As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Como o PCA funciona
A análise de componente principal (PCA) é um algoritmo de aprendizagem que reduz a dimensionalidade (número de recursos) em um conjunto de dados enquanto mantém o maior número possível de informações.
Para reduzir a dimensionalidade, o algoritmo encontra um novo conjunto de recursos chamados componentes, que são composições de recursos originais não correlacionados entre si. O primeiro componente representa a maior variabilidade possível nos dados, o segundo componente, a segunda maior variabilidade, e assim por diante.
É um algoritmo de redução de dimensionalidade não supervisionado. Na aprendizagem não supervisionada, os rótulos que podem ser associados aos objetos do conjunto de dados de treinamento não são usados.
Dada a entrada de uma matriz com as linhas
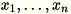 , cada uma de dimensão
, cada uma de dimensão 1 * d, os dados são particionados em minilotes de linhas e distribuídos entre os nós de treinamento (trabalhadores). Cada operador calcula então um resumo dos seus dados. Depois, os resumos dos diferentes operadores são unificados em uma só solução no final do cálculo.
Modos
O algoritmo Amazon SageMaker AI PCA usa um dos dois modos para calcular esses resumos, dependendo da situação:
-
regular: para conjuntos com dados esparsos e um número moderado de observações e recursos.
-
randomized: para conjuntos de dados com um grande número de observações e recursos. Esse modo usa um algoritmo de aproximação.
Como último passo, o algoritmo executa a decomposição de valor singular na solução unificada, de onde os principais componentes serão derivados.
Modo 1: Regular
Os trabalhadores calcula,
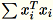 e
e
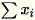 em conjunto.
em conjunto.
nota
Como
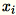 são vetores de linha
são vetores de linha 1 * d,
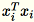 é uma matriz (não um valor escalar). O uso de vetores de linha dentro do código permite obter um cache eficiente.
é uma matriz (não um valor escalar). O uso de vetores de linha dentro do código permite obter um cache eficiente.
A matriz de covariância é calculada como
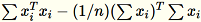 , e seus
, e seus num_components principais vetores singulares formam o modelo.
nota
Se subtract_mean for False, evitamos o cálculo e a subtração de
.
Use esse algoritmo quando a dimensão d dos vetores for pequena o suficiente para que
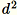 caiba na memória.
caiba na memória.
Modo 2: Randomized
Quando o número de recursos no conjunto de dados de entrada é grande, usamos um método para aproximar a métrica de covariância. Para cada minilote de dimensão
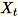 ,
, b * d inicializamos aleatoriamente uma matriz (num_components + extra_components) * b que multiplicamos por cada minilote para criar uma matriz (num_components + extra_components) * d. A soma dessas matrizes é calculada pelos operadores, e os servidores executam a decomposição de valor singular na matriz final (num_components + extra_components) * d. Os vetores singulares num_components da parte superior direita dela são a aproximação dos vetores singulares da parte superior da matriz de entrada.
Deixe
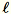
= num_components + extra_components. Dado um minilote
de dimensão b * d, o trabalhador desenha uma matriz aleatória
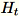 de dimensão
de dimensão
 . Dependendo se o ambiente usa uma GPU ou CPU e do tamanho da dimensão, a matriz é uma matriz de sinal aleatória, em que cada entrada é
. Dependendo se o ambiente usa uma GPU ou CPU e do tamanho da dimensão, a matriz é uma matriz de sinal aleatória, em que cada entrada é +-1 ou uma FJLT (rápida transformação de Johnson Lindenstrauss). Para obter informações, consulte o artigo sobre transformações FJLT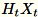 e mantém
e mantém
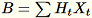 . O trabalhador também mantém
. O trabalhador também mantém
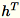 , a soma das colunas de
, a soma das colunas de
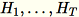 (
(T sendo o número total de minilotes) e s, a soma de todas as linhas de entrada. Depois de processar todo o estilhaço de dados, o operador envia o servidor B, h, s e n (o número de linhas de entrada).
Identifique as diferentes entradas para o servidor como
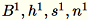 O servidor calcula
O servidor calcula B, h, s, n as somas das respectivas entradas. Em seguida, ele calcula
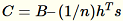 e encontra sua decomposição em valores singulares. Os vetores singulares da parte superior e os valores singulares de
e encontra sua decomposição em valores singulares. Os vetores singulares da parte superior e os valores singulares de C são usados como a solução aproximada para o problema.
