As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Ajuste um modelo
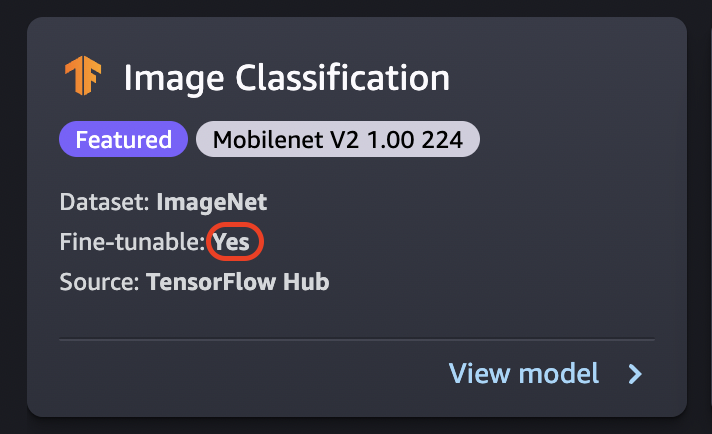
O ajuste fino treina um modelo pré-treinado em um novo conjunto de dados sem precisar ser treinado do zero. Esse processo, também conhecido como aprendizado por transferência, pode produzir modelos precisos com conjuntos de dados menores e menos tempo de treinamento. Você pode ajustar um modelo se seu cartão mostrar um atributo ajustável definido como Sim.
Importante
Em 30 de novembro de 2023, a experiência anterior do Amazon SageMaker Studio agora se chama Amazon SageMaker Studio Classic. A seção a seguir é específica ao uso da aplicação Studio Classic. Para obter informações sobre como usar a experiência atualizada do Studio, consulte SageMaker Estúdio Amazon.
nota
Para obter mais informações sobre o ajuste fino do JumpStart modelo no Studio, consulte Ajustar um modelo no Studio
Fonte de dados de ajuste fino
Ao ajustar um modelo, você pode usar o conjunto de dados padrão ou escolher seus próprios dados, que estão localizados em um bucket do Amazon S3.
Para pesquisar os buckets disponíveis para você, escolha Encontre o bucket S3. Esses buckets são limitados pelas permissões usadas para configurar sua conta do Studio Classic. Você também pode especificar um URI do Amazon S3 escolhendo Inserir localização do bucket do Amazon S3.
dica
Para descobrir como formatar os dados em seu bucket, escolha Saiba mais. A seção de descrição do modelo tem informações detalhadas sobre entradas e saídas.
Para modelos de texto:
-
O bucket deve ter um arquivo data.csv.
-
A primeira coluna deve ser um inteiro exclusivo para o rótulo da classe. Por exemplo:
1,2,3,4,n -
A segunda coluna deve conter uma string.
-
A segunda coluna deve ter o texto correspondente que corresponda ao tipo e ao idioma do modelo.
Para modelos de visão:
-
O bucket deve ter tantos subdiretórios quanto o número de classes.
-
Cada subdiretório deve conter imagens que pertençam a essa classe no formato.jpg.
nota
O bucket do Amazon S3 deve estar no mesmo Região da AWS local em que você está executando o SageMaker Studio Classic porque a SageMaker IA não permite solicitações entre regiões.
Ajuste fino da configuração de implantação
A família p3 é recomendada como a mais rápida para treinamento em aprendizado profundo, e isso é recomendado para ajustar um modelo. O gráfico a seguir mostra o número de GPUs em cada tipo de instância. Há outras opções disponíveis que você pode escolher, incluindo os tipos de instância p2 e g4.
| Tipo de instância | GPUs |
|---|---|
| p3.2xlarge | 1 |
| p3.8xlarge | 4 |
| p3.16xlarge | 8 |
| p3dn.24xlarge | 8 |
Hiperparâmetros
Você pode personalizar os hiperparâmetros do trabalho de treinamento que são usados para ajustar o modelo. Os hiperparâmetros disponíveis para cada modelo ajustável diferem dependendo do modelo. Para obter informações sobre cada hiperparâmetro disponível, consulte a documentação de hiperparâmetros do modelo de sua escolha Algoritmos integrados e modelos pré-treinados na Amazon SageMaker. Por exemplo, consulte Classificação de imagens - TensorFlow Hiperparâmetros para obter detalhes sobre a classificação de imagens ajustável - hiperparâmetros. TensorFlow
Se você usar o conjunto de dados padrão para modelos de texto sem alterar os hiperparâmetros, obterá um modelo quase idêntico como resultado. Para modelos de visão, o conjunto de dados padrão é diferente do conjunto de dados usado para treinar os modelos pré-treinados, portanto, seu modelo é diferente como resultado.
Os seguintes hiperparâmetros são comuns entre os modelos:
-
Épocas: Uma época é um ciclo em todo o conjunto de dados. Vários intervalos completam um lote, e vários lotes eventualmente completam uma época. Várias épocas são executadas até que a precisão do modelo atinja um nível aceitável ou quando a taxa de erro caia abaixo de um nível aceitável.
-
Taxa de aprendizado: A quantidade em que os valores devem ser alterados entre as épocas. À medida que o modelo é refinado, seus pesos internos são ajustados e as taxas de erro são verificadas para ver se o modelo melhora. Uma taxa de aprendizado típica é 0,1 ou 0,01, em que 0,01 é um ajuste muito menor e pode fazer com que o treinamento leve muito tempo para convergir, enquanto 0,1 é muito maior e pode fazer com que o treinamento ultrapasse. É um dos principais hiperparâmetros que você pode ajustar para treinar seu modelo. Observe que, para modelos de texto, uma taxa de aprendizado muito menor (5e-5 para BERT) pode resultar em um modelo mais preciso.
-
Tamanho do lote — O número de registros do conjunto de dados que devem ser selecionados para cada intervalo a serem enviados ao GPUs para treinamento.
Em um exemplo de imagem, você pode enviar 32 imagens por GPU, então 32 seria o tamanho do seu lote. Se você escolher um tipo de instância com mais de uma GPU, o lote será dividido pelo número de GPUs. O tamanho do lote sugerido varia de acordo com os dados e o modelo que você está usando. Por exemplo, a forma como você otimiza os dados de imagem difere da forma como você lida com os dados de idioma.
No gráfico do tipo de instância na seção de configuração de implantação, você pode ver o número de GPUs por tipo de instância. Comece com um tamanho de lote padrão recomendado (por exemplo, 32 para um modelo de visão). Em seguida, multiplique isso pelo número de GPUs no tipo de instância que você selecionou. Por exemplo, se você estiver usando um
p3.8xlarge, isso seria 32 (tamanho do lote) multiplicado por 4 (GPUs), totalizando 128, conforme o tamanho do lote se ajusta ao número de. GPUs Para um modelo de texto como o BERT, tente começar com um tamanho de lote de 64 e depois reduzir conforme necessário.
Resultado de treinamento
Quando o processo de ajuste fino é concluído, JumpStart fornece informações sobre o modelo: modelo principal, nome do trabalho de treinamento, ARN do trabalho de treinamento, tempo de treinamento e caminho de saída. O caminho de saída é onde você pode encontrar o novo modelo em um bucket do Amazon S3. A estrutura de pastas usa o nome do modelo que você forneceu e o arquivo do modelo está em uma subpasta /output e é sempre nomeado model.tar.gz.
Example: s3://bucket/model-name/output/model.tar.gz
Configurar valores padrão para treinamento de modelos
Você pode configurar valores padrão para parâmetros como funções do IAM e chaves KMS a serem pré-preenchidos para implantação e treinamento JumpStart do modelo. VPCs Para obter mais informações, consulte, Configurar valores padrão para JumpStart modelos.
