As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Visão geral da arquitetura
Esta seção fornece um diagrama de arquitetura de implementação de referência para os componentes implantados com essa solução.
Diagrama de arquitetura
A implantação dessa solução com os parâmetros padrão cria o seguinte ambiente na nuvem da AWS.
Descoberta da carga de trabalho na arquitetura da AWS
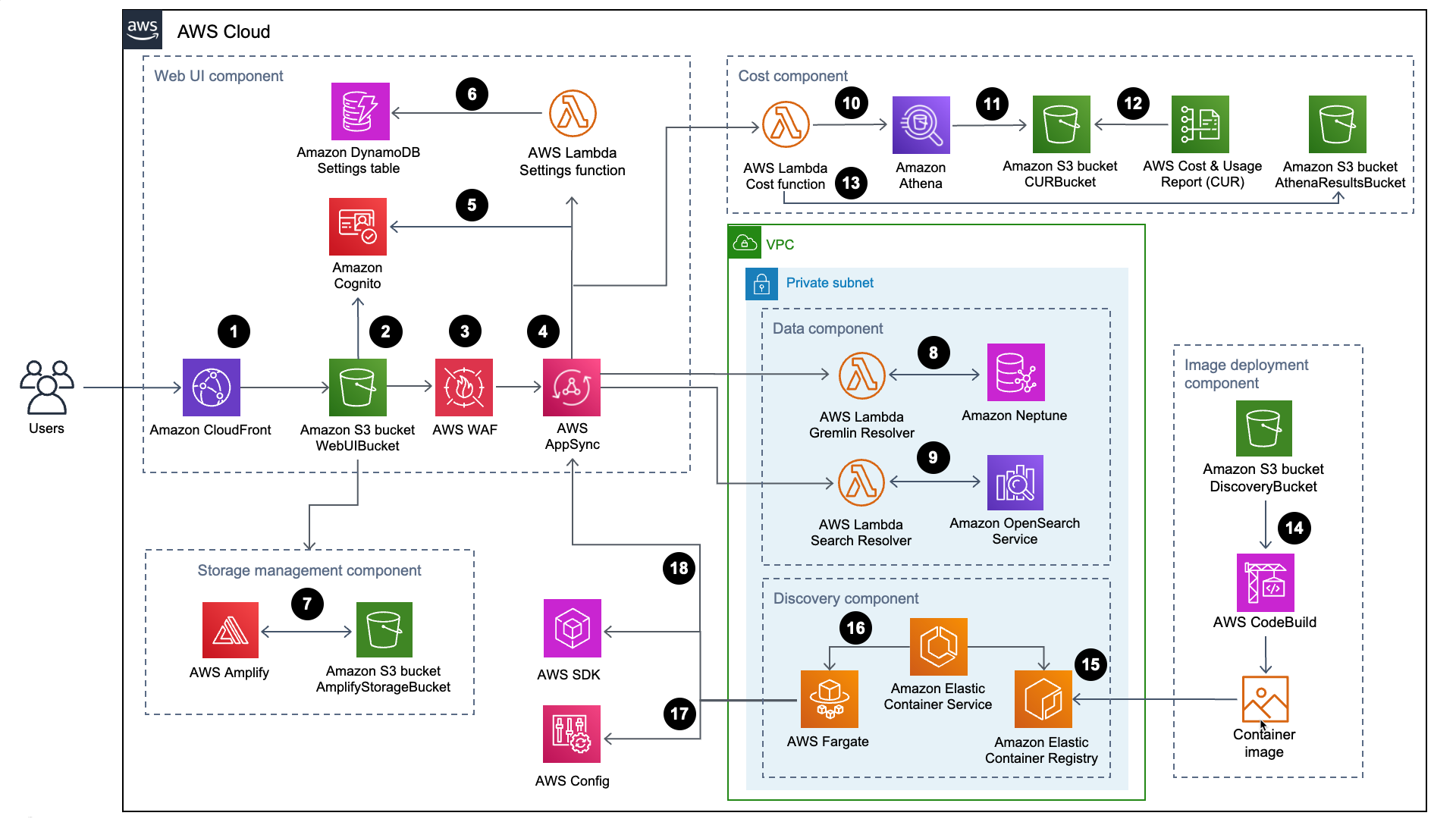
O fluxo de processo de alto nível para os componentes da solução implantados com o CloudFormation modelo da AWS é o seguinte:
-
O HTTP Strict-Transport-Security (HSTS)
adiciona cabeçalhos de segurança a cada resposta da distribuição da Amazon CloudFront . -
Um bucket do Amazon Simple Storage Service
(Amazon S3) hospeda a interface do usuário da web, que é distribuída com a Amazon. CloudFront O Amazon Cognito autentica o acesso do usuário à interface do usuário da web. -
O AWS WAF
protege a AppSync API contra explorações e bots comuns que podem afetar a disponibilidade, comprometer a segurança ou consumir recursos excessivos. -
AppSyncOs endpoints da AWS
permitem que o componente de interface de usuário da web solicite dados de relacionamento de recursos, consulte custos, importe novas regiões da AWS e atualize preferências. A AWS AppSync também permite que o componente de descoberta armazene dados persistentes nos bancos de dados da solução. -
AppSync A AWS usa JSON Web Tokens
(JWTs) provisionados pelo Amazon Cognito para autenticar cada solicitação. -
A função
SettingsAWS Lambdapersiste regiões importadas e outras configurações para o Amazon DynamoDB. -
A solução implanta o AWS
Amplify e um bucket Amazon S3 como componente de gerenciamento de armazenamento para armazenar as preferências do usuário e os diagramas de arquitetura salvos. -
O componente de dados usa a função
Gremlin ResolverAWS Lambda para consultar e retornar dados de um banco de dados Amazon Neptune. -
O componente de dados usa a função
Search ResolverLambda para consultar e persistir dados de recursos em um domínio do Amazon OpenSearchService. -
A função
CostLambda usa o Amazon Athenapara consultar os relatórios de custo e uso da AWS (AWS CUR) para fornecer dados de custo estimado para a interface do usuário da web. -
O Amazon Athena executa consultas no AWS CUR.
-
O AWS CUR entrega os relatórios para o bucket do
CostAndUsageReportBucketAmazon S3. -
A função
CostLambda armazena os resultados do Amazon Athena no bucket do AmazonAthenaResultsBucketS3. -
A AWS CodeBuild
cria a imagem do contêiner do componente de descoberta no componente de implantação da imagem. -
O Amazon Elastic Container Registry
(Amazon ECR) contém uma imagem do Docker fornecida pelo componente de implantação da imagem. -
O Amazon Elastic Container Service
(Amazon ECS) gerencia a tarefa do AWS Fargate e fornece a configuração necessária para executar a tarefa. O AWS Fargate executa uma tarefa de contêiner a cada 15 minutos para atualizar dados de inventário e recursos. -
As chamadas do AWS Config
e do AWS SDK ajudam o componente de descoberta a manter um inventário de dados de recursos das regiões importadas e, em seguida, armazenar seus resultados no componente de dados. -
A tarefa do AWS Fargate persiste os resultados das chamadas do AWS Config e do AWS SDK em um banco de dados Amazon Neptune e em um domínio do Amazon Service com chamadas de API para a API. OpenSearch AppSync
