As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Conceitos do Feature Store
Listamos termos comuns usados na Amazon SageMaker Feature Store, seguidos por exemplos de diagramas para visualizar alguns conceitos:
-
Feature Store: camada de gerenciamento de dados e armazenamento para atributos de machine learning (ML). Serve como a única fonte confiável para armazenar, recuperar, remover, rastrear, compartilhar, descobrir e controlar o acesso aos atributos. No diagrama de exemplo a seguir, o Feature Store é um armazenamento para seus grupos de atributos, que contém seus dados de ML e fornece serviços adicionais.
-
Armazenamento on-line: armazenamento de baixa latência e alta disponibilidade para um grupo de atributos que permite a pesquisa de registros em tempo real. O armazenamento on-line permite acesso rápido ao registro mais recente por meio da API
GetRecord. -
Armazenamento offline: armazena dados históricos em seu bucket do Amazon S3. O armazenamento offline é usado quando leituras de baixa latência (menos de um segundo) não são necessárias. Por exemplo, o armazenamento offline pode ser usado quando você deseja armazenar e oferecer atributos para exploração, treinamento de modelos e inferência em lote.
-
Grupo de atributos: principal atributo do Feature Store que contém os dados e metadados usados para treinamento ou previsão com um modelo de ML. Um grupo de atributos é um agrupamento lógico de atributos usados para descrever registros. No diagrama de exemplo a seguir, um grupo de atributos contém seus dados de ML.
-
Atributo: uma propriedade que é usada como uma das entradas para treinar ou prever usando seu modelo de ML. Na API do Feature Store, um atributo é um atributo de um registro. No diagrama de exemplo a seguir, um grupo de atributos descreve uma coluna em sua tabela de dados de ML.
-
Definição de atributo: consiste em um nome e um dos tipos de dados: integral, string ou fracionário. Um grupo de atributos contém uma lista de definições de atributos. Para obter mais informações sobre tipos de dados do Feature Store, consulte Tipos de dados.
-
Registro: coleção de valores para atributos para um único identificador de registro. Uma combinação de valores de identificador de registro e horário do evento identifica exclusivamente um registro dentro de um grupo de atributos. No diagrama de exemplo a seguir, um registro é uma linha em sua tabela de dados de ML.
-
Nome do identificador do registro: o nome do identificador do registro é o nome do atributo que identifica os registros. Ele deve se referir a um dos nomes de um atributo definido nas definições de atributo do grupo de atributos. Cada grupo de atributos é definido com um nome do identificador de registro.
-
Horário do evento: carimbo de data/hora que você fornece correspondente à data em que o evento de registro ocorreu. Todos os registros no grupo de atributos devem ter um horário de evento correspondente. O armazenamento on-line contém apenas o registro correspondente ao horário do evento mais recente, enquanto o armazenamento offline contém todos os registros históricos. Para obter mais informações sobre os formatos de horário do evento, consulte Tipos de dados.
-
Ingestão: adição de novos registros a um grupo de atributos. Normalmente, a ingestão é obtida por meio da API
PutRecord.
Diagrama de visão geral dos conceitos
O diagrama de seguinte exemplo conceitua alguns conceitos do Feature Store:

O Feature Store contém seus grupos de atributos e um grupo de atributos contém seus dados de ML. No diagrama de exemplo, o grupo de atributos original contém uma tabela de dados com três atributos (cada um descrevendo uma coluna) e dois registros (linhas).
-
A definição de um atributo descreve o nome do atributo e o tipo de dados dos valores do atributo associados aos registros.
-
Um registro contém os valores do atributo e é identificado exclusivamente por seu identificador de registro e deve incluir o horário do evento.
Diagramas de ingestão
A ingestão é a ação de adicionar um registro ou registros a um grupo de atributos existente. Os armazenamentos on-line e offline são atualizados de forma diferente dependendo do caso de uso.
Exemplo de ingestão no armazenamento on-line
A loja online funciona como uma pesquisa em tempo real dos registros e mantém apenas a maioria dos up-to-date registros. Depois que um registro for inserido em um armazenamento on-line existente, o armazenamento on-line atualizado só manterá o registro com o horário mais recente do evento.
No diagrama de exemplo a seguir, o armazenamento on-line original contém sua tabela de dados de ML com um registro. Um registro é ingerido com o mesmo ID do registro original, mas o novo registro tem o horário do evento anterior ao registro original. Como o armazenamento on-line atualizado mantém apenas o registro com o horário do evento mais recente, o armazenamento on-line atualizado contém o registro original.

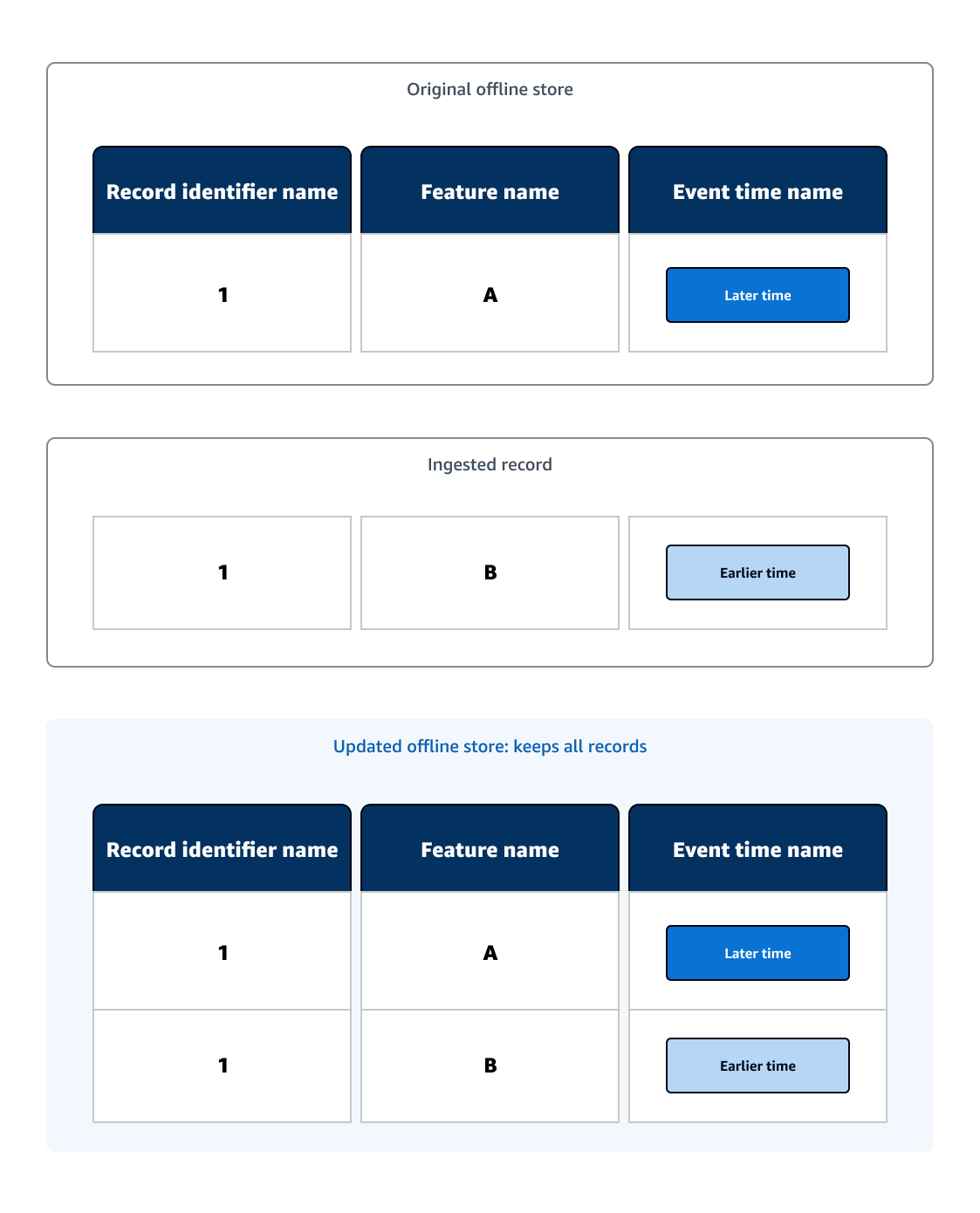
Exemplo de ingestão no armazenamento offline
O armazenamento offline atua como uma consulta histórica dos registros e mantém todos os registros. Depois que um novo registro for ingerido em um armazenamento offline existente, o armazenamento offline atualizado manterá o novo registro.
No diagrama de exemplo a seguir, o armazenamento offline original contém sua tabela de dados de ML com um registro. Um registro é ingerido com o mesmo ID do registro original, mas o novo registro tem o horário do evento anterior ao registro original. Como o armazenamento offline atualizado mantém todos os registros, o armazenamento offline atualizado contém os dois registros.