REL12-BP04 Testar a resiliência com engenharia do caos
Execute experimentos de caos regularmente em ambientes que estão em produção ou muito próximos de entrar em produção para entender como seu sistema responde a condições adversas.
Resultado desejado:
A resiliência da workload é verificada regularmente por meio da aplicação de engenharia do caos na forma de experimentos de injeção de falha ou injeção de carga inesperada, além de testes de resiliência que validam o comportamento conhecido esperado da workload durante um evento. Combine engenharia do caos e testes de resiliência para ter confiança de que sua workload poderá sobreviver à falha de componentes e se recuperar de interferências inesperadas com pouco ou nenhum impacto.
Práticas comuns que devem ser evitadas:
-
Projetar para resiliência, mas não verificar como a workload funciona como um todo quando falhas ocorrem.
-
Nunca realizar experimentos sob condições reais e de carga esperada.
-
Não tratar seus experimentos como código nem mantê-los ao longo do ciclo de desenvolvimento.
-
Não realizar experimentos de caos tanto como parte do pipeline de CI/CD quanto fora das implantações.
-
Negar o uso de análises pós-incidentes passadas ao determinar quais falhas usar para realizar experimentos.
Benefícios de implementar esta prática recomendada: a injeção de falhas para verificar a resiliência de uma workload permite que você obtenha confiança de que os procedimentos de recuperação de seu design resiliente vão funcionar em caso de falha real.
Nível de risco exposto se esta prática recomendada não for estabelecida: Médio
Orientação para implementação
A engenharia do caos proporciona à sua equipe os recursos para injetar continuamente interferências (simulações) reais de maneira controlada no provedor de serviço, na infraestrutura, na workload e no componente, com pouco ou nenhum impacto para os clientes. Ela permite que as equipes aprendam com as falhas e observem, mensurem e aumentem a resiliência das workloads, além de validar o acionamento de alertas e a notificação das equipes em caso de evento.
Quando realizada continuamente, a engenharia do caos pode destacar deficiências nas workloads que, se não respondidas, podem afetar negativamente a disponibilidade e a operação.
nota
A engenharia do caos é a disciplina de experimentar um sistema distribuído para aumentar a confiança na capacidade do sistema de resistir a condições turbulentas na produção. Princípios da engenharia do caos
Se um sistema é capaz de suportar essas interferências, os experimentos de caos devem ser mantidos como testes de regressão automatizados. Dessa forma, os experimentos de caos devem ser realizados como parte do ciclo de vida de desenvolvimento dos sistemas (SDLC) e como parte do pipeline de CI/CD.
Para garantir que sua workload possa sobreviver à falha de componentes, injete eventos reais como parte dos experimentos. Por exemplo, realize experimentos com perda de instâncias do Amazon EC2 ou failover da instância de banco de dados primária do Amazon RDS e verifique se a workload não é afetada (ou apenas minimamente afetada). Use uma combinação de falhas de componentes para simular eventos que podem ser causados por uma interferência em uma zona de disponibilidade.
Para falhas no nível da aplicação (como travamentos), você pode começar com fatores de estresse, como exaustão de memória e CPU.
Para validar os mecanismos de fallback ou failover
Outros modos de degradação podem levar a uma redução nas funcionalidades e a respostas lentas, muitas vezes levando a uma interrupção dos serviços. Essa degradação costuma resultar de um aumento na latência de serviços críticos e comunicação de rede não confiável (pacotes abandonados). Experimentos com essas falhas, incluindo efeitos de rede como latência, mensagens perdidas e falhas de DNS, podem incluir a incapacidade de resolver um nome, alcançar o serviço de DNS ou estabelecer conexões com serviços dependentes.
Ferramentas de engenharia do caos:
O AWS Fault Injection Service (AWS FIS) é um serviço totalmente gerenciado para a execução de experimentos de injeção de falha que podem ser usados como parte do pipeline de CD, ou fora do pipeline. O AWS FIS é uma boa opção para ser usado durante game days de engenharia de caos. Ele oferece suporte à introdução simultânea de falhas em diferentes tipos de recursos, incluindo Amazon EC2, Amazon Elastic Container Service (Amazon ECS), Amazon Elastic Kubernetes Service (Amazon EKS) e Amazon RDS. Essas falhas incluem encerramento de recursos, failovers forçados, esgotamento de CPU ou memória, controle de utilização, latência e perda de pacotes. Por ser integrado a alarmes do Amazon CloudWatch, é possível definir condições de parada como barreiras de proteção para reverter um experimento se ele causar impacto inesperado.
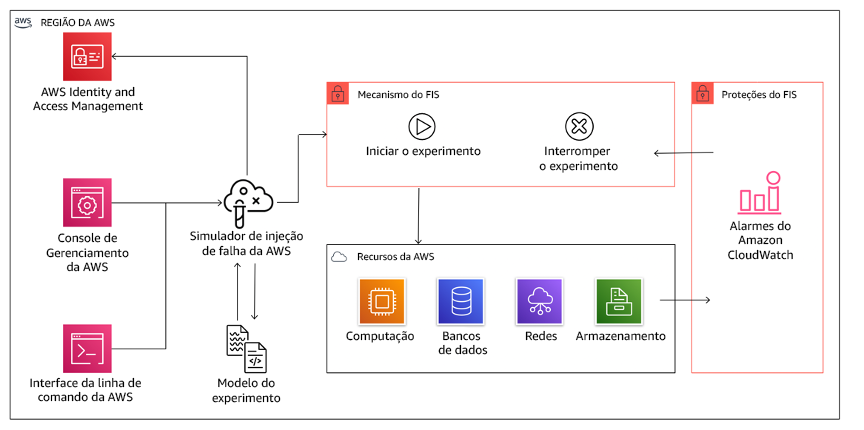
O AWS Fault Injection Service se integra a recursos da AWS para permitir a execução de experimentos de injeção de falha para as workloads.
Existem também várias opções de terceiros para experimentos de injeção de falhas. Isso inclui ferramentas de código aberto, como Chaos Toolkit
Etapas de implementação
-
Determine quais falhas usar em seus experimentos.
Avalie o design da workload quanto à resiliência. Esses designs (criados usando as práticas recomendadas do Well-Architected Framework) consideram os riscos com base em dependências críticas, eventos passados, problemas conhecidos e requisitos de conformidade. Liste cada elemento do design destinado a manter a resiliência e as falhas para o qual foi projetado para mitigar. Para obter mais informações sobre a criação dessas listas, consulte o whitepaper Revisões de prontidão operacional, o qual orienta você sobre como criar um processo para evitar a recorrência de incidentes anteriores. O processo de modos de falhas e análises de efeitos (FMEA) proporciona um framework para realização de análise de falhas em nível de componente e como elas afetam a workload. O FMEA é descrito com mais detalhes por Adrian Cockcroft em Modos de falha e resiliência contínua
. -
Atribua uma prioridade a cada falha.
Comece com uma categorização bruta, como alta, média e baixa. Para avaliar a prioridade, considere a frequência da falha e o impacto da falha na workload total.
Ao considerar a frequência de determinada falha, analise os dados passados para essa workload sempre que disponíveis. Caso contrário, use os dados de outras workloads executadas em ambientes semelhantes.
Ao considerar o impacto de determinada falha, em geral, quanto maior o escopo da falha, maior o impacto. Considere também o design e a finalidade da workload. Por exemplo, a capacidade de acessar os datastores de origem é essencial para uma workload que executa análise e transformação de dados. Nesse caso, priorize experimentos de falhas de acesso, além de acesso controlado e inserção de latência.
Análises pós-incidente são boas fontes de dados para entender a frequência e o impacto dos modos de falha.
Use a prioridade atribuída para determinar quais falhas escolher para experimentar primeiro e a sequência para desenvolver novos experimentos de injeção de falhas.
-
Para cada experimento realizado, siga o flywheel de engenharia do caos e resiliência contínua na figura a seguir.
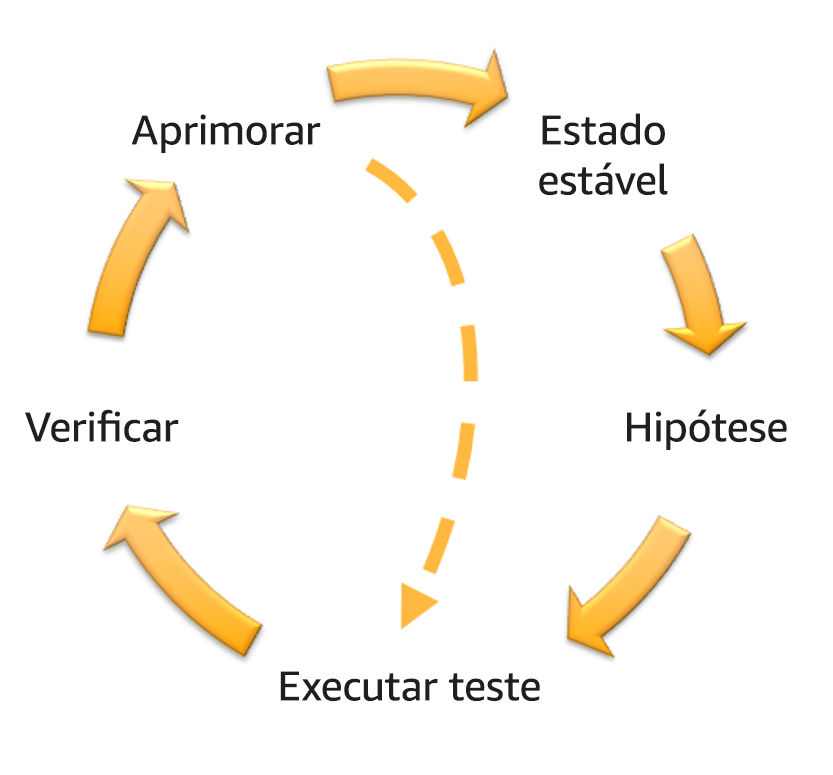
Flywheel de engenharia do caos e resiliência contínua usando o método científico, por Adrian Hornsby.
-
Defina o estado estável como uma saída mensurável de uma workload que indica comportamento normal.
Sua workload apresentará estado estável se estiver operando de maneira confiável e conforme o esperado. Portanto, valide a integridade da workload antes de definir o estado estável. O estado estável nem sempre significa que não há nenhum impacto à workload quando ocorre uma falha, já que determinada porcentagem de falhas pode estar dentro de limites aceitáveis. O estado estável é a linha de base que você poderá observar durante o experimento, o que irá destacar anomalias se a hipótese definida na próxima etapa não sair conforme o esperado.
Por exemplo, um estado estável de um sistema de pagamentos pode ser definido como o processamento de 300 TPS com taxa de sucesso de 99% e tempo de ida e volta de 500 ms.
-
Formule uma hipótese sobre como a workload irá reagir à falha.
Uma boa hipótese baseia-se em como se espera que a workload mitigue a falha para manter o estado estável. A hipótese afirma que para determinado tipo de falha, o sistema ou a workload permanecerá em estado estável, pois a workload foi projetada com mitigações específicas. O tipo específico de falhas e mitigações deve ser especificado na hipótese.
O modelo a seguir pode ser usado para a hipótese (mas uma redação diferente também é aceitável):
nota
Se uma
falha específicaocorrer, onome da workloaddescreverá os controles de mitigaçãopara manter oimpacto da métrica técnica ou comercial.Por exemplo:
-
Se 20% dos nós no grupo de nós do Amazon EKS forem desativados, a API Transaction Create continuará atendendo ao 99º percentil das solicitações em menos de 100 ms (estado estável). Os nós do Amazon EKS se recuperarão em cinco minutos e os pods serão agendados e processarão o tráfego oito minutos depois do início do experimento. Os alertas serão acionados em três minutos.
-
Se uma única falha de instância do Amazon EC2 ocorrer, a verificação de integridade do Elastic Load Balancing do sistema de ordem fará com que o Elastic Load Balancing envie solicitações apenas para as instâncias íntegras restantes, enquanto o Amazon EC2 Auto Scaling substitui a instância com falha, mantendo um aumento inferior a 0,01% na quantidade de erros no servidor (5xx) (estado estável).
-
Se a instância de banco de dados primária do Amazon RDS falhar, a workload de coleta de dados da cadeia de suprimentos vai entrar em failover e se conectará à instância de banco de dados de espera do Amazon RDS para manter menos de um minuto de erros de leitura ou gravação de banco de dados (estado estável).
-
-
Execute o experimento injetando a falha.
Um experimento deve, por padrão, ser seguro contra falhas e tolerado pela workload. Se você sabe que a workload irá falhar, não execute o experimento. A engenharia do caos deve ser usada para encontrar incertezas conhecidas ou desconhecidas. Incertezas conhecidas são coisas que você conhece, mas não entende completamente, enquanto incertezas desconhecidas são coisas das quais você não está ciente nem compreende totalmente. Realizar experimentos em uma workload que você sabe que não funciona não oferecerá novos insights. Seu experimento deve ser cuidadosamente planejado, ter um escopo claro do impacto e fornecer um mecanismo de reversão que possa ser aplicado em caso de turbulência inesperada. Se sua devida diligência mostrar que a workload sobreviverá ao experimento, prossiga com o teste. Há diversas opções para injetar as falhas. Para workloads na AWS, o AWS FIS fornece muitas simulações de falhas predefinidas chamadas ações. Você também pode definir ações personalizadas que são executadas no AWS FIS usando documentos do AWS Systems Manager.
Recomendamos não usar scripts personalizados para experimentos de caos, a menos que os scripts tenham a capacidade de entender o estado atual da workload, sejam capazes de emitir logs e ofereçam mecanismos para rollbacks e condições de parada sempre que possível.
Um conjunto de ferramentas ou framework eficaz que ofereça suporte à engenharia do caos deve monitorar o estado atual de um experimento, emitir logs e fornecer mecanismos de rollback para acomodar à execução controlada de um experimento. Comece com um serviço estabelecido, como o AWS FIS, que permita que você realize experimentos com um escopo claramente definido e mecanismos de segurança que reverterão o experimento se ele introduzir turbulência inesperada. Para saber mais sobre uma variedade maior de experimentos usando o AWS FIS, consulte também o laboratório Aplicações resilientes e bem arquitetadas com engenharia do caos
. Além disso, o AWS Resilience Hub analisará sua workload e criará experimentos que podem ser escolhidos para implementação e execução no AWS FIS. nota
Para cada experimento, entenda claramente o escopo e seu impacto. Recomendamos que as falhas sejam simuladas primeiro em um ambiente de não produção, antes de serem executadas em produção.
Os experimentos devem ser executados em produção sob carga real usando implantações canário
que ativam a implantação de um sistema de controle e experimental, sempre que possível. A realização de experimentos durante horários fora de pico é uma boa prática para mitigar o impacto potencial durante o primeiro experimento na produção. Além disso, se o uso de tráfego real de clientes for algo muito arriscado, você poderá executar experimentos usando tráfego sintético na infraestrutura de produção nas implantações de controle e experimentais. Quando não for possível usar a produção, realize os experimentos em ambientes de pré-produção que sejam o mais parecido possível com a produção. Estabeleça e monitore barreiras de proteção para garantir que o experimento não afete o tráfego de produção ou outros sistemas além dos limites aceitáveis. Estabeleça condições de parada para interromper um experimento se ele atingir um limite definido de uma métrica de barreira de proteção. Isso deve incluir as métricas de estado estável da workload, bem como a métrica em relação aos componentes em que você está injetando a falha. Um monitor sintético (também conhecido como canário de usuário) é uma métrica que geralmente deve ser incluída como proxy de usuário. As condições de parada para AWS FIS são aceitas como parte do modelo de experimento, permitindo até cinco condições de parada por modelo.
Um dos princípios de caos é minimizar o escopo do experimento e seu impacto:
Embora deva existir uma provisão para algum impacto negativo de curto prazo, é responsabilidade e obrigação do engenheiro de caos garantir que as perdas dos experimentos sejam minimizadas e contidas.
Um método para verificar o escopo e o impacto potencial é realizar o experimento primeiro em um ambiente de não produção, verificando se os limites para as condições de parada são ativados conforme o esperado durante o experimento e se há observabilidade em vigor para identificar uma exceção, em vez de testar diretamente em produção.
Ao executar experimentos de injeção de falhas, verifique se todas as partes responsáveis estão bem informadas. Comunique-se com as equipes adequadas, como equipes de operações, equipes de confiabilidade do serviço e atendimento ao cliente, para avisá-las sobre quando os experimentos serão realizados e o que esperar. Ofereça a essas equipes ferramentas de comunicação para que informem os responsáveis pela execução do experimento caso percebam algum efeito adverso.
Você deve restaurar a workload e seus sistemas subjacentes de volta para o estado íntegro original. Normalmente, o design resiliente da workload irá se restaurar automaticamente. No entanto, alguns designs de falhas ou experimentos malsucedidos podem deixar a workload em um estado de falha inesperado. Ao final do experimento, você deverá estar ciente disso e restaurar a workload e os sistemas. Com o AWS FIS, é possível definir uma configuração de reversão (também chamada de ação posterior) nos parâmetros de ação. Uma ação posterior retorna o destino ao estado em que estava antes da execução da ação. Independentemente de serem automatizadas (como as que usam o AWS FIS) ou manuais, essas ações posteriores devem fazer parte de um playbook que descreve como detectar e lidar com falhas.
-
Verifique a hipótese.
Os Princípios da engenharia do caos
oferecem a seguinte orientação sobre como verificar o estado estável de sua workload: Concentre-se na saída mensurável de um sistema, em vez de atributos internos do sistema. As medições dessa saída durante um curto período constituem um proxy do estado estável do sistema. O throughput total do sistema, as taxas de erros e os percentis de latência podem ser métricas de interesse que representam o comportamento do estado estável. Ao focar em padrões de comportamento sistêmicos durante os experimentos, a engenharia de caos verifica se o sistema de fato funciona em vez de tentar validar como ele funciona.
Nos dois exemplos anteriores, incluímos métricas de estado estável de menos de 0,01% de aumento na quantidade de erros no servidor (5xx) e menos de um minuto de erros de leitura ou gravação de banco de dados.
Os erros 5xx são uma boa métrica, pois são consequência do modo de falha que um cliente da workload vivenciará diretamente. A medição dos erros do banco de dados é boa como consequência direta da falha, mas também deve ser complementada com uma medição de impacto para o cliente, como solicitações malsucedidas ou erros apresentados ao cliente. Além disso, inclua um monitor sintético (também conhecido como canário de usuário) em todas as APIs ou URIs acessadas pelo cliente da workload.
-
Melhore o design da workload para agregar resiliência.
Se o estado estável não tiver sido mantido, investigue como o design da workload pode ser melhorado para mitigar a falha, aplicando as práticas recomendadas do pilar Confiabilidade do AWS Well-Architected. Orientações e recursos adicionais podem ser encontrados na AWS Builder's Library
, a que qual contém artigos sobre como melhorar suas verificações de interidade ou empregar novas tentativas com atraso no código da aplicação , entre outros. Depois de implementar essas mudanças, execute o experimento novamente (mostrado pela linha pontilhada no flywheel de engenharia de caos) para determinar a eficácia. Se a etapa de verificação indicar que a hipótese é verdadeira, a workload estará em estado estável e o ciclo continuará.
-
-
Execute experimentos regularmente.
Um experimento de caos é um ciclo, e os experimentos devem ser realizados regularmente como parte da engenharia de caos. Depois que uma workload cumprir a hipótese do teste, o experimento deverá ser automatizado para ser executado continuamente como parte de regressão do pipeline de CI/CD. Para saber como fazer isso, consulte este blog sobre como realizar experimentos do AWS FIS usando o AWS CodePipeline
. Este laboratório sobre experimentos do AWS FIS recorrentes em um pipeline de CI/CD permite que você trabalhe de forma prática. Os experimentos de injeção de falhas também fazem parte dos game days (consulte REL12-BP05 Conduzir dias de jogo regularmente). Os game days simulam uma falha ou um evento para verificar sistemas, processos e respostas das equipes. O objetivo é executar de fato as ações que a equipe executaria como se um evento excepcional acontecesse.
-
Capture e armazene os resultados do experimento.
Os resultados dos experimentos de injeção de falhas devem ser capturados e persistidos. Inclua todos os dados necessários (como tempo, workload e condições) para poder analisar os resultados e as tendências do experimento posteriormente. Exemplos de resultados podem incluir capturas de tela de painéis, despejos em CSV do banco de dados da métrica ou um registro manual dos eventos e das observações do experimento. O registro em log de experimentos com o AWS FIS pode fazer parte dessa captura de dados.
Recursos
Práticas recomendadas relacionadas:
Documentos relacionados:
Vídeos relacionados:
Ferramentas relacionadas:
