As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Demonstrações e visualização avançadas do Debugger
As demonstrações a seguir mostram casos de uso avançados e scripts de visualização usando o Debugger.
Tópicos
- Treine e ajuste seus modelos com o Amazon SageMaker Experiments and Debugger
- Usando o SageMaker Debugger para monitorar um treinamento de modelo de autoencoder convolucional
- Usando o SageMaker Debugger para monitorar as atenções no treinamento do modelo BERT
- Usando o SageMaker Debugger para visualizar mapas de ativação de classes em redes neurais convolucionais (CNNs)
Treine e ajuste seus modelos com o Amazon SageMaker Experiments and Debugger
Dra. Nathalie Rauschmayr, Cientista AWS Aplicada | Duração: 49 minutos 26 segundos
Descubra como o Amazon SageMaker Experiments and Debugger pode simplificar o gerenciamento de seus trabalhos de treinamento. O Amazon SageMaker Debugger fornece visibilidade transparente das tarefas de treinamento e salva métricas de treinamento em seu bucket do Amazon S3. SageMaker O Experiments permite que você chame as informações de treinamento como testes por meio do SageMaker Studio e oferece suporte à visualização do trabalho de treinamento. Isso ajuda a manter uma alta qualidade do modelo enquanto reduz parâmetros menos importantes com base na classificação de importância.
Este vídeo demonstra uma técnica de poda de modelos que torna os AlexNet modelos pré-treinados ResNet 50 e S mais leves e acessíveis, mantendo altos padrões de precisão do modelo.
SageMaker O Estimator treina os algoritmos fornecidos pelo zoológico PyTorch modelo em um AWS Deep Learning Containers com PyTorch estrutura, e o Debugger extrai métricas de treinamento do processo de treinamento.
O vídeo também demonstra como configurar uma regra personalizada do Debugger para observar a precisão de um modelo removido, acionar um CloudWatch evento e uma AWS Lambda função da Amazon quando a precisão atingir um limite e interromper automaticamente o processo de remoção para evitar iterações redundantes.
Os objetivos de aprendizagem são os seguintes:
-
Saiba como usar SageMaker para acelerar o treinamento do modelo de ML e melhorar a qualidade do modelo.
-
Entenda como gerenciar as iterações de treinamento com o SageMaker Experiments capturando automaticamente os parâmetros de entrada, as configurações e os resultados.
-
Descubra como o Debugger torna o processo de treinamento transparente capturando automaticamente dados de tensores em tempo real a partir de métricas como pesos, gradientes e saídas de ativação de redes neurais convolucionais.
-
Use CloudWatch para acionar o Lambda quando o Debugger detecta problemas.
-
Domine o processo SageMaker de treinamento usando o SageMaker Experiments and Debugger.
Você pode encontrar os cadernos e scripts de treinamento usados neste vídeo do SageMaker Debugger PyTorch
A imagem a seguir mostra como o processo de remoção iterativa do AlexNet modelo reduz o tamanho ao cortar os 100 filtros menos significativos com base na classificação de importância avaliada pelas saídas de ativação e gradientes.
O processo de redução diminuiu os 50 milhões de parâmetros iniciais para 18 milhões. Também reduziu o tamanho estimado do modelo de 201 MB para 73 MB.
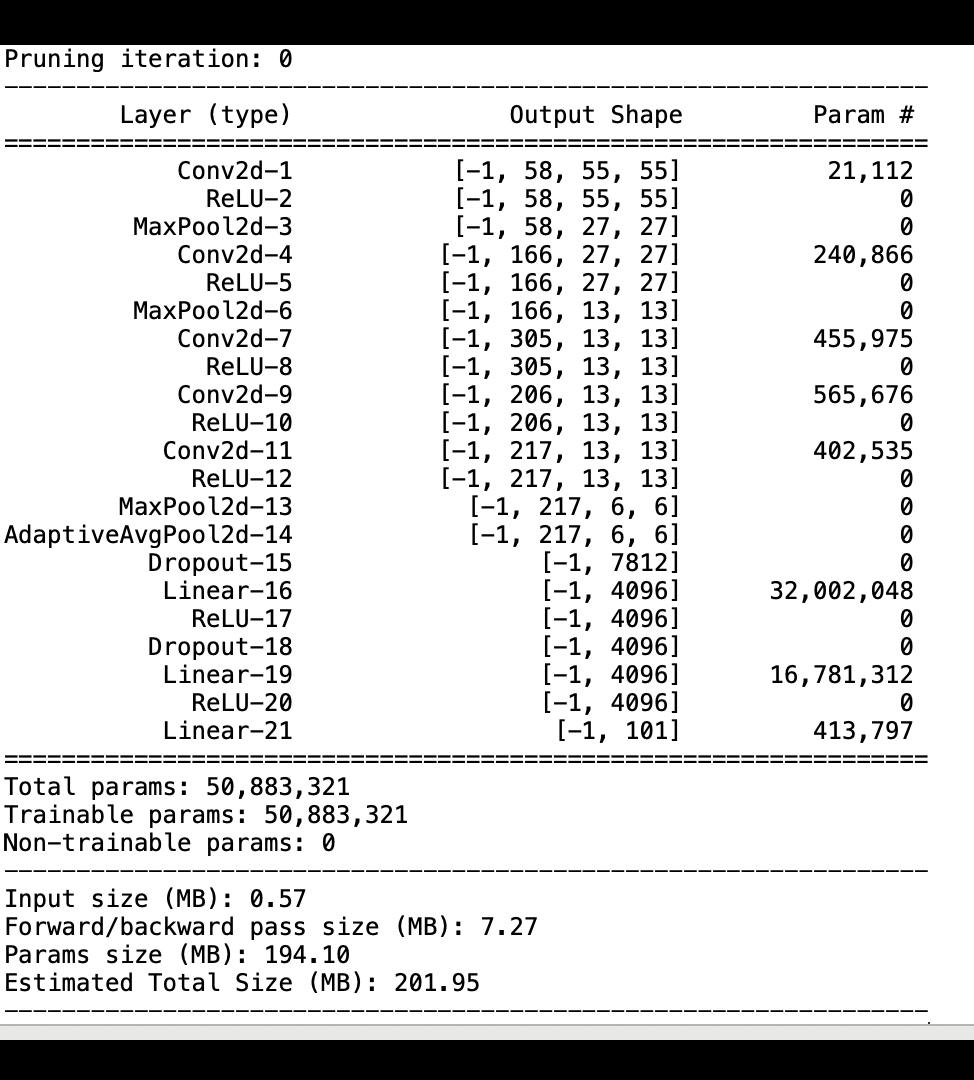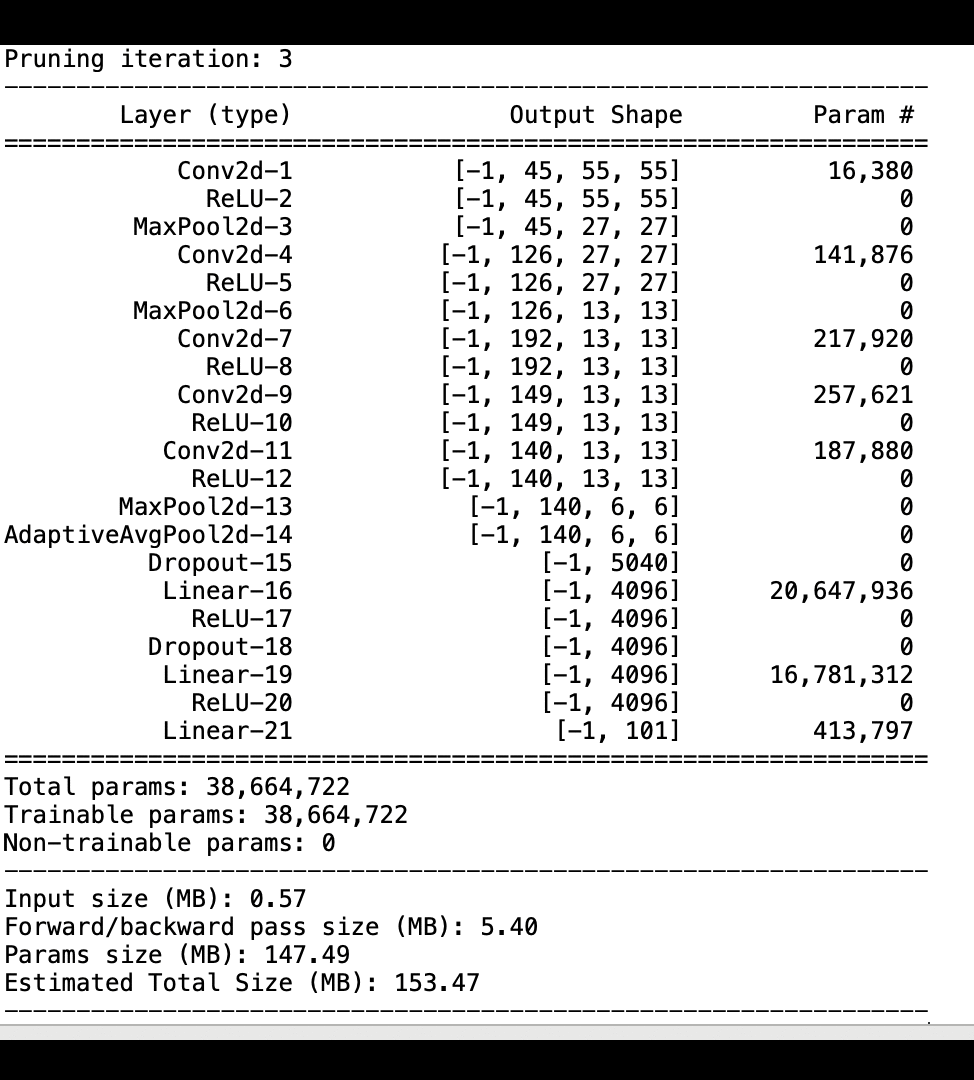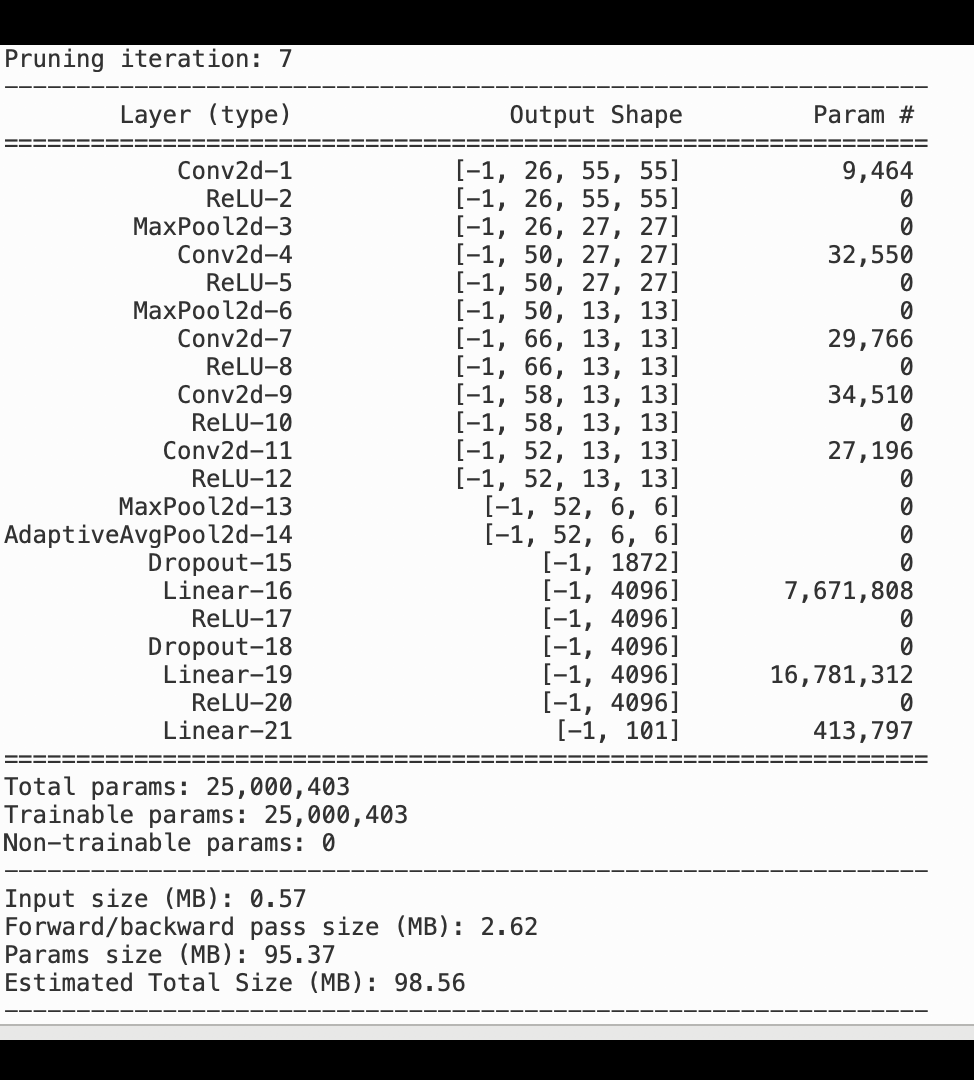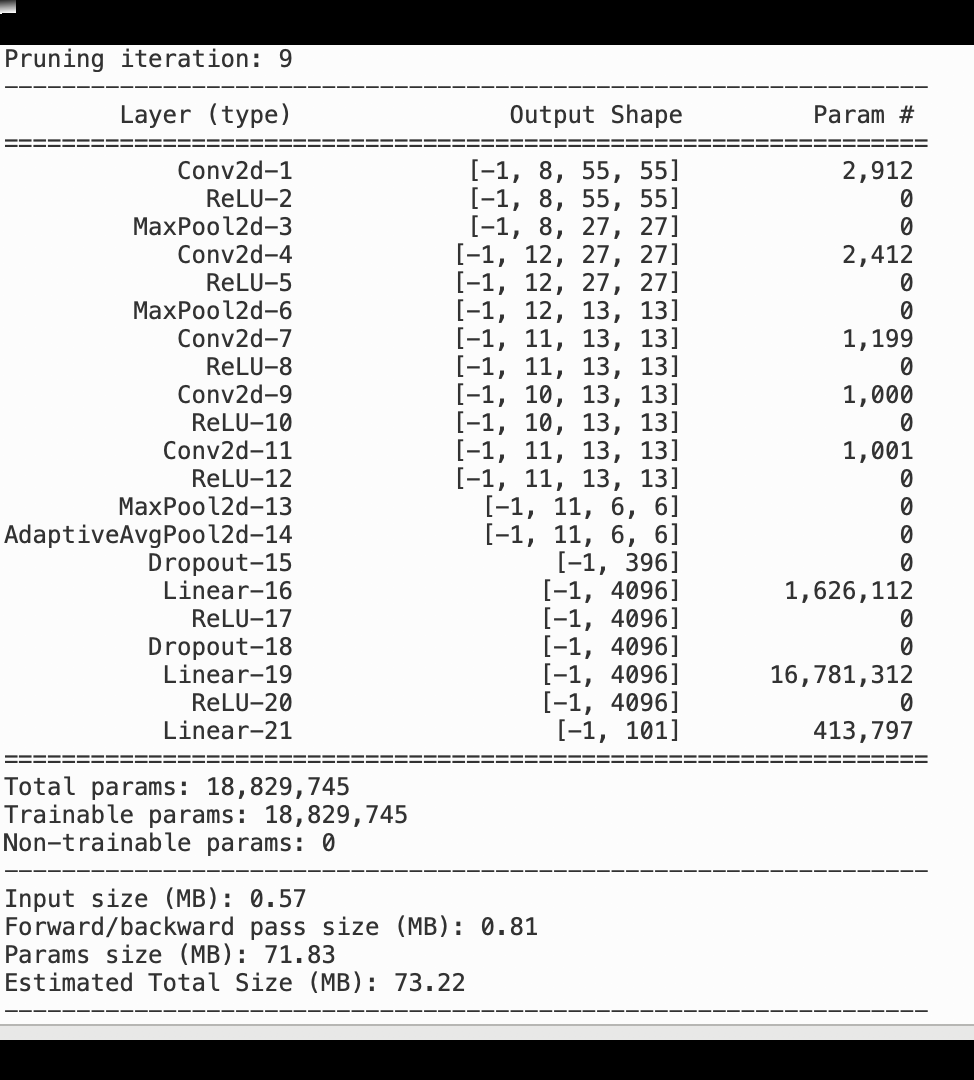
Você também precisa monitorar a precisão do modelo, e a imagem a seguir mostra como você pode traçar o processo de poda do modelo para visualizar as alterações na precisão do modelo com base no número de parâmetros no SageMaker Studio.
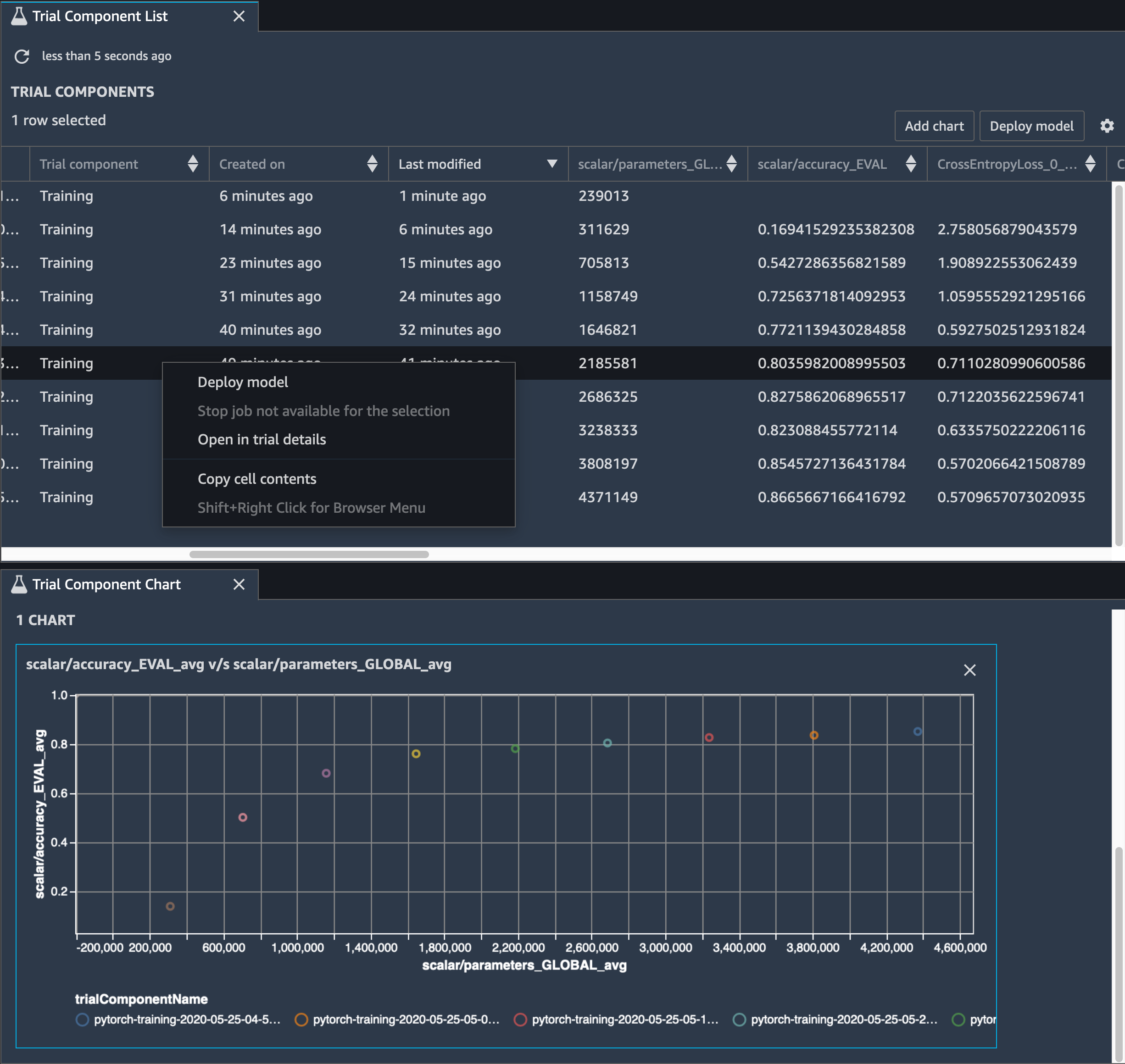
No SageMaker Studio, escolha a guia Experimentos, selecione uma lista de tensores salvos pelo Debugger no processo de poda e, em seguida, crie um painel Lista de componentes de teste. Selecione todas as 10 iterações e escolha Adicionar gráfico para criar um Gráfico de componentes de teste. Depois de decidir sobre um modelo a ser implantado, escolha o componente de teste e escolha um menu para realizar uma ação ou escolha Implantar modelo.
nota
Para implantar um modelo por meio do SageMaker Studio usando o exemplo de notebook a seguir, adicione uma linha no final da train função no train.py script.
# In the train.py script, look for the train function in line 58. def train(epochs, batch_size, learning_rate): ... print('acc:{:.4f}'.format(correct/total)) hook.save_scalar("accuracy", correct/total, sm_metric=True) # Add the following code to line 128 of the train.py script to save the pruned models # under the current SageMaker Studio model directorytorch.save(model.state_dict(), os.environ['SM_MODEL_DIR'] + '/model.pt')
Usando o SageMaker Debugger para monitorar um treinamento de modelo de autoencoder convolucional
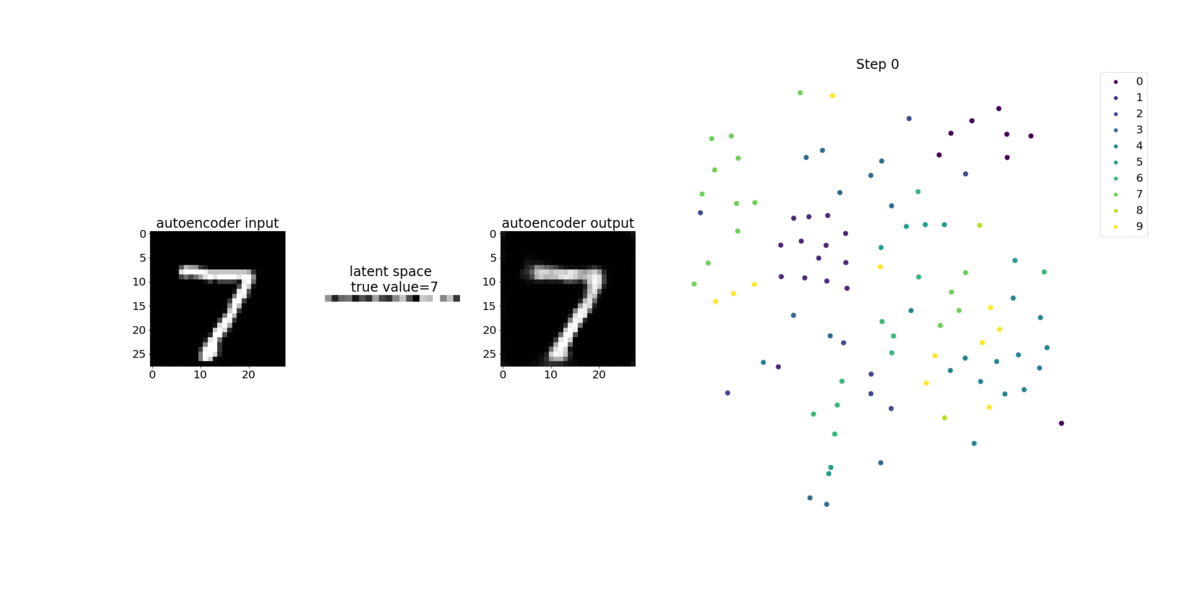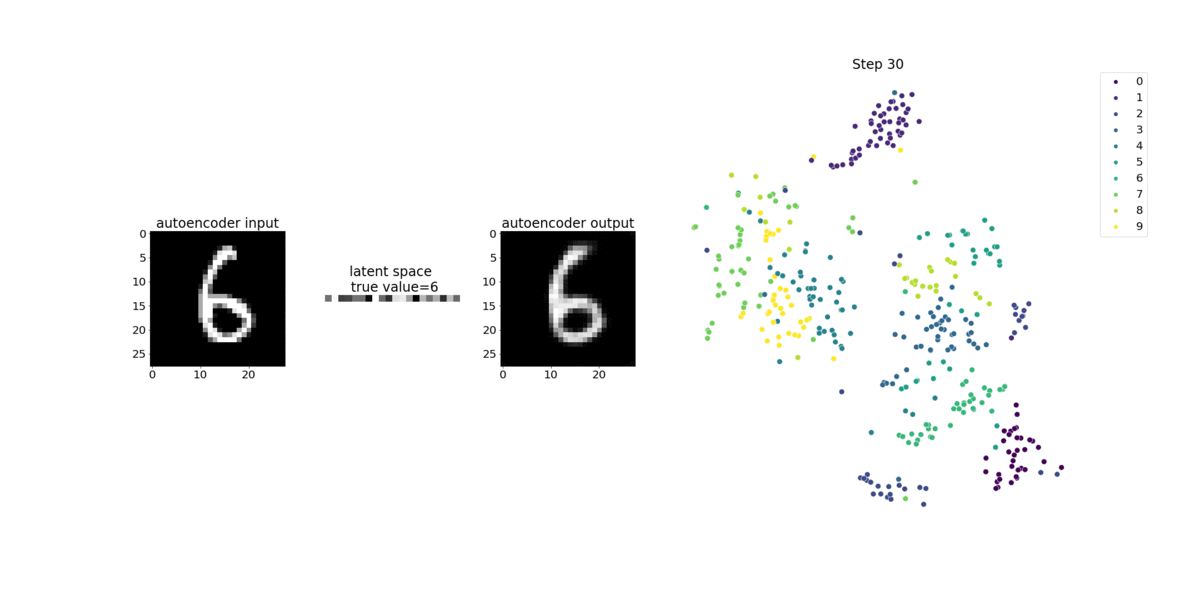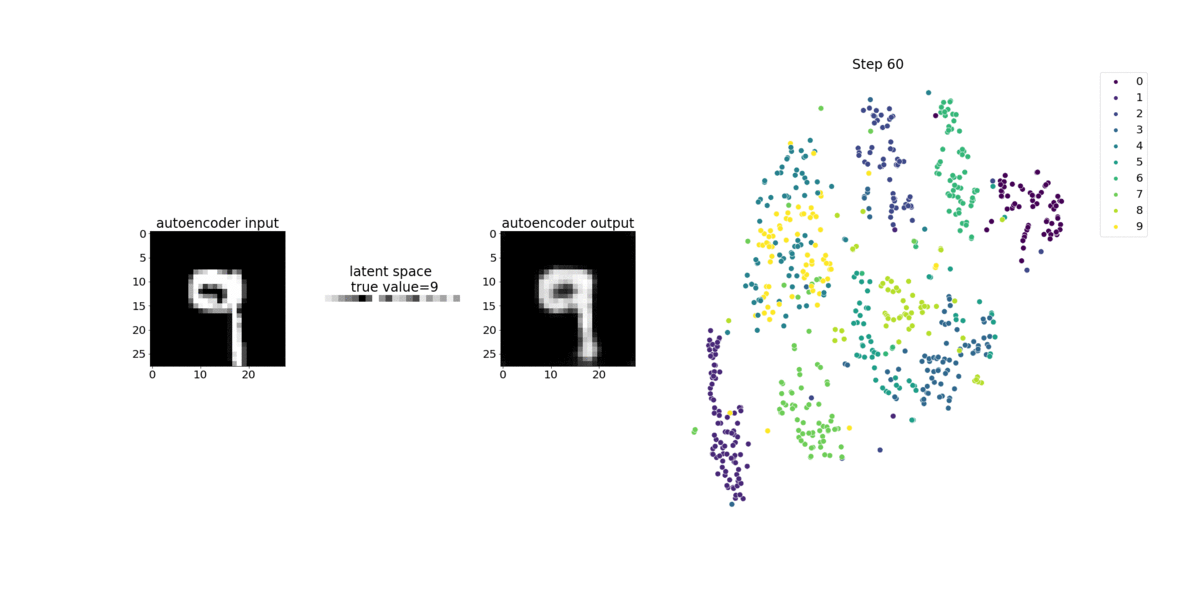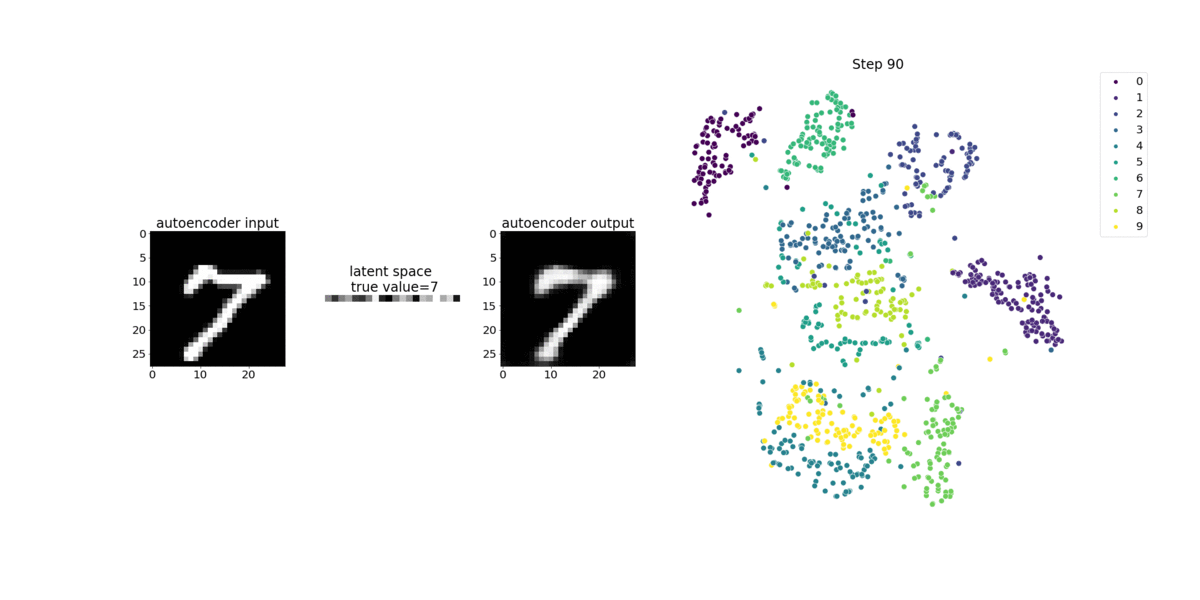
Este caderno demonstra como o SageMaker Debugger visualiza tensores de um processo de aprendizado não supervisionado (ou autosupervisionado) em um conjunto de dados de imagens MNIST de números manuscritos.
O modelo de treinamento neste bloco de anotações é um codificador automático convolucional com a estrutura de trabalho MXNet. O codificador automático convolucional tem uma rede neural convolucional em forma de gargalo que consiste em uma parte codificadora e uma parte decodificadora.
O codificador neste exemplo tem duas camadas de convolução para produzir uma representação compactada (variáveis latentes) das imagens de entrada. Neste caso, o codificador produz uma variável latente de tamanho (1, 20) a partir de uma imagem de entrada original de tamanho (28, 28) e reduz significativamente o tamanho dos dados para treinamento em 40 vezes.
O decodificador tem duas camadas desconvolucionais e garante que as variáveis latentes preservem informações importantes reconstruindo imagens de saída.
O codificador convolucional alimenta algoritmos de agrupamento com tamanho menor de dados de entrada e o desempenho de algoritmos de agrupamento, como k-means, K-NN e t-Distributed Stochastic Neighbor Embedding (t-SNE).
Este exemplo de bloco de anotações demonstra como visualizar as variáveis latentes usando o Debugger, como mostrado na animação a seguir. Ele também demonstra como o algoritmo t-SNE classifica as variáveis latentes em 10 clusters e as projeta em um espaço bidimensional. O esquema de cores do gráfico de dispersão no lado direito da imagem reflete os valores verdadeiros para mostrar a eficiência com que o modelo BERT e o algoritmo t-SNE organizam as variáveis latentes nos clusters.
Usando o SageMaker Debugger para monitorar as atenções no treinamento do modelo BERT
Bidiretional Encode Representations from Transformers (BERT) é um modelo de representação de linguagem. Como reflete o nome do modelo, o modelo BERT baseia-se na aprendizagem de transferência e no modelo Transformer para processamento de linguagem natural (NLP).
O modelo BERT é pré-treinado em tarefas não supervisionadas, como prever palavras ausentes em uma frase ou prever a próxima frase que naturalmente segue uma frase anterior. Os dados de treinamento contêm 3,3 bilhões de palavras (tokens) de texto em inglês, de fontes como Wikipédia e livros eletrônicos. Para obter um exemplo simples, o modelo BERT pode dar uma grande atenção aos tokens de verbo apropriados ou tokens de pronome de um token de assunto.
O modelo BERT pré-treinado pode ser ajustado com uma camada de saída adicional para obter treinamento de state-of-the-art modelo em tarefas de PNL, como respostas automatizadas a perguntas, classificação de texto e muitas outras.
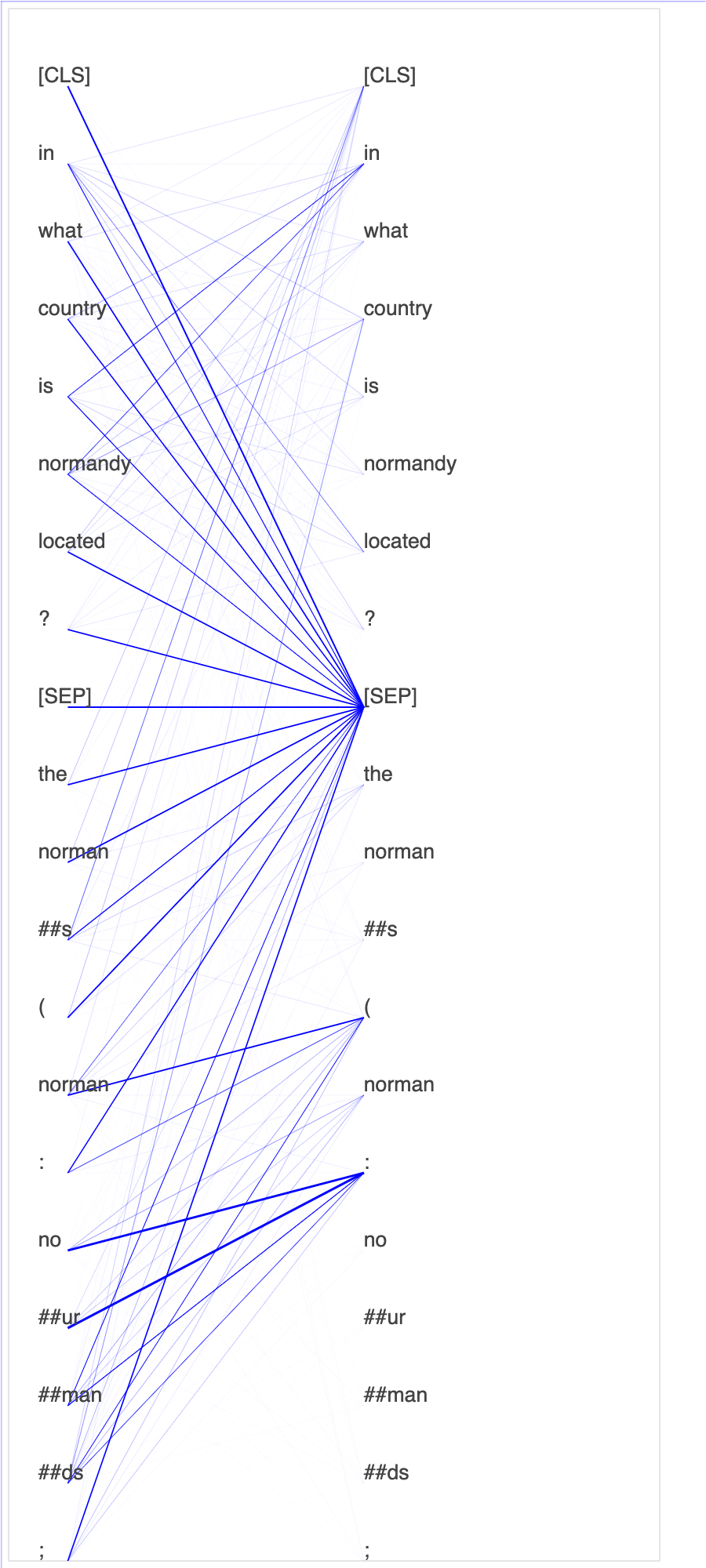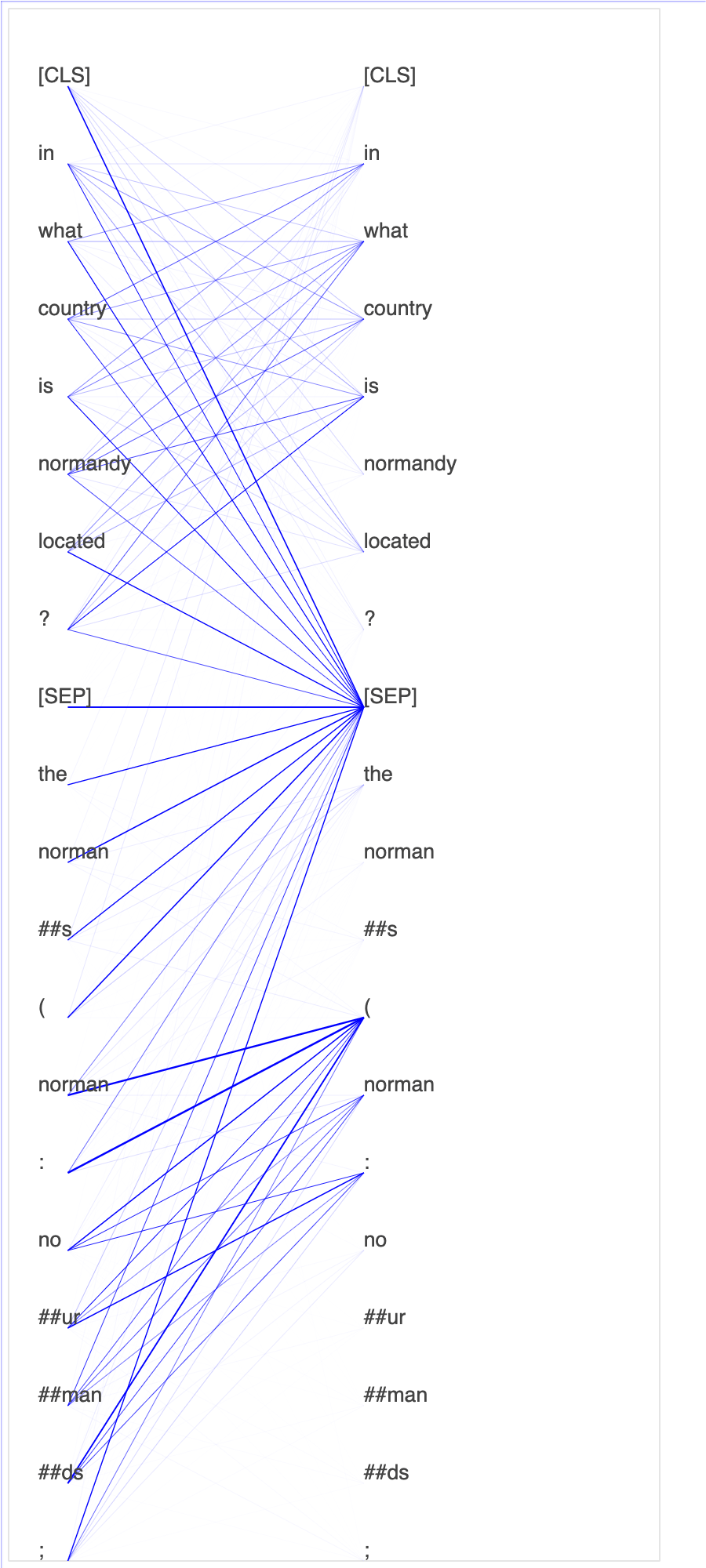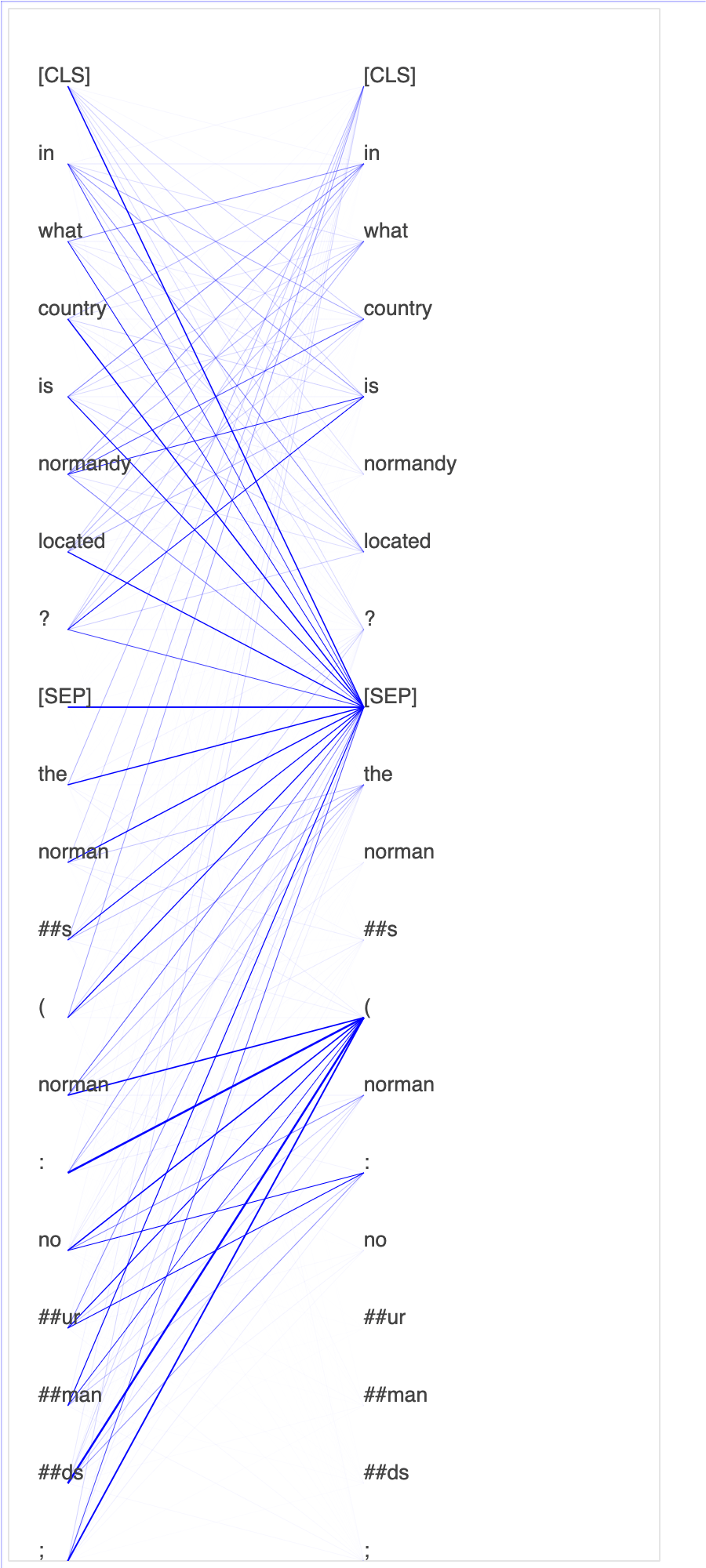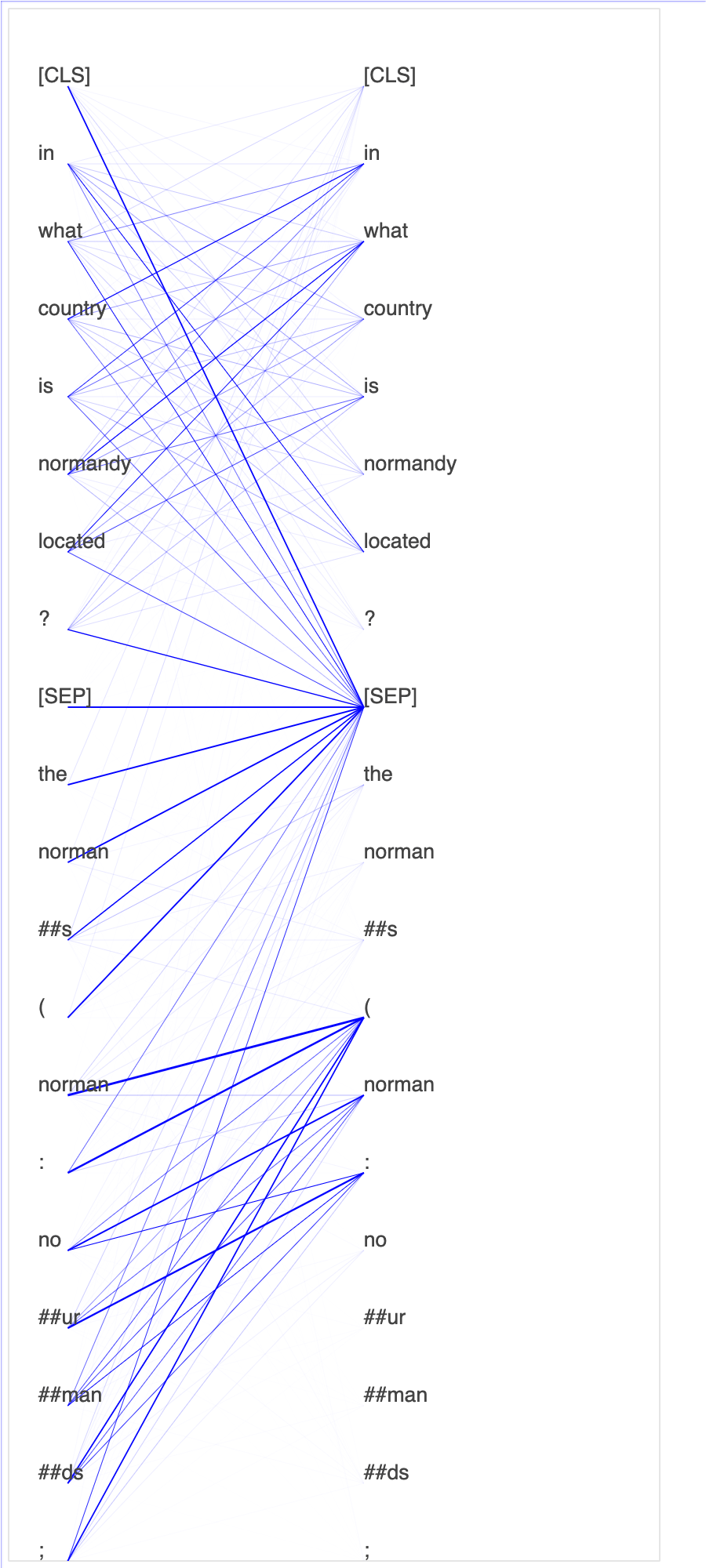
O Debugger coleta tensores do processo de ajuste fino. No contexto do PLN, o peso dos neurônios chama atenção.
Este caderno demonstra como usar o modelo BERT pré-treinado do zoológico modelo GluonNLP
Traçar pontuações de atenção e neurônios individuais na consulta e vetores chave pode ajudar a identificar causas de predições incorretas do modelo. Com o SageMaker Debugger, você pode recuperar os tensores e traçar a visão da cabeça de atenção em tempo real à medida que o treinamento avança e entender o que o modelo está aprendendo.
A animação a seguir mostra as pontuações de atenção dos primeiros 20 tokens de entrada para 10 iterações no trabalho de treinamento fornecido no exemplo do bloco de anotações.
Usando o SageMaker Debugger para visualizar mapas de ativação de classes em redes neurais convolucionais (CNNs)
Este notebook demonstra como usar o SageMaker Debugger para traçar mapas de ativação de classes para detecção e classificação de imagens em redes neurais convolucionais (CNNs). No aprendizado profundo, uma rede neural convolucional (CNN ou ConvNet) é uma classe de redes neurais profundas, mais comumente aplicada à análise de imagens visuais. Uma das aplicações que adota os mapas de ativação de classe é o caso dos veículos autônomos, que exigem detecção instantânea e classificação de imagens, como sinais de trânsito, estradas e obstáculos.
Neste notebook, o PyTorch ResNet modelo é treinado no conjunto de dados alemão de sinais de trânsito
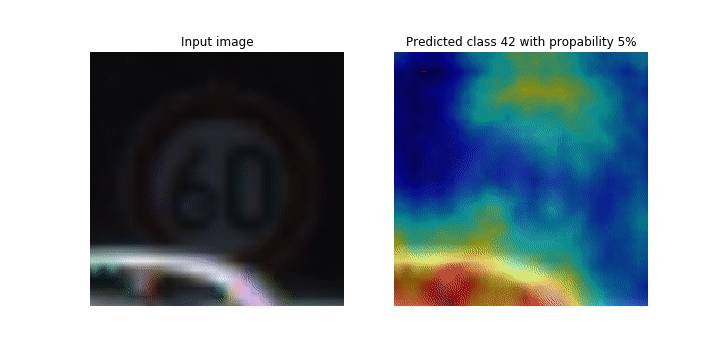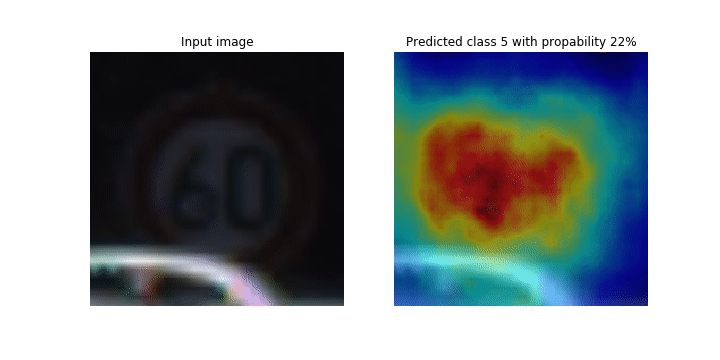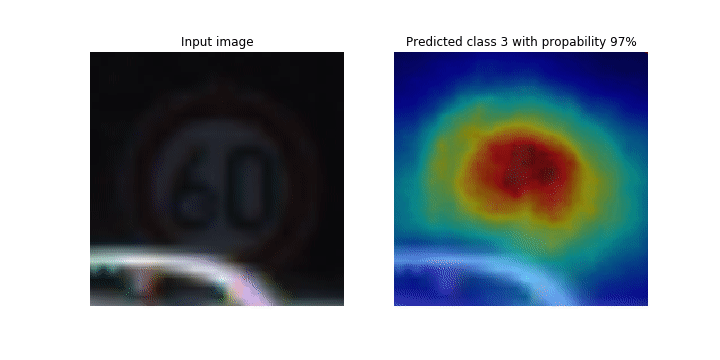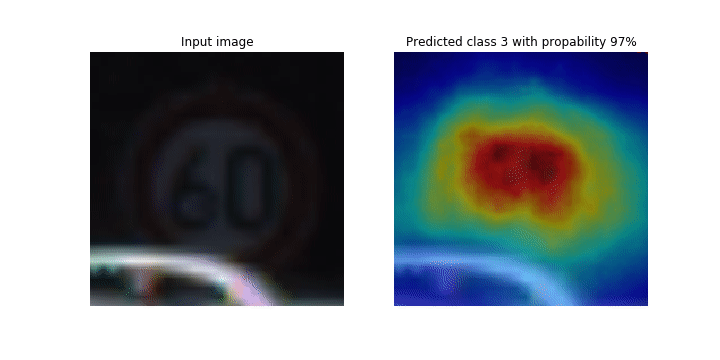
Durante o processo de treinamento, o SageMaker Debugger coleta tensores para traçar os mapas de ativação da classe em tempo real. Como mostrado na imagem animada, o mapa de ativação de classe (também chamado de mapa de saliência) destaca regiões com alta ativação na cor vermelha.
Ao usar os tensores capturados pelo Debugger, você pode visualizar como o mapa de ativação evolui durante o treinamento do modelo. O modelo começa detectando a borda no canto inferior esquerdo no início do trabalho de treinamento. À medida que o treinamento progride, o foco muda para o centro e detecta o sinal de limite de velocidade, e o modelo prevê com êxito a imagem de entrada como Classe 3, que é uma classe de sinais de limite de velocidade de 60 km/h, com um nível de confiança de 97%.
