REL10-BP04 Usar arquiteturas de anteparo para limitar o escopo de impacto
Implemente arquiteturas de anteparo (também chamadas de arquiteturas baseadas em células) para restringir o efeito ou a falha em uma workload a um número limitado de componentes.
Resultado desejado: uma arquitetura baseada em células usa várias instâncias isoladas de uma workload, em que cada instância é considerada uma célula. Cada célula é independente, não compartilha o estado com outras células e processa um subconjunto das solicitações gerais da workload. Isso reduz o possível impacto de uma falha, como uma atualização de software incorreta, a uma célula individual e às solicitações que ela está processando. Se uma workload usa 10 células para atender a 100 solicitações, quando ocorre uma falha, 90% das solicitações gerais não seriam afetadas pela falha.
Antipadrões comuns:
-
Permitir que as células cresçam sem limites.
-
Aplicar implantações ou atualizações de código a todas as células ao mesmo tempo.
-
Compartilhar o estado ou os componentes entre as células (com a exceção da camada do roteador).
-
Adicionar negócios complexos ou rotear lógica para a camada do roteador.
-
Não minimizar as interações entre as células.
Benefícios do estabelecimento dessa prática recomendada: com arquiteturas baseadas em células, muitos tipos comuns de falhas são contidas na própria célula, fornecendo isolamento de falhas adicional. Esses limites de falhas podem fornecer resiliência com relação a tipos de falha que, de outra maneira, seriam difíceis de conter, como implantações de código sem êxito ou solicitações corrompidas ou que acionam um modo de falha específico (também conhecidas como solicitações com conteúdo malicioso).
Orientação de implementação
Em um navio, as anteparas garantem que uma ruptura no casco seja contida em uma seção do casco. Em sistemas complexos, esse padrão costuma ser replicado para permitir o isolamento de falhas. Os limites isolados de falhas restringem o efeito de uma falha em uma workload a um número controlado de componentes. A falha não afeta os componentes fora do limite. Ao usar vários limites isolados de falhas, você pode restringir o impacto sobre sua carga de trabalho. Na AWS, os clientes podem usar várias zonas de disponibilidade e regiões para fornecer o isolamento de falhas, mas o conceito do isolamento de falhas também pode ser estendido à arquitetura da workload.
A workload geral é composta por células particionadas por uma chave de partição. Essa chave precisa se alinhar à granularidade do serviço, ou da maneira natural que a workload de um serviço pode ser subdividida em interações mínimas entre células. Exemplos de chaves de partição são ID de cliente, ID de recurso ou qualquer outro parâmetro facilmente acessível na maioria das chamadas de API. Uma camada de roteamento de célula distribui solicitações a células individuais com base na chave de partição e apresenta um único endpoint aos clientes.
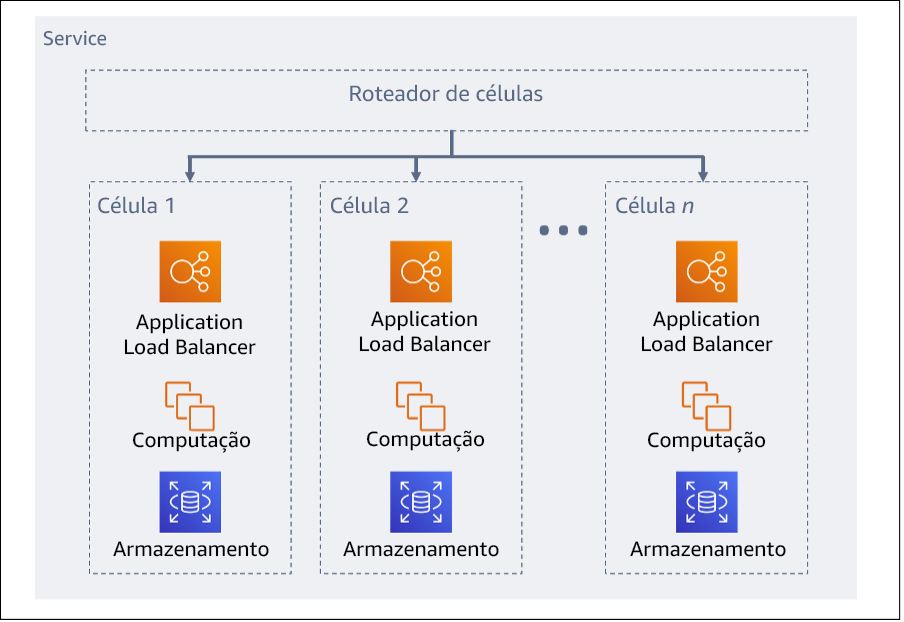
Figura 11: arquitetura baseada em células
Etapas da implementação
Ao projetar uma arquitetura baseada em células, há várias considerações de design a levar em conta:
-
Chave de partição: deve-se dedicar uma consideração especial ao escolher a chave de partição.
-
Ela precisa se alinhar à granularidade do serviço, ou da maneira natural que a workload de um serviço pode ser subdividida em interações mínimas entre células. Dentre os exemplos estão o
ID de clienteouID de recurso. -
A chave de partição deve estar disponível em todas as solicitações, seja diretamente ou de uma maneira que possa ser facilmente inferida de forma determinística por outros parâmetros.
-
-
Mapeamento de células persistentes: os serviços de upstream só devem interagir com uma única célula pelo ciclo de vida dos recursos.
-
Dependendo da workload, uma estratégia de migração de células pode ser necessária para migrar os dados de uma célula para outra. Um possível cenário de quando é necessário fazer uma migração de célula seria quando um usuário ou recurso específico na workload fica grande demais e exige uma célula dedicada.
-
As células não devem compartilhar estado ou componentes entre si.
-
Consequentemente, as interações entre as células devem ser evitadas e mantidas no mínimo, já que elas podem criar dependências entre as células e, assim, reduzir as melhorias do isolamento de falhas.
-
-
Camada do roteador: a camada do roteador é um componente compartilhado entre células e, portanto, não pode seguir a mesma estratégia de compartimentalização das células.
-
É recomendável que a camada do roteador distribua as solicitações para células individuais usando um algoritmo de mapeamento de partição de maneira computacionalmente eficiente, como combinando funções de hash criptográficas e aritmética modular para mapear chaves de partição a células.
-
Para evitar impactos em várias células, a camada de roteamento deve permanecer o mais simples e horizontalmente escalável possível, o que exige evitar uma lógica empresarial complexa nessa camada. Isso tem o benefício adicional de facilitar a compreensão de seu comportamento esperado em todos os momentos, permitindo uma capacidade de testes completa. Conforme explicado por Colm MacCárthaigh em Reliability, constant work, and a good cup of coffee
(Confiabilidade, trabalho constante e uma boa xícara de café), designs simples e padrões de trabalho constantes produzem sistemas confiáveis e reduzem a antifragilidade.
-
-
Tamanho da célula: as células devem ter um tamanho máximo e não devem ter permissão para crescer além disso.
-
O tamanho máximo deve ser identificado com a realização de testes completos, até que os pontos de ruptura sejam atingidos e as margens operacionais seguras sejam estabelecidas. Para obter mais detalhes sobre como implementar práticas de testes, consulte REL07-BP04 Fazer o teste de carga da sua workload
-
A workload geral deve crescer com a adição de mais células, permitindo que a workload seja escalada com aumentos na demanda.
-
-
Estratégias de várias zonas de disponibilidade ou várias regiões: várias camadas de resiliência devem ser utilizadas para a proteção contra diferentes domínios de falha.
-
Para resiliência, você deve usar uma abordagem que crie camadas de defesa. Uma camada protege contra interrupções menores e mais comuns criando uma arquitetura altamente disponível usando várias AZs. Outra camada de defesa destina-se a proteger contra eventos raros, como desastres naturais generalizados e interrupções em nível regional. Essa segunda camada envolve arquitetar a aplicação para abranger várias Regiões da AWS. A implementação de uma estratégia multirregional para a workload ajuda a protegê-la contra desastres naturais generalizados, que afetam uma grande área geográfica de um país, ou falhas técnicas de escopo regional. Esteja ciente de que a implementação de uma arquitetura multirregional pode ser complexa e, geralmente, não é necessária para a maioria das workloads. Para obter mais detalhes, consulte REL10-BP02 Escolher os locais apropriados para sua implantação de vários locais.
-
-
Implantação de código: uma estratégia de implantação de código escalonada deve ter preferência com relação à implantação de alterações de código em todas as células ao mesmo tempo.
-
Isso ajudará a reduzir a possibilidade de falhas em várias células devido a uma implantação incorreta ou a erro humano. Para obter mais detalhes, consulte Automating safe, hands-off deployment
(Automatizar uma implantação prática e segura).
-
Nível de exposição a riscos quando esta prática recomendada não é estabelecida: alto
Recursos
Práticas recomendadas relacionadas:
Documentos relacionados:
-
Reliability, constant work, and a good cup of coffee
(Confiabilidade, trabalho constante e uma boa xícara de café) -
AWS and Compartmentalization
(AWS e compartimentalização) -
isolamento de carga de trabalho usando fragmentos aleatórios
-
Automating safe, hands-off deployment
(Automatizar uma implantação prática e segura)
Vídeos relacionados:
-
AWS re:Invent 2018: Close Loops and Opening Minds: How to Take Control of Systems, Big and Small
(AWS re:Invent 2018: fechar ciclos e abrir mentes: como controlar sistemas, sejam grandes ou pequenos) -
AWS re:Invent 2018: como a AWS reduz o impacto das falhas (ARC338)
-
Fragmentação aleatória: AWS re:Invent 2019: apresentação da Amazon Builders’ Library (DOP328)
-
AWS Summit ANZ 2021: tudo falha o tempo todo: como criar o design visando a resiliência
Exemplos relacionados:
