As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Endpoints multimodelo
Os endpoints multimodelo fornecem uma solução escalável e econômica para a implantação de um grande número de modelos. Eles melhoram a utilização do endpoint compartilhando a mesma frota de recursos e contêiner de serviço para hospedar todos os seus modelos. Isso reduz os custos de hospedagem, melhorando a utilização do endpoint em comparação com o uso de endpoints de modelo único. Também reduz a sobrecarga de implantação porque a Amazon SageMaker AI gerencia o carregamento de modelos na memória e a escalabilidade deles com base nos padrões de tráfego para seu endpoint.
O diagrama a seguir mostra como os endpoints multimodelo funcionam em comparação com os endpoints de modelo único.
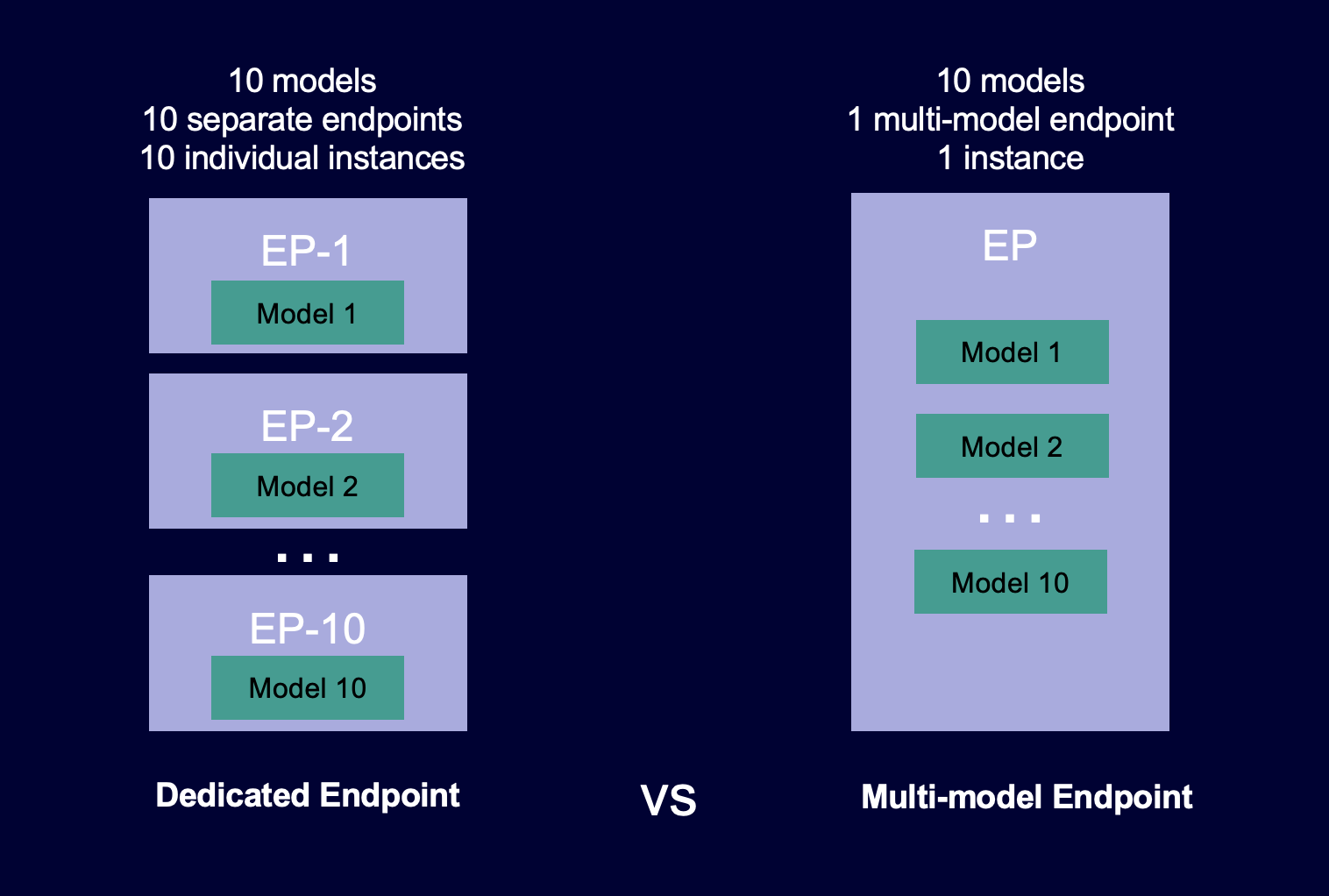
Os endpoints multimodelo são ideais para hospedar um grande número de modelos que usam a mesma framework de ML em um contêiner de serviço compartilhado. Se você tem uma combinação de modelos acessados com frequência e modelos acessados com pouca frequência, um endpoint multimodelo pode servir eficientemente esse tráfego com menos recursos e maior economia de custos. Sua aplicação deve ser tolerante a penalidades de latência ocasionais relacionadas à inicialização a frio que ocorrem ao chamar modelos de uso pouco frequente.
Os endpoints multimodelo oferecem apoio à hospedagem de modelos baseados em CPU e GPU. Ao utilizar modelos com compatibilidade com GPU, você pode reduzir os custos de implantação do modelo por meio do aumento do uso do endpoint e de suas instâncias de computação aceleradas subjacentes.
Os endpoints multimodelo permitem compartilhar o tempo de recursos de memória entre seus modelos. Isso funciona melhor quando os modelos são muito semelhantes em tamanho e latência de invocação. Quando for o caso, os endpoints multimodelo podem efetivamente usar instâncias em todos os modelos. Se você tiver modelos com transações por segundo (TPS) ou requisitos de latência significativamente maiores, recomendamos hospedá-los em endpoints dedicados.
Você pode usar endpoints multimodelo com os seguintes atributos:
-
AWS PrivateLinke VPCs
-
Pipelines de inferência de série (mas apenas um contêiner habilitado para vários modelos pode ser incluído em um pipeline de inferência)
-
Testes A/B
Você pode usar o console AWS SDK for Python (Boto) ou o SageMaker AI para criar um endpoint multimodelo. Para endpoints multimodelo com compatibilidade com CPU, você pode criar seu endpoint com contêineres personalizados integrando a biblioteca Multi Model Server
Tópicos
Algoritmos, frameworks e instâncias compatíveis para endpoints multimodelo
Recomendações de instâncias para implantações de endpoint multimodelo
Crie seu próprio contêiner para endpoints multimodelo de SageMaker IA
CloudWatch Métricas para implantações de endpoints de vários modelos
Defina o SageMaker comportamento de cache do modelo de endpoint multimodelo de IA
Defina políticas de ajuste de escala automático para implantações de endpoints multimodelo
Como funcionam os endpoints multimodelo
SageMaker A IA gerencia o ciclo de vida dos modelos hospedados em endpoints de vários modelos na memória do contêiner. Em vez de baixar todos os modelos de um bucket do Amazon S3 para o contêiner ao criar o endpoint, a SageMaker IA os carrega dinamicamente e os armazena em cache quando você os invoca. Quando a SageMaker IA recebe uma solicitação de invocação para um modelo específico, ela faz o seguinte:
-
Roteia a solicitação para uma instância por trás do endpoint.
-
Faz download do modelo do bucket do S3 para o volume de armazenamento dessa instância.
-
Carrega o modelo na memória do contêiner (CPU ou GPU, dependendo se você tem instâncias compatíveis com CPU ou GPU) naquela instância de computação acelerada. Se o modelo já estiver carregado na memória do contêiner, a invocação é mais rápida porque a SageMaker IA não precisa baixá-lo e carregá-lo.
SageMaker A IA continua roteando as solicitações de um modelo para a instância em que o modelo já está carregado. No entanto, se o modelo receber muitas solicitações de invocação e houver instâncias adicionais para o endpoint multimodelo, a SageMaker IA encaminha algumas solicitações para outra instância para acomodar o tráfego. Se o modelo ainda não estiver carregado na segunda instância, o modelo será obtido por download no volume de armazenamento dessa instância e carregado na memória do contêiner.
Quando a utilização da memória de uma instância é alta e a SageMaker IA precisa carregar outro modelo na memória, ela descarrega modelos não utilizados do contêiner dessa instância para garantir que haja memória suficiente para carregar o modelo. Os modelos que são descarregados permanecem no volume de armazenamento da instância e podem ser carregados na memória do contêiner mais tarde sem serem obtidos por download novamente do bucket do S3. Se o volume de armazenamento da instância atingir sua capacidade, a SageMaker IA excluirá todos os modelos não utilizados do volume de armazenamento.
Para excluir um modelo, pare de enviar solicitações e exclua-o do bucket do S3. SageMaker A IA fornece capacidade de endpoint multimodelo em um contêiner de serviço. Adicionar modelos e excluí-los de um endpoint multimodelo não requer a atualização do endpoint propriamente dito. Para adicionar um modelo, faça upload dele para o bucket do S3 e comece a invocá-lo. Você não precisa de alterações de código para usá-lo.
nota
Quando você atualiza um endpoint multi-modelo, as solicitações de invocação inicial no endpoint podem apresentar latências mais altas, à medida que o Smart Routing em endpoints multimodelo se adapta ao padrão de tráfego. No entanto, depois que aprende seu padrão de tráfego, você pode experimentar baixas latências nos modelos usados com mais frequência. Modelos usados com menos frequência podem incorrer em algumas latências de inicialização a frio, pois os modelos são carregados dinamicamente em uma instância.
Cadernos de exemplos para endpoints multimodelo
Para aprender mais sobre como usar endpoints multi-modelo, você pode experimentar os seguintes cadernos de exemplo:
-
Exemplos de endpoints multimodelo usando instâncias com compatibilidade com CPU:
-
Notebook de XGBoost amostra de endpoint multimodelo
— Este notebook mostra como implantar vários XGBoost modelos em um endpoint. -
Exemplo de caderno BYOC de endpoints multimodelo
— Este notebook mostra como configurar e implantar um contêiner de cliente que ofereça suporte a endpoints multimodelo em IA. SageMaker
-
-
Exemplos de endpoints multimodelo usando instâncias com compatibilidade com GPU:
-
Execute vários modelos de aprendizado profundo GPUs com os endpoints multimodelo (MME) de SageMaker IA da Amazon
— este notebook mostra como usar um contêiner NVIDIA Triton Inference para implantar ResNet -50 modelos em um endpoint multimodelo.
-
Para obter instruções sobre como criar e acessar instâncias do notebook Jupyter que você pode usar para executar os exemplos anteriores em SageMaker IA, consulte. Instâncias de SageMaker notebook da Amazon Depois de criar uma instância do notebook e abri-la, escolha a guia Exemplos de SageMaker IA para ver uma lista de todas as amostras de SageMaker IA. O caderno de endpoint multimodelo está localizado na seção FUNCIONALIDADE AVANÇADA. Para abrir um caderno, escolha a guia Uso e depois escolha Criar cópia.
Para obter mais informações sobre casos de uso para endpoints multimodelo, consulte os seguintes blogs e recursos:
