As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Use o algoritmo de SageMaker previsão AI DeepAR
O algoritmo de previsão Amazon SageMaker AI DeepAR é um algoritmo de aprendizado supervisionado para prever séries temporais escalares (unidimensionais) usando redes neurais recorrentes (RNN). Os métodos clássicos de previsão, como média móvel integrada autorregressiva (ARIMA) ou suavização exponencial (ETS), definem um único modelo para cada série temporal individual. Em seguida, eles usam esse modelo para extrapolar séries temporais no futuro.
Em muitas aplicações, no entanto, você pode ter muitas séries temporais semelhantes em um conjunto de unidades transversais. Por exemplo, você pode ter agrupamentos de séries temporais para a demanda por diferentes produtos, cargas de servidores e solicitações de páginas da Web. Para esse tipo de aplicação, é possível se beneficiar com o treinamento de um único modelo de forma conjunta em todas as séries temporais. O DeepAR adota essa abordagem. Quando seu conjunto de dados contém centenas de séries temporais relacionadas, o DeepAR supera os métodos padrão ARIMA e ETS. Você também pode usar o modelo treinado para gerar previsões para novas séries temporais semelhantes às que foram treinadas.
A entrada de treinamento para o algoritmo DeepAR é de uma ou, preferencialmente, mais séries temporais target que foram geradas pelo mesmo processo ou processos semelhantes. Com base nesse conjunto de dados de entrada, o algoritmo treina um modelo que aprende uma aproximação desse processo/processos e o usa para prever a evolução das séries temporais de destino. Cada série temporal de destino pode ser opcionalmente associada a um vetor de atributos categóricos estáticos (independente do tempo) fornecido pelo campo cat e a um vetor de séries temporais dinâmicas (dependente do tempo) fornecido pelo campo dynamic_feat. SageMaker A IA treina o modelo DeepAR amostrando aleatoriamente exemplos de treinamento de cada série temporal alvo no conjunto de dados de treinamento. Cada exemplo de treinamento consiste em um par de janelas de predição e contexto adjacentes com comprimentos predefinidos fixos. Para controlar até que ponto no passado a rede pode se estender, use o hiperparâmetro context_length. Para controlar até que ponto no futuro é possível fazer predições, use o hiperparâmetro prediction_length. Para obter mais informações, consulte Como o algoritmo DeepAR funciona.
Tópicos
Interface de entrada/saída para o algoritmo DeepAR
O DeepAR é compatível com dois canais de dados. O canal necessário train descreve o conjunto de dados de treinamento. O canal opcional test descreve um conjunto de dados que o algoritmo usa para avaliar a precisão do modelo após o treinamento. Você pode fornecer conjuntos de dados de treinamento e teste no formato de linhas JSON
Ao especificar os caminhos para os dados de treinamento e teste, você pode especificar um único arquivo ou um diretório que contenha vários arquivos, que podem ser armazenados em subdiretórios. Se você especificar um diretório, o DeepAR usará todos os arquivos nesse diretório como entradas para o canal correspondente, exceto aqueles que começam com um ponto (.) e aqueles denominados _SUCCESS. Isso garante que você possa usar diretamente as pastas de saída produzidas por trabalhos do Spark como canais de entrada para seus trabalhos de treinamento do DeepAR.
Por padrão, o modelo DeepAR determina o formato de entrada da extensão do arquivo (.json, .json.gz ou .parquet) no caminho de entrada especificado. Se o caminho não terminar em uma dessas extensões, você deverá especificar explicitamente o formato no SDK for Python. Use o parâmetro content_type da classe s3_input classe
Os registros nos seus arquivos de entrada devem conter os seguintes campos:
-
start: Uma string com o formatoYYYY-MM-DD HH:MM:SS. O timestamp inicial não pode conter informações de fuso horário. -
target: Uma matriz de valores de ponto flutuante ou números inteiros que representam a série temporal. Você pode codificar valores ausentes como literaisnullou como strings"NaN"em JSON ou como valores de ponto flutuantenanem Parquet. -
dynamic_feat(opcional): Uma matriz de matrizes de valores de ponto flutuante ou números inteiros que representam o vetor de séries temporais de atributos personalizados (atributos dinâmicos). Se você definir esse campo, todos os registros deverão ter o mesmo número de matrizes internas (o mesmo número de séries temporais de atributos). Além disso, cada matriz interna deve ter o mesmo comprimento que o valortargetassociadoprediction_length. Os atributos não são compatíveis com valores ausentes. Por exemplo, se as séries temporais de destino representam a demanda de diferentes produtos, umdynamic_featassociado pode ser uma série temporal booleana que indica se uma promoção foi aplicada (1) a determinado produto ou não (0):{"start": ..., "target": [1, 5, 10, 2], "dynamic_feat": [[0, 1, 1, 0]]} -
cat(opcional): Uma matriz de atributos categóricos que podem ser usados para codificar os grupos aos quais o registro pertence. Atributos categóricos devem ser codificados como uma sequência baseada em 0 de números inteiros positivos. Por exemplo, o domínio categórico {R, G, B} pode ser codificado como {0, 1, 2}. Todos os valores de cada domínio categórico devem ser representados no conjunto de dados de treinamento. Isso porque o algoritmo DeepAR pode prever apenas as categorias que foram observadas durante o treinamento. E cada atributo categórico é incorporado em um espaço de baixa dimensão cuja dimensionalidade é controlada pelo hiperparâmetroembedding_dimension. Para obter mais informações, consulte Hiperparâmetros do DeepAR.
Se você usar um arquivo JSON, ele deverá estar no formato JSON Lines
{"start": "2009-11-01 00:00:00", "target": [4.3, "NaN", 5.1, ...], "cat": [0, 1], "dynamic_feat": [[1.1, 1.2, 0.5, ...]]} {"start": "2012-01-30 00:00:00", "target": [1.0, -5.0, ...], "cat": [2, 3], "dynamic_feat": [[1.1, 2.05, ...]]} {"start": "1999-01-30 00:00:00", "target": [2.0, 1.0], "cat": [1, 4], "dynamic_feat": [[1.3, 0.4]]}
Neste exemplo, cada série temporal tem dois atributos categóricos associados e um atributo de série temporal.
Para Parquet, você usa os mesmos três campos como colunas. Além disso, "start" pode ser do tipo datetime. Você pode compactar arquivos Parquet usando a biblioteca de compactação gzip (gzip) ou Snappy (snappy).
Se o algoritmo for treinado sem os campos cat e dynamic_feat, ele aprenderá um modelo "global", que é um modelo independente da identidade específica das séries temporais de destino em tempo de inferência, e condicionado somente na forma.
Se o modelo estiver condicionado aos dados de atributos cat e dynamic_feat fornecidos para cada série temporal, a predição provavelmente será influenciada pelo caractere das séries temporais com os atributos cat correspondentes. Por exemplo, se a série temporal target representar a demanda de itens de vestuário, você poderá associar um vetor bidimensional cat que codifica o tipo de item (por exemplo, 0 = sapatos, 1 = vestimenta) no primeiro componente e a cor de um item (por exemplo, 0 = vermelho, 1 = azul) no segundo componente. Uma exemplo de entrada seria exibida da seguinte forma:
{ "start": ..., "target": ..., "cat": [0, 0], ... } # red shoes { "start": ..., "target": ..., "cat": [1, 1], ... } # blue dress
No momento da inferência, você pode solicitar predições para destinos com valores cat, que são combinações dos valores cat observados nos dados de treinamento, por exemplo:
{ "start": ..., "target": ..., "cat": [0, 1], ... } # blue shoes { "start": ..., "target": ..., "cat": [1, 0], ... } # red dress
As diretrizes a seguir se aplicam a dados de treinamento:
-
O horário de início e a duração da série temporal podem ser diferentes. Por exemplo, na comercialização, os produtos geralmente entram no catálogo de varejo em datas diferentes, portanto, as datas de início diferem naturalmente. No entanto, todas as séries devem ter a mesma frequência, número de atributos categóricos e número de atributos dinâmicos.
-
Embaralhe o arquivo de treinamento em relação à posição da série temporal no arquivo. Em outras palavras, a série temporal deve ocorrer em ordem aleatória no arquivo.
-
Certifique-se de definir o campo
startcorretamente. O algoritmo usa o timestampstartpara derivar os atributos internos. -
Se você usar atributos categóricos (
cat), todas as séries temporais deverão ter o mesmo número de atributos categóricos. Se o conjunto de dados contiver o campocat, o algoritmo o usará e extrairá a cardinalidade dos grupos do conjunto de dados. Por padrão,cardinalityé"auto". Se o conjunto de dados contiver o campocat, mas você não quiser usá-lo, poderá desabilitá-lo definindocardinalitycomo"". Se um modelo tiver sido treinado usando um atributocat, você deverá incluí-lo para inferência. -
Se o seu conjunto de dados contiver o campo
dynamic_feat, o algoritmo o usará automaticamente. Todas as séries temporais precisam ter o mesmo número de séries temporais de atributos. Os pontos de tempo em cada uma das séries temporais do recurso correspondem one-to-one aos pontos de tempo no alvo. Além disso, a entrada no campodynamic_featdeve ter o mesmo comprimento quetarget. Se o conjunto de dados contiver o campodynamic_feat, mas você não quiser usá-lo, desabilite-o definindo (num_dynamic_featcomo""). Se o modelo tiver sido treinado com o campodynamic_feat, você deverá fornecer esse campo para inferência. Além disso, cada um dos atributos deve ter o comprimento do destino fornecido mais oprediction_length. Em outras palavras, você deverá fornecer o valor do atributo no futuro.
Se você especificar os dados do canal teste opcional, o algoritmo DeepAR avaliará o modelo treinado com diferentes métricas de precisão. O algoritmo calculará a raiz do erro quadrático médio (RMSE) nos dados de teste da seguinte forma:
-y(i,t))^2))](images/deepar-1.png)
yi,t é o verdadeiro valor da série temporal i no momento t. ŷi,t é a predição média. A soma refere-se a todas as séries temporais n no conjunto de teste e aos últimos momentos Τ de cada série temporal, em que Τ corresponde ao horizonte de previsão. Para especificar a extensão do horizonte de previsão, defina o hiperparâmetro prediction_length. Para obter mais informações, consulte Hiperparâmetros do DeepAR.
Além disso, o algoritmo avalia a precisão da distribuição da previsão usando a perda de quantil ponderada. Para um quantil no intervalo [0, 1], a perda de quantil ponderada é definida da seguinte forma:
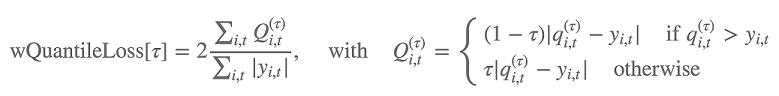
qi,t(τ) é o quantil τ da distribuição que o modelo prevê. Para especificar para quais quantis calcular a perda, defina o hiperparâmetro test_quantiles. Além destes, a média das perdas de quantil prescritas é relatada como parte dos logs de treinamento. Para ter mais informações, consulte Hiperparâmetros do DeepAR.
Para inferência, o DeepAR aceita o formato JSON e os seguintes campos:
-
"instances", que inclui uma ou mais séries temporais no formato JSON Lines -
Um nome de
"configuration", que inclui parâmetros para gerar a previsão
Para obter mais informações, consulte Formatos de inferência do DeepAR.
Melhores práticas para usar o algoritmo DeepAR
Ao preparar seus dados de série temporal, siga estas práticas recomendadas para obter os melhores resultados:
-
Exceto ao dividir seu conjunto de dados para treinamento e teste, sempre forneça toda a série temporal para treinamento, teste e ao chamar o modelo para inferência. Independentemente de como você definir
context_length, não divida a série temporal ou forneça apenas uma parte dela. O modelo usa pontos de dados mais atrás do que o valor definido emcontext_lengthpara o atributo de valores com atraso. -
Ao ajustar um modelo DeepAR, você pode dividir o conjunto de dados para criar um conjunto de dados de treinamento e um conjunto de dados de teste. Em uma avaliação típica, você testaria o modelo na mesma série temporal usada para treinamento, mas nos pontos de tempo
prediction_lengthfuturos que seguem imediatamente depois do último ponto de tempo visível durante o treinamento. É possível criar conjuntos de dados de treinamento e teste que atendem a esse critério usando o conjunto de dados inteiro (a duração total de todas as séries temporais disponíveis) como um conjunto de testes e removendo os últimos pontosprediction_lengthde cada série temporal para treinamento. Durante o treinamento, o modelo não vê os valores de destino para os pontos de tempo em que ele é avaliado durante o teste. Durante o teste, o algoritmo retém os últimos pontosprediction_lengthde cada série temporal do conjunto de testes e gera uma predição. Em seguida, ele compara a previsão com os valores retidos. Você pode criar avaliações mais complexas repetindo as séries temporais várias vezes no conjunto de testes, mas cortando-as em diferentes endpoints. Com essa abordagem, a média de métricas de precisão é calculada sobre várias previsões de diferentes pontos de tempo. Para obter mais informações, consulte Ajustar um modelo DeepAR. -
Evite usar valores muito grandes (>400) para
prediction_length, pois isso torna o modelo lento e menos preciso. Se quiser prever mais para o futuro, considere agregar seus dados em uma frequência mais baixa. Por exemplo, use5minem vez de1min. -
Como atrasos são usados, um modelo pode retornar ainda mais na série temporal do que o valor especificado para
context_length. Portanto, você não precisa definir esse parâmetro como um valor grande. Recomendamos começar com o valor que você usou paraprediction_length. -
Recomendamos treinar um modelo DeepAR em todas as séries temporais que estiverem disponíveis. Embora um modelo DeepAR treinado em uma única série temporal possa funcionar bem, os algoritmos de previsão padrão, como o ARIMA ou o ETS, podem fornecer resultados mais precisos. O algoritmo DeepAR começa a superar os métodos padrão quando seu conjunto de dados contém centenas de séries temporais relacionadas. Atualmente, o DeepAR requer que o número total de observações disponíveis em todas as séries temporais de treinamento seja pelo menos 300.
EC2 Recomendações de instância para o algoritmo DeepAR
Você pode treinar o DeepAR em instâncias de GPU e CPU e em configurações de uma ou várias máquinas. Recomendamos começar com uma única instância de CPU (por exemplo, ml.c4.2xlarge ou ml.c4.4xlarge) e alternar para instâncias de GPU e várias máquinas somente quando necessário. O uso GPUs de várias máquinas melhora a produtividade somente em modelos maiores (com muitas células por camada e muitas camadas) e em minilotes grandes (por exemplo, maiores que 512).
Para inferência, o DeepAR oferece apoio apenas para instâncias de CPU.
A especificação de valores grandes para context_length, prediction_length, num_cells, num_layers ou mini_batch_size pode criar modelos muito grandes para instâncias pequenas. Nesse caso, use um tipo de instância maior ou reduza os valores para esses parâmetros. Esse problema também ocorre com frequência ao executar trabalhos de ajuste de hiperparâmetros. Nesse caso, use um tipo de instância grande o suficiente para o trabalho de ajuste de modelo e considere limitar os valores superiores dos parâmetros críticos para evitar falhas de trabalho.
Cadernos de amostra do DeepAR
Para ver um exemplo de caderno que mostra como preparar um conjunto de dados de séries temporais para treinar o algoritmo SageMaker AI DeepAR e como implantar o modelo treinado para realizar inferências, consulte a demonstração do DeepAR sobre o conjunto de dados de eletricidade
Para obter mais informações sobre o algoritmo Amazon SageMaker AI DeepAR, consulte as seguintes postagens no blog:
