As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Como funciona o algoritmo Object2Vec
Ao usar o algoritmo Amazon SageMaker AI Object2Vec, você segue o fluxo de trabalho padrão: processa os dados, treina o modelo e produz inferências.
Etapa 1: Processar dados
Durante o pré-processamento, converta os dados no formato de arquivo de texto JSON Linesnp.random.shuffle. Para Unix, use shuf.
Etapa 2: Treinar um modelo
O algoritmo SageMaker AI Object2Vec tem os seguintes componentes principais:
-
Dois canais de entrada: Os canais de entrada usam um par de objetos do mesmo tipo ou de tipos diferentes como entradas e os transferem para codificadores independentes e personalizáveis.
-
Dois codificadores: Os dois codificadores enc0 e enc1 convertem cada objeto em um vetor de incorporação de tamanho fixo. As incorporações codificadas dos objetos no par, que são então transmitidas para um comparador.
-
Um comparador: O comparador compara as incorporações de diferentes maneiras e gera pontuações que indicam a força do relacionamento entre os objetos emparelhados. Na pontuação de saída para um par de frases. Por exemplo, 1 indica uma forte relação entre um par de frase e 0 representa um relacionamento fraco.
Durante o treinamento, o algoritmo aceita pares de objetos e seus rótulos de relacionamento ou pontuações como entradas. Os objetos em cada par pode ser de tipos diferentes, como descrito anteriormente. Se as entradas para os dois codificadores forem compostas pelas mesmas unidades de nível de token, você poderá usar uma camada de incorporação de token compartilhada definindo o hiperparâmetro tied_token_embedding_weight para quando True criar a tarefa de treinamento. Isso é possível, por exemplo, ao comparar sentenças que possuem unidades de nível de token de palavra. Para gerar amostras negativas em uma taxa especificada, defina o hiperparâmetro negative_sampling_rate para a proporção desejada de amostras negativas para positivas. Esse hiperparâmetro agiliza o aprendizado de como diferenciar as amostras positivas observadas nos dados de treinamento e as amostras negativas que provavelmente não serão observadas.
Os pares de objetos são transmitidos por meio de codificadores personalizáveis e independentes que são compatíveis com os tipos de entrada dos objetos correspondentes. Os codificadores convertem cada objeto em um par em um vetor de incorporação de tamanho fixo e comprimento igual. O par de vetores é passado para um operador comparador, que monta os vetores em um único vetor usando o valor especificado no hiperparâmetro comparator_list. O vetor montado, em seguida, passa por uma camada multilayer perceptron (MLP), que produz uma saída que compara a função de perda com os rótulos que você forneceu. Essa comparação avalia a intensidade do relacionamento entre os objetos no par conforme previsto pelo modelo. A figura a seguir mostra esse fluxo de trabalho.
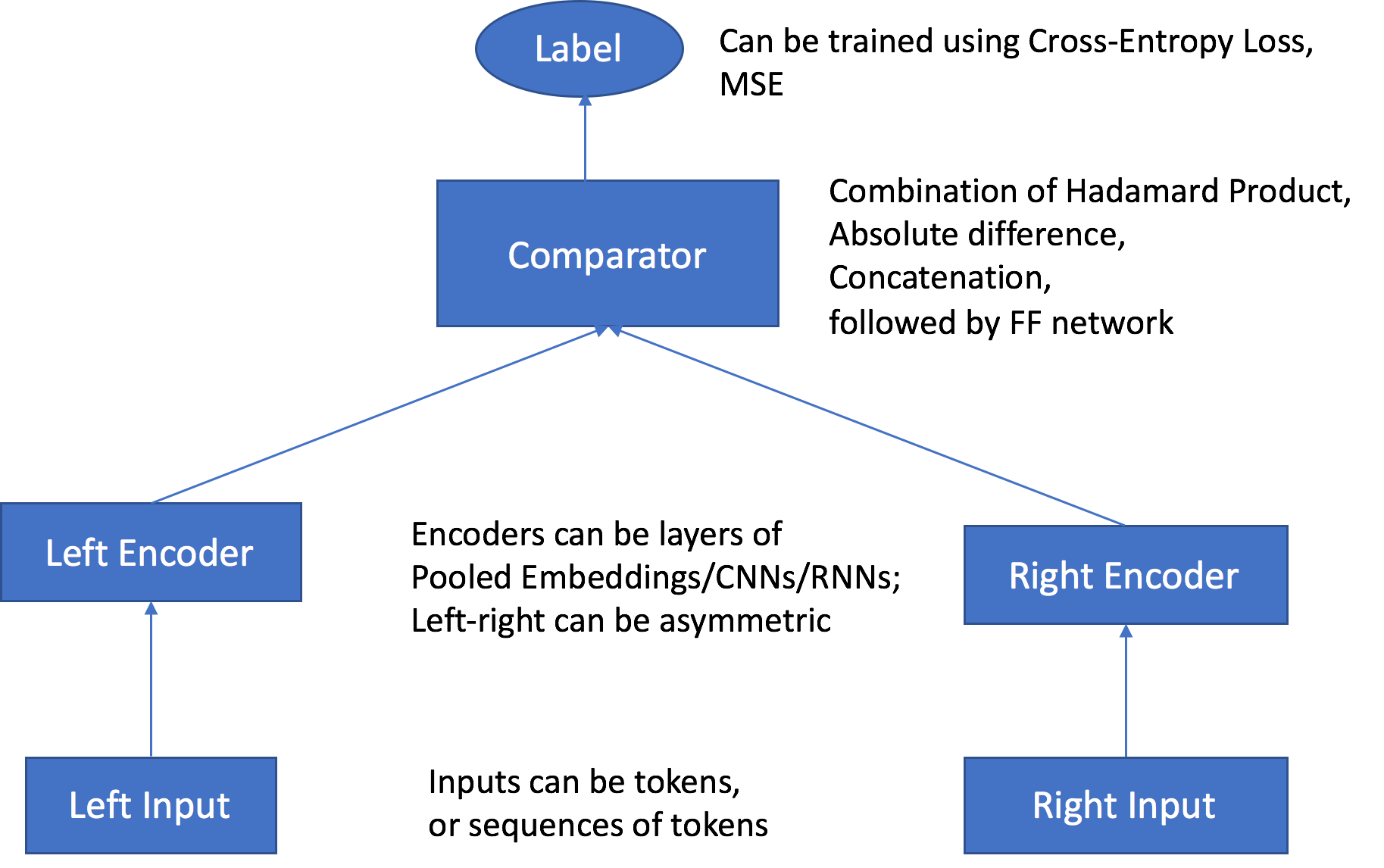
Arquitetura do algoritmo Object2Vec de entradas de dados a pontuações
Etapa 3: produzir inferências
Depois que o modelo for treinado, você poderá usar o codificador treinado para pré-processar objetos de entrada ou para executar dois tipos de inferência:
-
Para converter objetos de entrada singulares em incorporações de tamanho fixo usando o codificador correspondente
-
Para prever o rótulo de relacionamento ou a pontuação entre um par de objetos de entrada
O servidor de inferência calcula automaticamente qual dos tipos é solicitado com base nos dados de entrada. Para ter as incorporações como saída, forneça apenas uma entrada. Para prever o rótulo ou a pontuação do relacionamento, forneça as duas entradas no par.
