As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Medindo a disponibilidade
Como vimos anteriormente, criar um modelo de disponibilidade voltado para o futuro para um sistema distribuído é difícil e pode não fornecer os insights desejados. O que pode ser mais útil é desenvolver formas consistentes de medir a disponibilidade de sua workload.
A definição de disponibilidade como tempo de atividade e tempo de inatividade representa a falha como uma opção binária, ou a workload está ativa ou não.
No entanto, isso raramente é o caso. A falha tem um grau de impacto e geralmente ocorre em algum subconjunto da workload, afetando uma porcentagem de usuários ou solicitações, uma porcentagem de locais ou um percentual de latência. Todos esses são modos de falha parcial.
E embora o MTTR e o MTBF sejam úteis para entender o que impulsiona a disponibilidade resultante de um sistema e, portanto, como melhorá-lo, sua utilidade não é uma medida empírica de disponibilidade. Além disso, as workloads são compostas por vários componentes. Por exemplo, uma workload, como um sistema de processamento de pagamentos, é composta por várias interfaces de programação de aplicativos (APIs) e subsistemas. Então, quando queremos fazer uma pergunta como “qual é a disponibilidade de toda a workload?” , na verdade, é uma pergunta complexa e cheia de nuances.
Nesta seção, examinaremos três maneiras pelas quais a disponibilidade pode ser medida empiricamente: taxa de sucesso da solicitação do lado do servidor, taxa de sucesso da solicitação do lado do cliente e tempo de inatividade anual.
Taxa sobre o sucesso das solicitações nos lados do servidor e do cliente
Os dois primeiros métodos são muito semelhantes, diferindo apenas do ponto de vista em que a medição é feita. As métricas do lado do servidor podem ser coletadas da instrumentação do serviço. No entanto, eles não estão completos. Se os clientes não conseguirem acessar o serviço, você não conseguirá coletar essas métricas. Para entender a experiência do cliente, em vez de confiar na telemetria dos clientes sobre solicitações malsucedidas, uma maneira mais fácil de coletar métricas do lado do cliente é simular o tráfego do cliente com os canários, um software que examina regularmente seus serviços e registra métricas.
Esses dois métodos calculam a disponibilidade como a fração do total de unidades de trabalho válidas que o serviço recebe e as que ele processa com sucesso (isso ignora unidades de trabalho inválidas, como uma solicitação HTTP que resulta em um erro 404).

Equação 8
Para um serviço baseado em solicitações, a unidade de trabalho é a solicitação, como uma solicitação HTTP. Para serviços baseados em eventos ou tarefas, as unidades de trabalho são eventos ou tarefas, como processar uma mensagem fora de uma fila. Essa medida de disponibilidade é significativa em intervalos curtos, como janelas de um ou cinco minutos. Também é mais adequado em uma perspectiva granular, como em um nível por API para um serviço baseado em solicitações. A figura a seguir fornece uma visão de como pode ser a disponibilidade ao longo do tempo quando calculada dessa forma. Cada ponto de dados no gráfico é calculado usando a Equação (8) em uma janela de cinco minutos (você pode escolher outras dimensões de tempo, como intervalos de um minuto ou dez minutos). Por exemplo, o ponto de dados 10 mostra 94,5% de disponibilidade. Isso significa que, durante os minutos t+45 a t+50, se o serviço recebeu 1.000 solicitações, somente 945 delas foram processadas com sucesso.
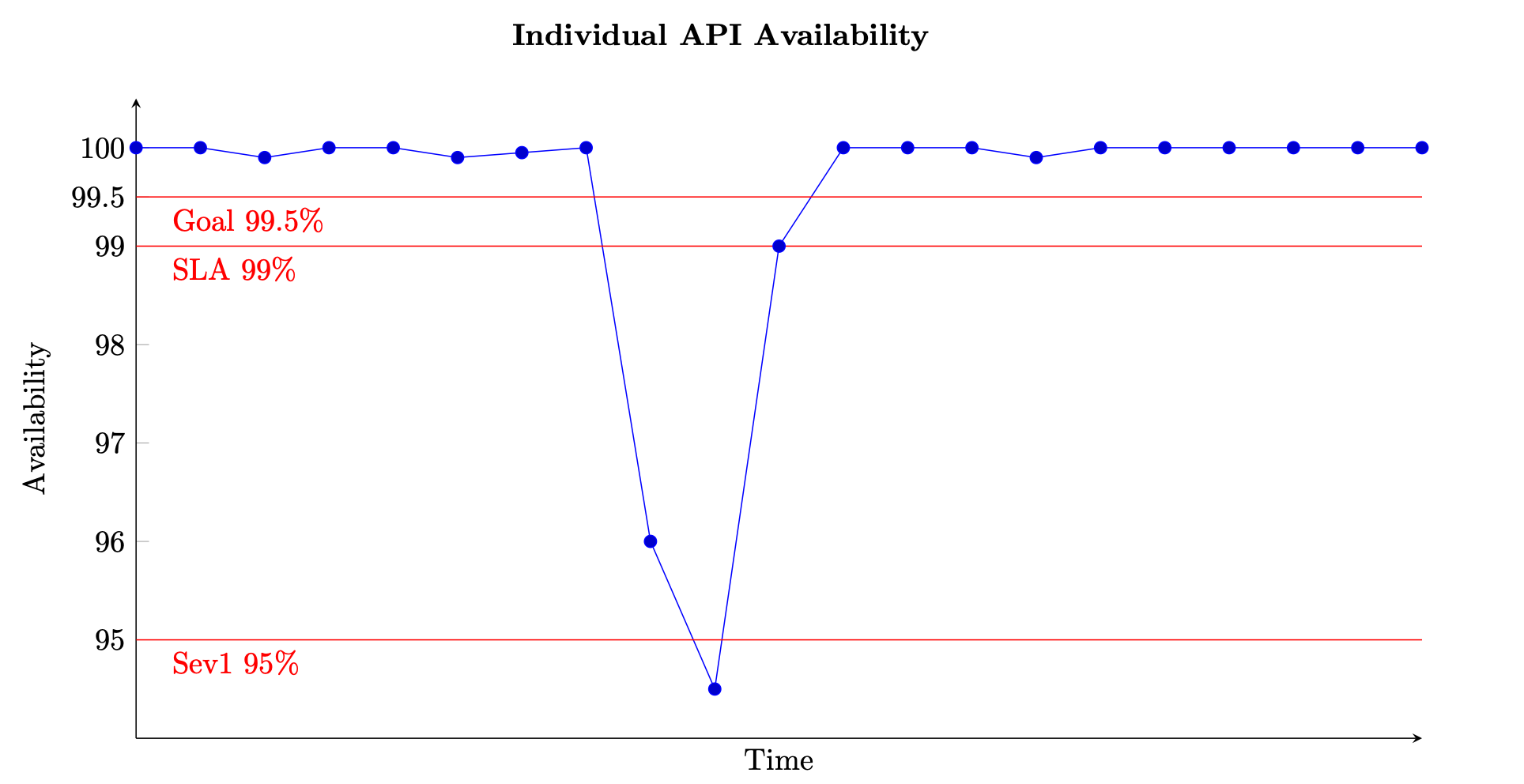
Exemplo de medição da disponibilidade ao longo do tempo para uma única API
O gráfico também mostra a meta de disponibilidade da API, disponibilidade de 99,5%, o acordo de serviço (SLA) que ela oferece aos clientes, 99% de disponibilidade e o limite para um alarme de alta severidade, 95%. Sem o contexto desses diferentes limites, um gráfico de disponibilidade pode não fornecer uma visão significativa de como seu serviço está operando.
Também queremos ser capazes de rastrear e descrever a disponibilidade de um subsistema maior, como um ambiente de gerenciamento ou um serviço inteiro. Uma maneira de fazer isso é obter a média de cada ponto de dados de cinco minutos para cada subsistema. O gráfico será semelhante ao anterior, mas representará um conjunto maior de entradas. Também dá peso igual a todos os subsistemas que compõem seu serviço. Uma abordagem alternativa pode ser somar todas as solicitações recebidas e processadas com sucesso de todas as APIs do serviço para calcular a disponibilidade em intervalos de cinco minutos.
No entanto, esse último método pode ocultar uma API individual com baixo throughput e baixa disponibilidade. Como exemplo simples, considere um serviço com duas APIs.
A primeira API recebe 1.000.000 de solicitações em uma janela de cinco minutos e processa com sucesso 999.000 delas, oferecendo uma disponibilidade de 99,9%. A primeira API recebe 100 de solicitações na mesma janela de cinco minutos e processa com sucesso apenas 50 delas, oferecendo uma disponibilidade de 50%.
Se somarmos as solicitações de cada API, haverá 1.000.100 solicitações válidas no total e 999.050 delas serão processadas com sucesso, oferecendo uma disponibilidade geral de 99,895% para o serviço. Mas, se calcularmos a média das disponibilidades das duas APIs, o método anterior, obteremos uma disponibilidade resultante de 74,95%, o que pode ser mais revelador da experiência real.
Nenhuma abordagem está errada, mas mostra a importância de entender o que as métricas de disponibilidade estão lhe dizendo. Você pode optar por preferir a soma de solicitações para todos os subsistemas se sua workload receber um volume de solicitações semelhante em cada um. Essa abordagem se concentra na “solicitação” e em seu sucesso como medida da disponibilidade e da experiência do cliente. Como alternativa, você pode optar por calcular a média das disponibilidades do subsistema para representar igualmente sua criticidade, apesar das diferenças no volume de solicitações. Essa abordagem se concentra no subsistema e na capacidade de cada um como um substituto para a experiência do cliente.
Tempo de inatividade anual
A terceira abordagem é calcular o tempo de inatividade anual. Essa forma de métrica de disponibilidade é mais apropriada para definição e revisão de metas de longo prazo. Isso exige definir o que significa tempo de inatividade para sua workload. Em seguida, você pode medir a disponibilidade com base no número de minutos em que a workload não esteve em uma condição de “interrupção” em relação ao número total de minutos no período determinado.
Algumas workloads podem definir o tempo de inatividade como algo como uma queda abaixo de 95% da disponibilidade de uma única API ou função de workload por um intervalo de um ou cinco minutos (o que ocorreu no gráfico de disponibilidade anterior). Você também pode considerar apenas o tempo de inatividade, pois ele se aplica a um subconjunto de operações críticas do plano de dados. Por exemplo, o Acordo de Nível de Serviço do Amazon Messaging (SQS, SNS)
Workloads maiores e mais complexas talvez precisem definir métricas de disponibilidade em todo o sistema. Para um grande site de comércio eletrônico, uma métrica de todo o sistema pode ser algo como a taxa de pedidos do cliente. Aqui, uma queda de 10% ou mais nos pedidos em comparação com a quantidade prevista durante qualquer janela de cinco minutos pode definir o tempo de inatividade.
Em qualquer uma das abordagens, você pode então somar todos os períodos de interrupção para calcular uma disponibilidade anual. Por exemplo, se durante um ano civil houve 27 períodos de inatividade de cinco minutos, definidos como a disponibilidade de qualquer API do plano de dados caindo abaixo de 95%, o tempo de inatividade geral foi de 135 minutos (alguns períodos de cinco minutos podem ter sido consecutivos, outros isolados), representando uma disponibilidade anual de 99,97%.
Esse método adicional de medir a disponibilidade pode fornecer dados e insights ausentes nas métricas do lado do cliente e do lado do servidor. Por exemplo, considere uma workload prejudicada e com taxas de erro significativamente elevadas. Os clientes dessa workload podem parar completamente de fazer chamadas para seus serviços. Talvez eles tenham ativado um disjuntor ou seguido seu plano de recuperação de desastres
Latência
Por fim, também é importante medir a latência das unidades de trabalho de processamento em sua workload. Parte da definição de disponibilidade é fazer o trabalho dentro de um SLA estabelecido. Se o retorno de uma resposta demorar mais do que o tempo limite do cliente, a percepção do cliente é de que a solicitação falhou e a workload não está disponível. No entanto, no lado do servidor, a solicitação pode parecer ter sido processada com sucesso.
A medição da latência fornece outra lente para avaliar a disponibilidade. Usar percentis e média reduzida são boas estatísticas para essa medição. Eles são comumente medidos no percentil 50 (P50 e TM50) e no percentil 99 (P99 e TM99). A latência deve ser medida com canários para representar a experiência do cliente, bem como com métricas do lado do servidor. Sempre que a média de algum percentual de latência, como P99 ou TM99.9, ultrapassar o SLA desejado, considere esse tempo de inatividade, que contribui para o cálculo anual do tempo de inatividade.
