizar comprimento.
-
Para Padronizar o comprimento da série temporal da coluna, escolha uma coluna.
-
(Opcional) Em Coluna de saída, especifique um nome para a coluna de saída. Se você não especificar um nome, a transformação será feita no local.
-
Se a coluna de data e hora estiver formatada para o tipo de segmento, escolha Transmitir para data e hora.
-
Escolha Quantil de corte e especifique um quantil para definir o comprimento da sequência.
-
Escolha Nivelar a saída para gerar os valores da série temporal em colunas separadas.
-
Escolha Visualizar para gerar uma visualização prévia da transformação.
-
Escolha Adicionar para adicionar a transformação ao fluxo de dados do Data Wrangler.
Extrair atributos de seus dados de séries temporais
Se você estiver executando uma classificação ou um algoritmo de regressão em seus dados de série temporal, recomendamos extrair atributos da série temporal antes de executar o algoritmo. A extração de atributos pode melhorar o desempenho do seu algoritmo.
Use as seguintes opções para escolher como você deseja extrair os atributos dos seus dados:
-
Use o Subconjunto mínimo para especificar a extração de 8 atributos que você sabe que são úteis em análises posteriores. Você pode usar um subconjunto mínimo quando precisar realizar cálculos rapidamente. Você também pode usá-lo quando seu algoritmo de ML tem um alto risco de sobreajuste e você deseja fornecer menos atributos.
-
Use o subconjunto eficiente para especificar a extração do maior número possível de atributos sem extrair atributos que são computacionalmente intensivos em suas análises.
-
Use Todos os atributos para especificar a extração de todos os atributos da série de músicas.
-
Use o Subconjunto manual para escolher uma lista de atributos que você acha que explicam bem a variação em seus dados.
Use o procedimento a seguir para extrair atributos de seus dados de séries temporais.
-
Abra seu fluxo de dados do Data Wrangler.
-
Se você não importou seu conjunto de dados, importe-o na guia Importar dados.
-
No seu fluxo de dados, em Tipos de dados, escolha o + e selecione Adicionar transformação.
-
Escolha Adicionar etapa.
-
Escolha Extrair atributos.
-
Em Extrair atributos para esta coluna, escolha uma coluna.
-
(Opcional) Selecione Nivelado para gerar os atributos em colunas separadas.
-
Em Estratégia, escolha uma estratégia para extrair os atributos.
-
Escolha Visualizar para gerar uma visualização prévia da transformação.
-
Escolha Adicionar para adicionar a transformação ao fluxo de dados do Data Wrangler.
Use atributos atrasados de seus dados de séries temporais
Para muitos casos de uso, a melhor maneira de prever o comportamento futuro de sua série temporal é usar o comportamento mais recente.
Os usos mais comuns de atributos atrasados são os seguintes:
-
Coletando um punhado de valores passados. Por exemplo, para o tempo, t + 1, você coleta t, t - 1, t - 2 e t - 3.
-
Coletando valores que correspondem ao comportamento sazonal nos dados. Por exemplo, para prever a ocupação em um restaurante às 13h, convém usar os atributos a partir das 13h do dia anterior. Usar os atributos a partir das 12h ou 11h no mesmo dia pode não ser tão preditivo quanto usar os atributos dos dias anteriores.
-
Abra seu fluxo de dados do Data Wrangler.
-
Se você não importou seu conjunto de dados, importe-o na guia Importar dados.
-
No seu fluxo de dados, em Tipos de dados, escolha o + e selecione Adicionar transformação.
-
Escolha Adicionar etapa.
-
Selecione os Atributos com atraso.
-
Em Gerar atributos de atraso para essa coluna, escolha uma coluna.
-
Na Coluna timestamp, escolha a coluna contendo timestamps.
-
Para Lag, especifique a duração do atraso.
-
(Opcional) Configure a saída usando uma das seguintes opções:
-
Incluir toda a janela de atraso
-
Nivelar a saída
-
Eliminar linhas sem histórico
-
-
Escolha Visualizar para gerar uma visualização prévia da transformação.
-
Escolha Adicionar para adicionar a transformação ao fluxo de dados do Data Wrangler.
Crie um intervalo de data e hora em sua série temporal
Talvez você tenha dados de séries temporais que não tenham timestamps. Se você sabe que as observações foram feitas em intervalos regulares, você pode gerar timestamps para a série temporal em uma coluna separada. Para gerar timestamps, você especifica o valor do carimbo de data/hora inicial e a frequência dos timestamps.
Por exemplo, você pode ter os seguintes dados de séries temporais para o número de clientes em um restaurante:
Dados de séries temporais sobre o número de clientes em um restaurante
| Número de clientes |
|---|
| 10 |
| 14 |
| 24 |
| 40 |
| 30 |
| 20 |
Se você souber que o restaurante abriu às 17h e que as observações são feitas de hora em hora, você pode adicionar uma coluna de timestamp que corresponda aos dados da série temporal. É possível ver a coluna de timestamp na tabela a seguir.
Dados de séries temporais sobre o número de clientes em um restaurante
| Número de clientes | Timestamp |
|---|---|
| 10 | 13:00h |
| 14 | 14:00h |
| 24 | 15:00h |
| 40 | 16:00h |
| 30 | 17:00h |
| 20 | 18:00h |
Use o procedimento a seguir para adicionar um intervalo de data e hora aos seus dados.
-
Abra seu fluxo de dados do Data Wrangler.
-
Se você não importou seu conjunto de dados, importe-o na guia Importar dados.
-
No seu fluxo de dados, em Tipos de dados, escolha o + e selecione Adicionar transformação.
-
Escolha Adicionar etapa.
-
Escolha Intervalo de data e hora.
-
Em Tipo de frequência, escolha a unidade usada para medir a frequência de timestamps.
-
Em Começando o timestamp, especifique o início do timestamp.
-
Em Coluna de saída, especifique um nome para a coluna de saída.
-
(Opcional) Configure a saída usando os campos restantes.
-
Escolha Visualizar para gerar uma visualização prévia da transformação.
-
Escolha Adicionar para adicionar a transformação ao fluxo de dados do Data Wrangler.
Use uma janela contínua em sua série temporal
Você pode extrair atributos ao longo de um período de tempo. Por exemplo, para o tempo, t, e uma janela de tempo de comprimento 3, e para a linha que indica o timestamp t, anexamos os atributos extraídas da série temporal nos momentos t - 3, t - 2 e t - 1. Para obter informações sobre como extrair atributos, consulte Extrair atributos de seus dados de séries temporais.
É possível usar o procedimento a seguir para extrair atributos em um período.
-
Abra seu fluxo de dados do Data Wrangler.
-
Se você não importou seu conjunto de dados, importe-o na guia Importar dados.
-
No seu fluxo de dados, em Tipos de dados, escolha o + e selecione Adicionar transformação.
-
Escolha Adicionar etapa.
-
Escolha Atributos da janela contínua.
-
Em Gerar atributos de janela contínua para esta coluna, escolha uma coluna.
-
Na Coluna timestamp, escolha a coluna contendo timestamps.
-
(Opcional) Em Coluna de saída, especifique o nome da coluna de saída.
-
Em Tamanho da janela, especifique o tamanho da janela.
-
Em Estratégia, escolha uma estratégia para extrair os atributos.
-
Escolha Visualizar para gerar uma visualização prévia da transformação.
-
Escolha Adicionar para adicionar a transformação ao fluxo de dados do Data Wrangler.
Destacar data e hora
Use Destacar data/hora para criar uma incorporação vetorial representando um campo de data e hora. Para usar essa transformação, os dados de data e hora devem estar em um dos seguintes formatos:
-
Segmentos que descrevem a data e hora: Por exemplo,
"January 1st, 2020, 12:44pm". -
Um timestamp Unix: um timestamp Unix descreve o número de segundos, milissegundos, microssegundos ou nanossegundos a partir de 1/1/1970.
Você pode escolher inferir o formato de data e hora e fornecer um formato de data e hora. Se você fornecer um formato de data e hora, deverá usar os códigos descritos na documentação do Python
-
A opção mais manual e computacionalmente mais rápida é especificar um Formato de data e hora e selecionar Não para Inferir formato de data e hora.
-
Para reduzir o trabalho manual, você pode escolher Inferir formato de data e hora e não especificar um formato de data e hora. É também uma operação computacionalmente rápida; entretanto, o primeiro formato de data e hora encontrado na coluna de entrada é considerado o formato da coluna inteira. Se houver outros formatos na coluna, esses valores serão NaN na saída final. Inferir o formato de data e hora pode fornecer segmentos não analisados.
-
Se você não especificar um formato e selecionar Não para Inferir formato de data e hora, obterá os resultados mais robustos. Todos os segmentos de data e hora válidos são analisados. No entanto, essa operação pode ser uma ordem de magnitude mais lenta do que as duas primeiras opções dessa lista.
Ao usar essa transformação, você especifica uma coluna de entrada que contém dados de data e hora em um dos formatos listados acima. A transformação cria uma coluna de saída chamada Nome da coluna de saída. O formato da coluna de saída depende da sua configuração usando o seguinte:
-
Vetor: gera uma única coluna como vetor.
-
Colunas: cria uma nova coluna para cada atributo. Por exemplo, se a saída tiver um ano, mês e dia, três colunas separadas serão criadas para ano, mês e dia.
Além disso, você deve escolher um modo de incorporação. Para modelos lineares e redes profundas, recomendamos escolher o cíclico. Para algoritmos baseados em árvore, recomendamos escolher ordinal.
Formatar segmento
As transformações Formatar segmento contêm operações de formatação de segmento padrão. Por exemplo, você pode usar essas operações para remover caracteres especiais, normalizar comprimentos de segmentos e atualizar maiúsculas e minúsculas.
Esse grupo de atributos contém as seguintes transformações: Todas as transformações retornam cópias de segmentos na coluna Entrada e adicionam o resultado a uma nova coluna de saída.
| Name | Função |
|---|---|
| Almofada esquerda |
Pressione com o botão esquerdo o segmento com um determinado caractere de preenchimento até a largura especificada. Se o segmento for maior que a largura, o valor de retorno será reduzido para caracteres de largura. |
| Almofada direita |
Preencha com o botão direito o segmento com um determinado caractere de preenchimento até a largura especificada. Se o segmento for maior que a largura, o valor de retorno será reduzido para caracteres de largura. |
| Centro (almofadas em ambos os lados) |
Coloque o segmento no centro (adicione preenchimento nos dois lados do segmento) com um determinado caractere de preenchimento até a largura especificada. Se o segmento for maior que a largura, o valor de retorno será reduzido para caracteres de largura. |
| Acrescentar zeros à esquerda |
Preencha à esquerda um segmento numérico com zeros, até uma determinada largura. Se o segmento for maior que a largura, o valor de retorno será reduzido para caracteres de largura. |
| Remova à esquerda e à direita |
Retorna uma cópia do segmento com os caracteres iniciais e finais removidos. |
| Remova os caracteres da esquerda |
Retorna uma cópia de segmento com os caracteres iniciais removidos. |
| Remova os caracteres da direita |
Retorna uma cópia do segmento com os caracteres finais removidos. |
| Letras minúsculas |
Converta todas as letras do texto em letras minúsculas. |
| Letras maiúsculas |
Converta todas as letras do texto em letras maiúsculas. |
| Capitalizar |
Coloque a primeira letra em maiúscula em cada frase. |
| Alternar letra maiúscula e minúscula | Converte todos os caracteres maiúsculos em minúsculos e todos os caracteres minúsculos em caracteres maiúsculos de segmento fornecida e o retorna. |
| Adicionar prefixo ou sufixo |
Adiciona um prefixo e um sufixo à coluna do segmento. Você deve especificar pelo menos um dos Prefixos e Sufixos. |
| Remover símbolos |
Remove os símbolos fornecidos de um segmento. Todos os caracteres listados são removidos. O padrão é espaço em branco. |
Lidar com valores discrepantes
Os modelos de machine learning são sensíveis à distribuição e ao alcance dos valores de seus atributos. Valores discrepantes, ou valores raros, podem afetar negativamente a precisão do modelo e levar a tempos de treinamento mais longos. Use esse grupo de atributos para detectar e atualizar valores discrepantes em seu conjunto de dados.
Quando você define uma etapa de transformação Lidar com valores discrepantes, as estatísticas usadas para detectar valores discrepantes são geradas nos dados disponíveis no Data Wrangler ao definir essa etapa. Essas mesmas estatísticas são usadas ao executar um trabalho do Data Wrangler.
Use as seções a seguir para saber mais sobre as transformações que este grupo contém. Você especifica um nome de saída e cada uma dessas transformações gera uma coluna de saída com os dados resultantes.
Valores discrepantes numéricos robustos de desvio padrão
Essa transformação detecta e corrige valores discrepantes em atributos numéricos usando estatísticas que são robustas a valores discrepantes.
Você deve definir um quantil superior e um quantil inferior para as estatísticas usadas para calcular valores discrepantes. Você também deve especificar o número de desvios padrão dos quais um valor deve variar da média para ser considerado um valor atípico. Por exemplo, se você especificar 3 para desvios padrão, um valor deve ser de mais de 3 desvios padrão da média para ser considerado um valor atípico.
O Método Fix é o método usado para lidar com valores discrepantes quando eles são detectados. Você pode escolher entre as seguintes opções:
-
Clipe: use essa opção para recortar os valores discrepantes no limite de detecção de valores discrepantes correspondente.
-
Remover: use essa opção para remover linhas com valores discrepantes do dataframe.
-
Invalidar: use essa opção para substituir valores discrepantes por valores inválidos.
Valores atípicos numéricos de desvio padrão
Essa transformação detecta e corrige valores discrepantes em atributos numéricos usando a média e o desvio padrão.
Você especifica o número de desvios padrão dos quais um valor deve variar da média para ser considerado um valor atípico. Por exemplo, se você especificar 3 para desvios padrão, um valor deve ser de mais de 3 desvios padrão da média para ser considerado um valor atípico.
O Método Fix é o método usado para lidar com valores discrepantes quando eles são detectados. Você pode escolher entre as seguintes opções:
-
Clipe: use essa opção para recortar os valores discrepantes no limite de detecção de valores discrepantes correspondente.
-
Remover: use essa opção para remover linhas com valores discrepantes do dataframe.
-
Invalidar: use essa opção para substituir valores discrepantes por valores inválidos.
Valores atípicos numéricos quantílicos
Use esta transformação para detectar e corrigir valores discrepantes em atributos numéricos usando quantis. Você pode definir um quantil superior e um quantil inferior. Todos os valores que ficam acima do quantil superior ou abaixo do quantil inferior são considerados discrepantes.
O Método Fix é o método usado para lidar com valores discrepantes quando eles são detectados. Você pode escolher entre as seguintes opções:
-
Clipe: use essa opção para recortar os valores discrepantes no limite de detecção de valores discrepantes correspondente.
-
Remover: use essa opção para remover linhas com valores discrepantes do dataframe.
-
Invalidar: use essa opção para substituir valores discrepantes por valores inválidos.
Valores discrepantes numéricos mínimo-máximos
Essa transformação detecta e corrige valores discrepantes em atributos numéricos usando limites superiores e inferiores. Use esse método se você conhece valores limite que demarcam valores discrepantes.
Você especifica um limite superior e um limite inferior e, se os valores ficarem acima ou abaixo desses limites, respectivamente, eles serão considerados valores discrepantes.
O Método Fix é o método usado para lidar com valores discrepantes quando eles são detectados. Você pode escolher entre as seguintes opções:
-
Clipe: use essa opção para recortar os valores discrepantes no limite de detecção de valores discrepantes correspondente.
-
Remover: use essa opção para remover linhas com valores discrepantes do dataframe.
-
Invalidar: use essa opção para substituir valores discrepantes por valores inválidos.
Substituir valores raros
Ao usar a transformação Substituir valores raros, você especifica um limite e o Data Wrangler localiza todos os valores que atendem a esse limite e os substitui por um segmento especificado por você. Por exemplo, talvez você queira usar essa transformação para categorizar todos os valores atípicos em uma coluna em uma categoria “Outros”.
-
Segmento de substituição: a sequência com a qual substituir valores discrepantes.
-
Limite absoluto: uma categoria é rara se o número de instâncias for menor ou igual a esse limite absoluto.
-
Limite de fração: uma categoria é rara se o número de instâncias for menor ou igual a esse limite de fração multiplicado pelo número de linhas.
-
Máximo de categorias comuns: máximo de categorias não raras que permanecem após a operação. Se o limiar não filtrar categorias suficientes, aquelas com o maior número de ocorrências são classificadas como não raras. Se definido como 0 (padrão), não há limite rígido para o número de categorias.
Processamento de valores ausentes
Valores ausentes são uma ocorrência comum em conjuntos de dados de machine learning. Em algumas situações, é apropriado imputar aos dados faltantes um valor calculado, como um valor médio ou categoricamente comum. Você pode processar valores ausentes usando o grupo de transformação Processar valores ausentes. Esse grupo contém as seguintes transformações:
Preencher valores ausentes
Use a transformação Preencher valores ausentes para substituir valores ausentes por um valor do preenchimento definido por você.
Imputar valores ausentes
Use a transformação de Imputar valores ausentes para criar uma nova coluna que contenha valores imputados onde valores ausentes foram encontrados nos dados de entrada categóricos e numéricos. A configuração depende do seu tipo de dados.
Para dados numéricos, escolha uma estratégia de imputação, a estratégia usada para determinar o novo valor a ser imputado. Você pode optar por imputar a média ou a mediana sobre os valores que estão presentes no seu conjunto de dados. O Data Wrangler usa o valor que ele computa para imputar os valores ausentes.
Para dados categóricos, o Data Wrangler imputa valores ausentes usando o valor mais frequente na coluna. Para imputar um segmento personalizado, use a transformação Preenchimento ausente em vez disso.
Adicionar indicador de valores ausentes
Use a transformação Adicionar indicador para valores ausentes para criar uma nova coluna indicadora, que contém um booleano "false" se uma linha contiver um valor e "true" se uma linha contiver um valor ausente.
Eliminar valores ausentes
Use a opção Eliminar valores ausentes para remover linhas que contêm valores ausentes da Coluna de entrada.
Gerenciar colunas
Você pode usar as seguintes transformações para atualizar e gerenciar rapidamente as colunas no seu conjunto de dados:
| Name | Função |
|---|---|
| Soltar coluna | Exclua uma coluna. |
| Duplicar coluna | Duplique uma coluna. |
| Renomear coluna | Renomeie uma coluna. |
| Mover coluna |
Mova a localização de uma coluna no conjunto de dados. Escolha mover sua coluna para o início ou o final do conjunto de dados, antes ou depois de uma coluna de referência ou para um índice específico. |
Gerenciar linhas
Use esse grupo de transformação para executar rapidamente as operações de classificação e reprodução aleatória nas linhas. Este grupo contém o seguinte:
-
Classificar: classifique todo o dataframe por uma determinada coluna. Marque a caixa de seleção ao lado de Ordem crescente para essa opção; caso contrário, desmarque a caixa de seleção e a ordem decrescente será usada para a classificação.
-
Embaralhar: embaralhe aleatoriamente todas as linhas no conjunto de dados.
Gerenciar vetores
Use esse grupo de transformação para combinar ou nivelar colunas vetoriais. Esse grupo contém as seguintes transformações:
-
Montar: use essa transformação para combinar vetores e dados numéricos do Spark em uma única coluna. Por exemplo, você pode combinar três colunas: duas contendo dados numéricos e uma contendo vetores. Adicione todas as colunas que você deseja combinar nas colunas de entrada e especifique um nome de coluna de saída para os dados combinados.
-
Nivelar: use essa transformação para nivelar uma única coluna contendo dados vetoriais. A coluna de entrada deve conter PySpark vetores ou objetos semelhantes a matrizes. Você pode controlar o número de colunas criadas especificando um método para detectar o número de saídas. Por exemplo, se você selecionar Comprimento do primeiro vetor, o número de elementos no primeiro vetor ou matriz válido encontrado na coluna determinará o número de colunas de saída criadas. Todos os outros vetores de entrada com muitos itens serão truncados. As entradas com poucos itens são preenchidas com NaNs.
Você também especifica um prefixo de saída, que é usado como prefixo para cada coluna de saída.
Processo numérico
Use o grupo de atributos Processar numérico para processar dados numéricos. Cada escalar desse grupo é definido usando a biblioteca Spark. Os seguintes escalares são compatíveis:
-
Escalonador padrão: padronize a coluna de entrada subtraindo a média de cada valor e dimensionando para a variação unitária. Para saber mais, consulte a documentação do Spark para StandardScaler.
-
Escalonador robusto: escale a coluna de entrada usando estatísticas que são robustas a valores discrepantes. Para saber mais, consulte a documentação do Spark para RobustScaler
. -
Escalonador mínimo máximo: transforme a coluna de entrada escalando cada atributo para um determinado intervalo. Para saber mais, consulte a documentação do Spark para MinMaxScaler
. -
Escalonador absoluto máximo: escale a coluna de entrada dividindo cada valor pelo valor absoluto máximo. Para saber mais, consulte a documentação do Spark para MaxAbsScaler
.
Amostragem
Depois de importar seus dados, você pode usar o transformador de amostragem para coletar uma ou mais amostras deles. Quando você usa o transformador de amostragem, o Data Wrangler coleta amostras do seu conjunto de dados original.
Você pode escolher um dos seguintes métodos de amostra:
-
Limite: faça uma amostra do conjunto de dados a partir da primeira linha até o limite que você especificar.
-
Aleatório: obtém uma amostra aleatória de um tamanho especificado por você.
-
Estratificado: obtém uma amostra aleatória estratificada.
Você pode estratificar uma amostra aleatória para garantir que ela represente a distribuição original do conjunto de dados.
Você pode estar realizando a preparação de dados para vários casos de uso. Para cada caso de uso, você pode pegar uma amostra diferente e aplicar um conjunto diferente de transformações.
O procedimento a seguir descreve o processo de criar uma amostra aleatória.
Para obter uma amostra aleatória dos seus dados.
-
Escolha o + à direita do conjunto de dados que você importou. O nome do seu conjunto de dados está localizado abaixo do +.
-
Escolha Adicionar transformação.
-
Escolha Amostragem.
-
Para Método de amostragem, escolha o método de amostragem.
-
Em Tamanho aproximado da amostra, escolha o número aproximado de observações que você deseja em sua amostra.
-
(Opcional) Especifique um número inteiro para Semente aleatória para criar uma amostra reproduzível.
O procedimento a seguir descreve o processo de criação de uma amostra estratificada.
Para obter uma amostra estratificada de seus dados.
-
Escolha o + à direita do conjunto de dados que você importou. O nome do seu conjunto de dados está localizado abaixo do +.
-
Escolha Adicionar transformação.
-
Escolha Amostragem.
-
Para Método de amostragem, escolha o método de amostragem.
-
Em Tamanho aproximado da amostra, escolha o número aproximado de observações que você deseja em sua amostra.
-
Em Estratificar coluna, especifique o nome da coluna na qual você deseja estratificar.
-
(Opcional) Especifique um número inteiro para Semente aleatória para criar uma amostra reproduzível.
Pesquisar e editar
Use esta seção para pesquisar e editar padrões específicos em segmentos. Por exemplo, você pode localizar e atualizar segmentos em frases ou documentos, dividir segmentos por delimitadores e localizar ocorrências de segmentos específicos.
As seguintes transformações são compatíveis com Pesquisar e editar: Todas as transformações retornam cópias de segmentos na Coluna Entrada e adicionam o resultado a uma nova coluna de saída.
| Name | Função |
|---|---|
|
Encontre um sub-segmento |
Retorna o índice da primeira ocorrência do Sub-segmento pela qual você pesquisou. Você pode iniciar e terminar a pesquisa no Início e no Fim, respectivamente. |
|
Encontre um sub-segmento (da direita) |
Retorna o índice da última ocorrência do Sub-segmento que você pesquisou. Você pode iniciar e finalizar a pesquisa no Início e no Fim, respectivamente. |
|
Corresponde ao prefixo |
Retorna um valor booleano se o segmento tiver um determinado padrão. Um padrão pode ser uma sequência de caracteres ou uma expressão regular. Opcionalmente, você pode diferenciar o padrão de maiúsculas e minúsculas. |
|
Encontre todas as ocorrências |
Retorna uma matriz com todas as ocorrências de um determinado padrão. Um padrão pode ser uma sequência de caracteres ou uma expressão regular. |
|
Extrair usando regex |
Retorna um segmento que corresponde a um determinado padrão regex. |
|
Extrair entre delimitadores |
Retorna um segmento com todos os caracteres encontrados entre o delimitador esquerdo e o delimitador direito. |
|
Extrair da posição |
Retorna um segmento, começando da posição inicial no segmento de entrada, que contém todos os caracteres até a posição inicial mais o comprimento. |
|
Encontre e substitua a sub-segmento |
Retorna um segmento com todas as correspondências de um determinado padrão (expressão regular) substituída pelo segmento de substituição. |
|
Substituir entre delimitadores |
Retorna um segmento com a sub-segmento encontrada entre a primeira aparição de um delimitador esquerdo e a última aparição de um delimitador direito substituída pelo segmento de substituição. Se nenhuma correspondência for encontrada, nada é substituído. |
|
Substituir da posição |
Retorna um segmento com a sub-segmento entre a posição inicial e a posição inicial mais o comprimento substituída pelo segmento de substituição. Se a posição inicial mais o comprimento for maior que o comprimento de segmento de substituição, a saída conterá.... |
|
Converter regex para ausente |
Converte um segmento em |
|
Dividir segmento por delimitador |
Retorna uma matriz de srtrings da string de entrada, dividida por Delimitador, com até o Número máximo de divisões (opcional). O delimitador usa como padrão o espaço em branco. |
Dividir dados
Use a transformação Dividir dados para dividir seu conjunto de dados em dois ou três conjuntos de dados. Por exemplo, você pode dividir seu conjunto de dados em um conjunto de dados usado para treinar seu modelo e um conjunto de dados usado para testá-lo. Você pode determinar a proporção do conjunto de dados que entra em cada divisão. Por exemplo, se você estiver dividindo um conjunto de dados em dois conjuntos, o conjunto de treinamento pode ter 80% dos dados, enquanto o conjunto de teste terá 20%.
A divisão de seus dados em três conjuntos de dados permite criar conjuntos de dados de treinamento, validação e teste. Você pode ver o desempenho do modelo no conjunto de dados de teste eliminando a coluna de destino.
Seu caso de uso determina quanto do conjunto de dados original cada um de seus conjuntos de dados obtém e o método usado para dividir os dados. Por exemplo, você pode querer usar uma divisão estratificada para garantir que a distribuição das observações na coluna alvo seja a mesma em todos os conjuntos de dados. Você pode usar as seguintes transformações divididas:
-
Divisão aleatória: Cada divisão é uma amostra aleatória e não sobreposta do conjunto de dados original. Para conjuntos de dados maiores, utilizar uma divisão aleatória pode ser computacionalmente custoso e levar mais tempo do que uma divisão ordenada.
-
Divisão ordenada: divide o conjunto de dados com base na ordem sequencial das observações. Por exemplo, em uma divisão de treino/teste de 80/20, as primeiras observações que compõem 80% do conjunto de dados são destinadas ao conjunto de treinamento. Os últimos 20% das observações vão para o conjunto de dados de teste. As divisões ordenadas são eficazes para manter a ordem existente dos dados entre as divisões.
-
Divisão estratificada: divide o conjunto de dados para garantir que o número de observações na coluna de entrada tenha representação proporcional. Para uma coluna de entrada que possui as observações 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3, 3, uma divisão de 80/20 nessa coluna significaria que aproximadamente 80% dos 1s, 80% dos 2s e 80% dos 3s iriam para o conjunto de treinamento. Cerca de 20% de cada tipo de observação vai para o conjunto de testes.
-
Dividir por chave: evita que dados com a mesma chave ocorram em mais de uma divisão. Por exemplo, se você tiver um conjunto de dados com a coluna “customer_id” e o estiver usando como chave, nenhum ID de cliente estará em mais de uma divisão.
Depois de dividir os dados, você pode aplicar transformações adicionais a cada conjunto de dados. Para a maioria dos casos de uso, eles não são necessários.
O Data Wrangler calcula as proporções das divisões para desempenho. Você pode escolher um limite de erro para definir a precisão das divisões. Limites de erro mais baixos refletem de forma mais precisa as proporções que você especifica para as divisões. Se você definir um limite de erro mais alto, obterá melhor desempenho, mas menor precisão.
Para dividir perfeitamente os dados, defina o limite de erro como 0. Você pode especificar um limite entre 0 e 1 para melhorar o desempenho. Se você especificar um valor maior que 1, o Data Wrangler interpretará esse valor como 1.
Se você tiver 10.000 linhas em seu conjunto de dados e especificar uma divisão 80/20 com um erro de 0,001, obterá observações que se aproximam de um dos seguintes resultados:
-
8010 observações no conjunto de treinamento e 1990 no conjunto de testes
-
7990 observações no conjunto de treinamento e 2010 no conjunto de testes
O número de observações para o conjunto de testes no exemplo anterior está no intervalo entre 8010 e 7990.
Por padrão, o Data Wrangler usa uma semente aleatória para tornar as divisões reproduzíveis. Você pode especificar um valor diferente para a semente para criar uma divisão reproduzível diferente.
Analisar valor como tipo
Use essa transformação para converter uma coluna em um novo tipo. Os tipos de dados do Data Wrangler compatíveis são:
-
Longo
-
Float
-
Booleano
-
Data, no formato dd-MM-yyyy, representando dia, mês e ano, respectivamente.
-
String
Validar segmento
Use as transformações Validar segmento para criar uma nova coluna que indica que uma linha de dados de texto atende a uma condição especificada. Por exemplo, você pode usar uma transformação Validar segmento para verificar se um segmento contém somente caracteres minúsculos. As seguintes transformações são compatíveis com Validar segmento:
As seguintes transformações estão incluídas nesse grupo de transformações: Se uma transformação gerar um valor booleano, True é representada com a 1 e False é representada com a 0.
| Name | Função |
|---|---|
|
Tamanho da segmento |
Retorna |
|
Inicia com |
Retorna |
|
Termina com |
Retorna |
|
É alfanumérico |
Retorna |
|
É alfa (letras) |
Retorna |
|
É dígito |
Retorna |
|
É espaço |
Retorna |
|
É título |
Retorna |
|
Está em letra minúscula |
Retorna |
|
Está em letra maiúscula |
Retorna |
|
É numérico |
Retorna |
|
É decimal |
Retorna |
Desaninhar dados JSON
Se você tiver um arquivo.csv, talvez tenha valores em seu conjunto de dados que sejam segmentos JSON. Da mesma forma, você pode ter dados aninhados em colunas de um arquivo Parquet ou de um documento JSON.
Use o operador estruturado nivelado para separar as chaves de primeiro nível em colunas separadas. Uma chave de primeiro nível é uma chave que não está aninhada em um valor.
Por exemplo, você pode ter um conjunto de dados que tenha uma coluna pessoa com informações demográficas de cada pessoa armazenadas como segmentos JSON. Seu segmento JSON pode ser semelhante à seguinte:
"{"seq": 1,"name": {"first": "Nathaniel","last": "Ferguson"},"age": 59,"city": "Posbotno","state": "WV"}"
O operador estruturado nivelado converte as seguintes chaves de primeiro nível em colunas adicionais no seu conjunto de dados:
-
seq
-
nome
-
idade
-
city
-
estado
O Data Wrangler coloca os valores das chaves como valores abaixo das colunas. Veja a seguir os nomes e valores das colunas do JSON.
seq, name, age, city, state 1, {"first": "Nathaniel","last": "Ferguson"}, 59, Posbotno, WV
Para cada valor em seu conjunto de dados contendo JSON, o operador estruturado nivelado cria colunas para as chaves de primeiro nível. Para criar colunas para chaves aninhadas, chame o operador novamente. Para o exemplo anterior, chamar o operador cria as colunas:
-
name_first
-
name_last
O exemplo a seguir mostra o conjunto de dados resultante de chamar a operação novamente.
seq, name, age, city, state, name_first, name_last 1, {"first": "Nathaniel","last": "Ferguson"}, 59, Posbotno, WV, Nathaniel, Ferguson
Escolha Teclas para nivelar para especificar as chaves de primeiro nível que você deseja extrair como colunas separadas. Se você não especificar nenhuma chave, o Data Wrangler extrairá todas as chaves por padrão.
Explodir matriz
Use Explode matriz para expandir os valores da matriz em linhas de saída separadas. Por exemplo, a operação pode pegar cada valor na matriz, [[1, 2, 3,], [4, 5, 6], [7, 8, 9]] e criar uma nova coluna com as seguintes linhas:
[1, 2, 3] [4, 5, 6] [7, 8, 9]
O Data Wrangler nomeia a nova coluna como input_column_name_flatten.
Você pode chamar a operação Explodir matriz várias vezes para colocar os valores aninhados da matriz em colunas de saída separadas. O exemplo a seguir mostra o resultado de chamar a operação várias vezes em um conjunto de dados com uma matriz aninhada.
Colocando os valores de uma matriz aninhada em colunas separadas
| id | array | id | array_items | id | array_items_items |
|---|---|---|---|---|---|
| 1 | [[gato, cachorro], [morcego, sapo]] | 1 | [gato, cachorro] | 1 | cat |
| 2 |
[[rosa, petúnia], [lírio, margarida]] |
1 | [morcego, sapo] | 1 | dog |
| 2 | [rosa, petúnia] | 1 | bat | ||
| 2 | [lírio, margarida] | 1 | sapo | ||
| 2 | 2 | rose | |||
| 2 | 2 | petúnia | |||
| 2 | 2 | lírio | |||
| 2 | 2 | margarida |
Transformar dados de imagem
Use o Data Wrangler para importar e transformar as imagens que você está usando para seus pipelines de machine learning (ML). Depois de preparar os dados de imagem, você pode exportá-los do fluxo do Data Wrangler para o pipeline de ML.
Você pode usar as informações fornecidas aqui para se familiarizar com a importação e transformação de dados de imagem no Data Wrangler. O Data Wrangler usa o OpenCV para importar imagens. Para obter mais informações sobre os formatos de imagem compatíveis, consulte Leitura e gravação de arquivos de imagem
Depois de se familiarizar com os conceitos de transformação de seus dados de imagem, leia o tutorial a seguir, Preparar dados de imagem com o Amazon SageMaker Data Wrangler
Os setores e casos de uso a seguir são exemplos nos quais a aplicação de machine learning a dados de imagem transformados pode ser útil:
-
Fabricação - Identificação de defeitos em itens da linha de montagem
-
Alimentação - Identificação de alimentos estragados ou deteriorados
-
Medicina - Identificação de lesões nos tecidos
Ao trabalhar com dados de imagem no Data Wrangler, você passa pelo seguinte processo:
-
Importar - Selecione as imagens escolhendo o diretório que as contém em seu bucket do Amazon S3.
-
Transformar - Use as transformações integradas para preparar as imagens para seu pipeline de machine learning.
-
Exportar: Exporte as imagens que você transformou para um local que possa ser acessado a partir do pipeline.
Use o seguinte procedimento para importar seus dados de imagem:
Para importar seus dados de imagem
-
Navegue até a página Criar conexão.
-
Escolha Amazon S3.
-
Especifique o caminho do arquivo do Amazon S3 que contém os dados de imagem.
-
Em Tipo de arquivo, escolha Imagem.
-
(Opcional) Escolha Importar diretórios aninhados para importar imagens de vários caminhos do Amazon S3.
-
Escolha Importar.
O Data Wrangler usa a biblioteca imgaug
-
ResizeImage
-
EnhanceImage
-
CorruptImage
-
SplitImage
-
DropCorruptedImages
-
DropImageDuplicates
-
Brightness
-
ColorChannels
-
Grayscale
-
Rotate
Use o procedimento a seguir para transformar suas imagens sem escrever código.
Para transformar os dados de imagem sem escrever código
-
No fluxo do Data Wrangler, escolha o + ao lado do nó que representa as imagens que você importou.
-
Escolha Adicionar transformação.
-
Escolha Adicionar etapa.
-
Escolha a transformação e configure-a.
-
Escolha Pré-visualizar.
-
Escolha Adicionar.
Além de usar as transformações fornecidas pelo Data Wrangler, você também pode usar seus próprios trechos de código personalizados. Para obter mais informações sobre como usar snippets de código personalizados, consulte Transformações personalizadas. Você pode importar as bibliotecas OpenCV e imgaug em seus trechos de código e usar as transformações associadas a elas. O seguinte exemplo mostra um de um snippet de código que detecta bordas nas imagens:
# A table with your image data is stored in the `df` variable import cv2 import numpy as np from pyspark.sql.functions import column from sagemaker_dataprep.compute.operators.transforms.image.constants import DEFAULT_IMAGE_COLUMN, IMAGE_COLUMN_TYPE from sagemaker_dataprep.compute.operators.transforms.image.decorators import BasicImageOperationDecorator, PandasUDFOperationDecorator @BasicImageOperationDecorator def my_transform(image: np.ndarray) -> np.ndarray: # To use the code snippet on your image data, modify the following lines within the function HYST_THRLD_1, HYST_THRLD_2 = 100, 200 edges = cv2.Canny(image,HYST_THRLD_1,HYST_THRLD_2) return edges @PandasUDFOperationDecorator(IMAGE_COLUMN_TYPE) def custom_image_udf(image_row): return my_transform(image_row) df = df.withColumn(DEFAULT_IMAGE_COLUMN, custom_image_udf(column(DEFAULT_IMAGE_COLUMN)))
Ao aplicar transformações em seu fluxo do Data Wrangler, o Data Wrangler as aplica somente a uma amostra das imagens em seu conjunto de dados. Para otimizar sua experiência com a aplicação, o Data Wrangler não aplica as transformações em todas as suas imagens.
Para aplicar as transformações em todas as suas imagens, exporte seu fluxo do Data Wrangler para um local do Amazon S3. Você pode usar as imagens que você exportou em seus pipelines de treinamento ou inferência. Use um nó de destino ou um caderno Jupyter para exportar seus dados. Você pode acessar qualquer um dos métodos para exportar seus dados do fluxo do Data Wrangler. Para obter mais informações sobre como usar esses métodos, consulte Exportar para o Amazon S3..
Filtrar dados
Use o Data Wrangler para filtrar os dados em suas colunas. Ao filtrar os dados em uma coluna, você especifica os seguintes campos:
-
Nome da coluna: O nome da coluna que você está usando para filtrar os dados.
-
Condição: O tipo de filtro que você está aplicando aos valores na coluna.
-
Valor: O valor ou a categoria na coluna à qual você está aplicando o filtro.
Você pode filtrar nas seguintes condições:
-
=: Retorna valores que correspondem ao valor ou categoria que você especifica.
-
!=: Retorna valores que correspondem ao valor ou categoria que você especifica.
-
>=: Para dados longos ou flutuantes, filtra valores maiores ou iguais ao valor especificado.
-
<=: Para dados longos ou flutuantes, filtra valores menores ou iguais ao valor especificado.
-
>: Para dados longos ou flutuantes, filtra valores maiores que o valor especificado.
-
<: Para dados longos ou flutuantes, filtra valores menores que o valor especificado.
Para uma coluna que tem as categorias male e female, você pode filtrar todos os valores male. Você também pode filtrar todos os valores female. Como há somente valores male e female na coluna, o filtro retorna uma coluna que só tem valores female.
Você também pode adicionar vários filtros. Os filtros podem ser aplicados em várias colunas ou na mesma coluna. Por exemplo, se você estiver criando uma coluna que só tem valores dentro de um determinado intervalo, você adiciona dois filtros diferentes. Um filtro especifica que a coluna deve ter valores maiores do que o valor fornecido. O outro filtro especifica que a coluna deve ter valores menores que o valor fornecido.
Use o procedimento a seguir para adicionar a transformação de filtro aos seus dados.
Para filtrar seus dados
-
No fluxo do Data Wrangler, escolha o + ao lado do nó com os dados que você está filtrando.
-
Escolha Adicionar transformação.
-
Escolha Adicionar etapa.
-
Escolha Filtrar dados.
-
Especifique os seguintes campos:
-
Nome da coluna: A coluna que você está filtrando.
-
Condição: A condição do filtro.
-
Valor: O valor ou a categoria na coluna à qual você está aplicando o filtro.
-
-
(Opcional) Escolha + seguindo o filtro que você criou.
-
Configure o filtro.
-
Escolha Pré-visualizar.
-
Escolha Adicionar.
Colunas de mapas do Amazon Personalize
O Data Wrangler se integra ao Amazon Personalize, um serviço de machine learning totalmente gerenciado que gera recomendações de itens e segmentos de usuários. Você pode usar as colunas do Mapa para transformar o Amazon Personalize para colocar seus dados em um formato que o Amazon Personalize possa interpretar. Para obter mais informações sobre as transformações específicas do Amazon Personalize, consulte Importação de dados usando o Amazon SageMaker Data Wrangler. Para obter mais informações sobre o Amazon Personalize, consulte O que é o Amazon Personalize?
