As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
SageMaker Solução de problemas do compilador de treinamento
Importante
A Amazon Web Services (AWS) anuncia que não haverá novos lançamentos ou versões do SageMaker Training Compiler. Você pode continuar a utilizar o SageMaker Training Compiler por meio dos AWS Deep Learning Containers (DLCs) existentes para SageMaker treinamento. É importante observar que, embora os existentes DLCs permaneçam acessíveis, eles não receberão mais patches ou atualizações de AWS, de acordo com a Política de Suporte do AWS Deep Learning Containers Framework.
Se você encontrar um erro, você pode usar a seguinte lista para tentar solucionar problemas no seu tarefa de treinamento: Se precisar de mais suporte, entre em contato com a equipe de SageMaker IA por meio de AWS Support
A tarefa de treinamento não está convergindo conforme o esperado quando comparado à tarefa de treinamento do framework nativo
Os problemas de convergência variam de “o modelo não está aprendendo quando o SageMaker Training Compiler está ativado” a “o modelo está aprendendo, mas é mais lento que a estrutura nativa”. Neste guia de solução de problemas, presumimos que sua convergência está boa sem o SageMaker Training Compiler (na estrutura nativa) e consideramos isso a linha de base.
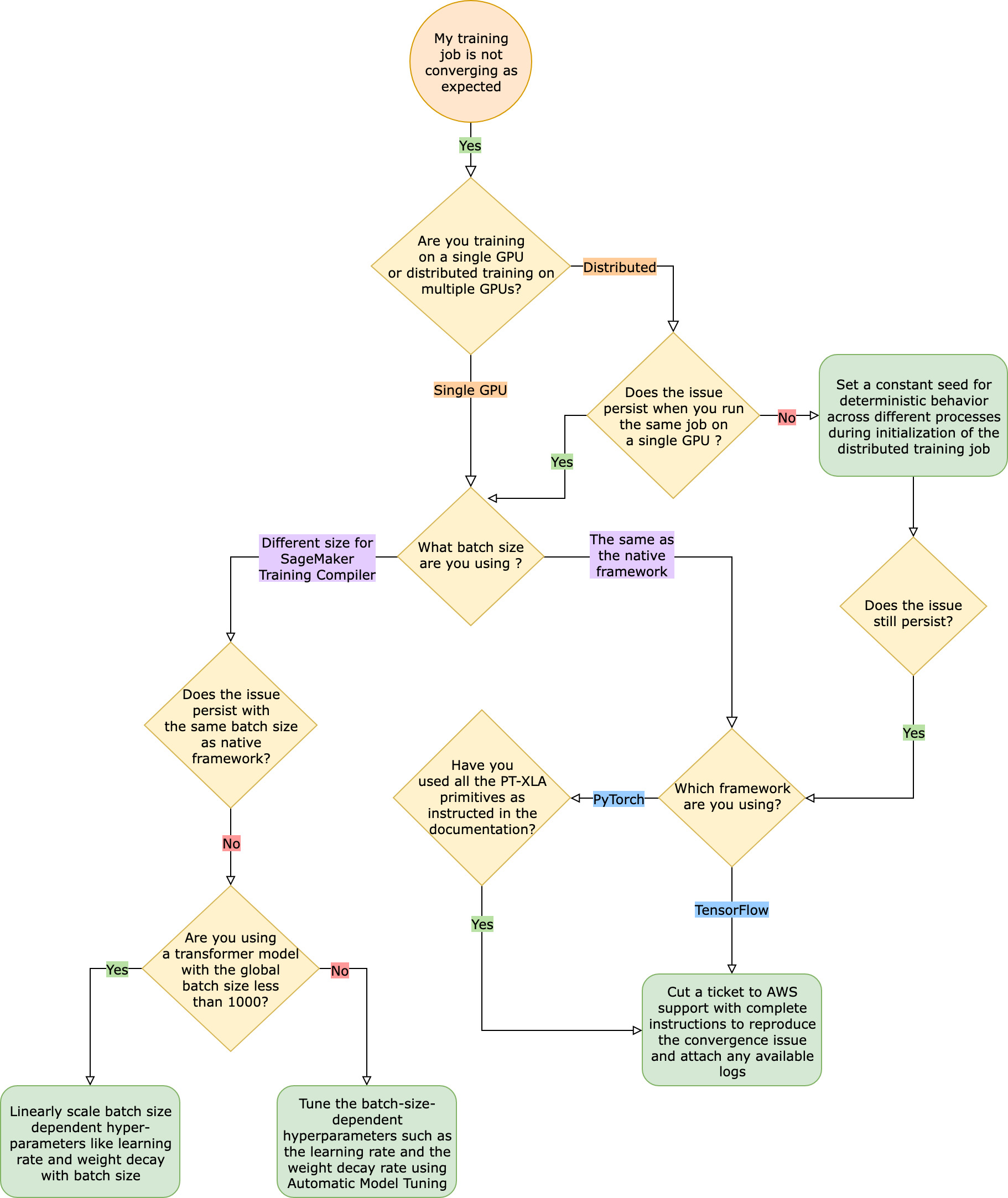
Ao enfrentar esses problemas de convergência, a primeira etapa é identificar se o problema se limita ao treinamento distribuído ou se deriva do treinamento com uma única GPU. O treinamento distribuído com o SageMaker Training Compiler é uma extensão do treinamento com uma única GPU com etapas adicionais.
-
Configure um cluster com várias instâncias ou GPUs.
-
Distribua os dados de entrada para todos os operadores.
-
Sincronize as atualizações do modelo de todos os operadores.
Portanto, qualquer problema de convergência no treinamento com uma única GPU se propaga para o treinamento distribuído com vários operadores.
Problemas de convergência que ocorrem no treinamento com uma única GPU
Se o seu problema de convergência decorre do treinamento com uma única GPU, isso provavelmente se deve a configurações inadequadas de hiperparâmetros ou o. torch_xla APIs
Verificar os hiperparâmetros
O treinamento com o SageMaker Training Compiler leva a uma mudança na pegada de memória de um modelo. O compilador arbitra de forma inteligente entre reutilização e recomputação, levando a um aumento ou diminuição correspondente no consumo de memória. Para aproveitar isso, é essencial reajustar o tamanho do lote e os hiperparâmetros associados ao migrar um trabalho de treinamento para SageMaker o Training Compiler. No entanto, configurações incorretas de hiperparâmetros frequentemente causam oscilação na perda de treinamento e possivelmente uma convergência mais lenta como resultado. Em casos raros, hiperparâmetros agressivos podem fazer com que o modelo não aprenda (a métrica de perda de treinamento não diminui nem retorna NaN). Para identificar se o problema de convergência se deve aos hiperparâmetros, faça um side-by-side teste de dois trabalhos de treinamento com e sem o SageMaker Training Compiler, mantendo todos os hiperparâmetros iguais.
Verifique se torch_xla APIs eles estão configurados corretamente para treinamento com uma única GPU
Se o problema de convergência persistir com os hiperparâmetros da linha de base, você precisará verificar se há algum uso impróprio dos torch_xla APIs, especificamente aqueles para atualizar o modelo. Fundamentalmente, torch_xla continua acumulando instruções (adiando a execução) na forma de gráfico até que seja explicitamente instruído a executar o gráfico acumulado. A função torch_xla.core.xla_model.mark_step() facilita a execução do gráfico acumulado. A execução do gráfico deve ser sincronizada usando essa função após cada atualização do modelo e antes de imprimir e registrar quaisquer variáveis. Se faltar a etapa de sincronização, o modelo pode utilizar valores obsoletos da memória durante impressões, logs e as passagens subsequentes para a frente, em vez de usar os valores mais recentes que precisam ser sincronizados após cada iteração e atualização do modelo.
Pode ser mais complicado usar o SageMaker Training Compiler com escalonamento de gradiente (possivelmente com o uso de AMP) ou técnicas de recorte de gradiente. A ordem apropriada do cálculo do gradiente com AMP é a seguinte:
-
Computação de gradiente com escalabilidade
-
Gradiente sem escala, recorte de gradiente e, em seguida, em escala
-
Atualização do modelo
-
Sincronizando a execução do gráfico com
mark_step()
Para encontrar a opção certa APIs para as operações mencionadas na lista, consulte o guia para migrar seu script de treinamento para o Training SageMaker Compiler.
Considere usar o ajuste automático de modelos
Se o problema de convergência surgir ao reajustar o tamanho do lote e os hiperparâmetros associados, como a taxa de aprendizado, ao usar o SageMaker Training Compiler, considere usar o ajuste automático de modelos para ajustar seus hiperparâmetros. Você pode consultar o exemplo de caderno de anotações sobre o ajuste de hiperparâmetros com o SageMaker Training Compiler
Problemas de convergência que ocorrem no treinamento distribuído
Se o problema de convergência persistir no treinamento distribuído, isso provavelmente se deve a configurações inadequadas para inicialização do peso ou a. torch_xla APIs
Verifique a inicialização do peso entre os operadores
Se surgir um problema de convergência ao executar um trabalho de treinamento distribuído com vários operadores, certifique-se de que há um comportamento determinístico uniforme entre todos os operadores, definindo uma semente constante quando aplicável. Cuidado com técnicas como inicialização de peso, que envolve randomização. Cada operador pode acabar treinando um modelo diferente na ausência de uma semente constante.
Verifique se torch_xla APIs eles estão configurados corretamente para treinamento distribuído
Se o problema persistir, isso provavelmente se deve ao uso indevido do torch_xla APIs para treinamento distribuído. Certifique-se de adicionar o seguinte em seu estimador para configurar um cluster para treinamento distribuído com o Training Compiler SageMaker .
distribution={'torchxla': {'enabled': True}}
Isso deve ser acompanhado por uma função _mp_fn(index) em seu script de treinamento, que é invocada uma vez por operador. Sem a função mp_fn(index), você pode acabar permitindo que cada um dos operadores treine o modelo de forma independente, sem compartilhar as atualizações do modelo.
Em seguida, certifique-se de usar a torch_xla.distributed.parallel_loader.MpDeviceLoader API junto com o amostrador de dados distribuído, conforme orientado na documentação sobre a migração do seu script de treinamento para o SageMaker Training Compiler, como no exemplo a seguir.
torch.utils.data.distributed.DistributedSampler()
Isso garante que os dados de entrada sejam distribuídos adequadamente entre todos os operadores.
Por fim, para sincronizar as atualizações do modelo de todos os operadores, use torch_xla.core.xla_model._fetch_gradients para coletar gradientes de todos os operadores e torch_xla.core.xla_model.all_reduce combinar todos os gradientes coletados em uma única atualização.
Pode ser mais complicado usar o SageMaker Training Compiler com escalonamento de gradiente (possivelmente devido ao uso de AMP) ou técnicas de recorte de gradiente. A ordem apropriada do cálculo do gradiente com AMP é a seguinte:
-
Computação de gradiente com escalabilidade
-
Sincronização de gradientes em todos os operadores
-
Gradiente sem escala, recorte de gradiente e, em seguida, gradiente em escala
-
Atualização do modelo
-
Sincronizando a execução do gráfico com
mark_step()
Observe que essa lista de verificação tem um item adicional para sincronizar todos os operadores, em comparação com a lista de verificação para treinamento com uma única GPU.
O trabalho de treinamento falha devido à falta de configuração PyTorch /XLA
Se um trabalho de treinamento falhar com a mensagem de Missing XLA configuration erro, pode ser devido a uma configuração incorreta no número de GPUs por instância que você usa.
O XLA requer variáveis de ambiente adicionais para compilar o trabalho de treinamento. A variável de ambiente ausente mais comum é GPU_NUM_DEVICES. Para que o compilador funcione corretamente, você deve definir essa variável de ambiente igual ao número de GPUs por instância.
Há três abordagens para definir a variável de ambiente GPU_NUM_DEVICES.
-
Abordagem 1 — Use o
environmentargumento da classe de estimadores de SageMaker IA. Por exemplo, se você usar umaml.p3.8xlargeinstância que tenha quatro GPUs, faça o seguinte:# Using the SageMaker Python SDK's HuggingFace estimator hf_estimator=HuggingFace( ... instance_type="ml.p3.8xlarge", hyperparameters={...}, environment={ ... "GPU_NUM_DEVICES": "4" # corresponds to number of GPUs on the specified instance }, ) -
Abordagem 2 — Use o
hyperparametersargumento da classe de estimador de SageMaker IA e analise-o em seu script de treinamento.-
Para especificar o número de GPUs, adicione um par de valores-chave ao
hyperparametersargumento.Por exemplo, se você usar uma
ml.p3.8xlargeinstância que tenha quatro GPUs, faça o seguinte:# Using the SageMaker Python SDK's HuggingFace estimator hf_estimator=HuggingFace( ... entry_point = "train.py" instance_type= "ml.p3.8xlarge", hyperparameters = { ... "n_gpus":4# corresponds to number of GPUs on specified instance } ) hf_estimator.fit() -
Em seu script de treinamento, analise o
n_gpushiperparâmetro e especifique-o como uma entrada para a variável de ambienteGPU_NUM_DEVICES.# train.py import os, argparse if __name__ == "__main__": parser = argparse.ArgumentParser() ... # Data, model, and output directories parser.add_argument("--output_data_dir", type=str, default=os.environ["SM_OUTPUT_DATA_DIR"]) parser.add_argument("--model_dir", type=str, default=os.environ["SM_MODEL_DIR"]) parser.add_argument("--training_dir", type=str, default=os.environ["SM_CHANNEL_TRAIN"]) parser.add_argument("--test_dir", type=str, default=os.environ["SM_CHANNEL_TEST"]) parser.add_argument("--n_gpus", type=str, default=os.environ["SM_NUM_GPUS"]) args, _ = parser.parse_known_args() os.environ["GPU_NUM_DEVICES"] = args.n_gpus
-
-
Abordagem 3: Codifique a variável de ambiente
GPU_NUM_DEVICESem seu script de treinamento. Por exemplo, adicione o seguinte ao seu script se você usar uma instância que tenha quatro GPUs.# train.py import os os.environ["GPU_NUM_DEVICES"] =4
dica
Para encontrar o número de dispositivos de GPU em instâncias de aprendizado de máquina que você deseja usar, consulte Computação acelerada na página
SageMaker O Training Compiler não reduz o tempo total de treinamento
Se o tempo total de treinamento não diminuir com o SageMaker Training Compiler, é altamente recomendável que você consulte a SageMaker Práticas recomendadas e considerações sobre o Training Compiler página para verificar a configuração do treinamento, a estratégia de preenchimento da forma do tensor de entrada e os hiperparâmetros.
