As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Confiabilidade
Definição
Confiabilidade se refere à capacidade de um serviço ou sistema de realizar sua função esperada quando necessário. A confiabilidade de um sistema pode ser medida pelo nível de sua qualidade operacional dentro de um determinado período de tempo. Compare isso com a resiliência, que se refere à capacidade de um sistema se recuperar de interrupções na infraestrutura ou no serviço de forma dinâmica e confiável.
Para obter mais detalhes sobre como a disponibilidade e a resiliência são usadas para medir a confiabilidade, consulte o Pilar de Confiabilidade do Well-Architected AWS Framework.
Perguntas chave
Disponibilidade
A disponibilidade é a porcentagem de tempo durante a qual uma workload está disponível para uso. As metas comuns incluem 99% (3,65 dias de inatividade permitidos por ano), 99,9% (8,77 horas) e 99,99% (52,6 minutos), com uma abreviação do número de nove na porcentagem (“dois noves” para 99%, “três noves” para 99,9% e assim por diante). A disponibilidade da solução de rede entre AWS e o data center local pode ser diferente da disponibilidade geral da solução ou do aplicativo.
As principais perguntas sobre a disponibilidade de uma solução de rede incluem:
-
Meus AWS recursos podem continuar operando se não conseguirem se comunicar com meus recursos locais? Vice-versa?
-
Devo considerar o tempo de inatividade programado para manutenção planejada como incluído ou excluído da métrica de disponibilidade?
-
Como vou medir a disponibilidade da camada de rede, separada da integridade geral do aplicativo?
A seção Disponibilidade do Well-Architected Framework Reliability Pillar tem sugestões e fórmulas para a disponibilidade do cálculo.
Resiliência
Resiliência é a capacidade de uma workload se recuperar de interrupções na infraestrutura ou nos serviços, adquirir dinamicamente recursos de computação para atender à demanda e mitigar interrupções, como configurações incorretas ou problemas transitórios de rede. Se um componente de rede redundante (link, dispositivos de rede, etc.) não tiver disponibilidade suficiente para fornecer sozinho a função esperada, ele terá baixa resiliência a falhas. A consequência é uma experiência de usuário ruim e degradada.
As principais perguntas para a resiliência de uma solução de rede incluem:
-
Quantas falhas simultâneas e discretas devo permitir?
-
Como posso reduzir pontos únicos de falha com as soluções de conectividade e com minha rede interna?
-
Qual é minha vulnerabilidade a eventos distribuídos de negação de serviço (DDoS)?
Solução técnica
Primeiro, é importante observar que nem toda solução de conectividade de rede híbrida exige um alto nível de confiabilidade e que níveis crescentes de confiabilidade têm um aumento correspondente no custo. Em alguns cenários, um local primário pode exigir conexões confiáveis (redundantes e resilientes), pois o tempo de inatividade tem um impacto maior nos negócios, enquanto sites regionais podem não exigir o mesmo nível de confiabilidade devido ao menor impacto nos negócios em caso de falha. É recomendável consultar as Recomendações de AWS Direct Connect Resiliência
Para obter uma solução confiável de conectividade de rede híbrida no contexto da resiliência, o design precisa levar em consideração os seguintes aspectos:
-
Redundância: tente eliminar qualquer ponto único de falha no caminho de conectividade da rede híbrida, incluindo, mas não se limitando a, conexões de rede, dispositivos de rede de borda, redundância entre zonas de disponibilidade e locais de DX e fontes de alimentação de dispositivos, caminhos de fibra e sistemas operacionais. Regiões da AWS Para a finalidade e o escopo deste whitepaper, a redundância se concentra nas conexões de rede, nos dispositivos de borda (por exemplo, dispositivos de gateway do cliente), na localização do AWS DX e Regiões da AWS (para arquiteturas multirregionais).
-
Componentes de failover confiáveis: em alguns cenários, um sistema pode estar funcionando, mas não estar executando suas funções no nível exigido. Essa situação é comum durante um único evento de falha em que se descobre que os componentes redundantes planejados estavam operando de forma não redundante. Sua carga de rede não tem outro lugar devido ao uso, o que resulta em capacidade insuficiente para toda a solução.
-
Tempo de failover: o tempo de failover é o tempo necessário para que um componente secundário assuma totalmente a função do componente primário. O tempo de failover tem vários fatores: quanto tempo é necessário para detectar a falha, quanto tempo para ativar a conectividade secundária e quanto tempo para notificar o restante da rede sobre a alteração. A detecção de falhas pode ser aprimorada usando o Dead Peer Detection (DPD) para VPN links e o Bidirectional Forwarding Detection (BFD) para links. AWS Direct Connect O tempo para habilitar a conectividade secundária pode ser muito baixo (se essas conexões estiverem sempre ativas), pode ser uma janela de tempo curta (se uma VPN conexão pré-configurada precisar ser ativada) ou maior (se os recursos físicos precisarem ser movidos ou novos recursos configurados). A notificação do restante da rede geralmente ocorre por meio de protocolos de roteamento dentro da rede do cliente, cada um com diferentes tempos de convergência e opções de configuração. A configuração desses protocolos está fora do escopo deste whitepaper.
-
Engenharia de tráfego: a engenharia de tráfego no contexto do projeto resiliente de conectividade de rede híbrida visa abordar como o tráfego deve fluir por várias conexões disponíveis em cenários normais e de falha. É recomendável seguir o conceito de design para falhas, no qual é necessário verificar como a solução funcionará em diferentes cenários de falha e se ela será aceitável pela empresa ou não. Esta seção discute alguns dos casos de uso comuns de engenharia de tráfego que visam aprimorar o nível geral de resiliência da solução de conectividade de rede híbrida. A AWS Direct Connect seção sobre roteamento BGP fala sobre várias opções de engenharia de tráfego para influenciar o fluxo de tráfego (comunidades, preferência BGP local, comprimento do caminho AS). Para projetar uma solução eficaz de engenharia de tráfego, você precisa ter uma boa compreensão de como cada um dos componentes de AWS rede lida com o roteamento IP em termos de avaliação e seleção de rotas, bem como os possíveis mecanismos para influenciar a seleção da rota. Os detalhes sobre isso estão fora do escopo deste documento. Para obter mais informações, consulte Transit Gateway Route Evaluation Order, Site-to-Site VPNRoute Priority e Direct Connect Routing e a BGP documentação, conforme necessário.
nota
Na tabela de VPC rotas, você pode fazer referência a uma lista de prefixos que tem regras adicionais de seleção de rotas. Para obter mais informações sobre esse caso de uso, consulte prioridade de rota para listas de prefixos. AWS Transit Gateway as tabelas de rotas também oferecem suporte a listas de prefixos, mas, uma vez aplicadas, elas são expandidas para entradas de rotas específicas.
Exemplo de Site-to-Site VPN conexões duplas com rotas mais específicas
Esse cenário é baseado em um pequeno site local conectado a uma única Região da AWS conexão redundante via VPN Internet para. AWS Transit Gateway O projeto de engenharia de tráfego descrito na Figura 10 mostra que, com a engenharia de tráfego, você pode influenciar a seleção do caminho que aumenta a confiabilidade da solução de conectividade híbrida da seguinte forma:
-
Conectividade híbrida resiliente: todas VPN as conexões redundantes fornecem a mesma capacidade de desempenho, suportam failover automatizado usando o protocolo de roteamento dinâmico (BGP) e aceleram a detecção de falhas de conexão usando a detecção de pares mortos. VPN
-
Eficiência de desempenho: a configuração ECMP em ambas as VPN conexões AWS Transit Gateway ajuda a maximizar a largura de banda geral da VPN conexão. Como alternativa, ao anunciar rotas diferentes e mais específicas junto com a rota resumida do site, a carga pode ser gerenciada de forma independente nas duas conexões VPN
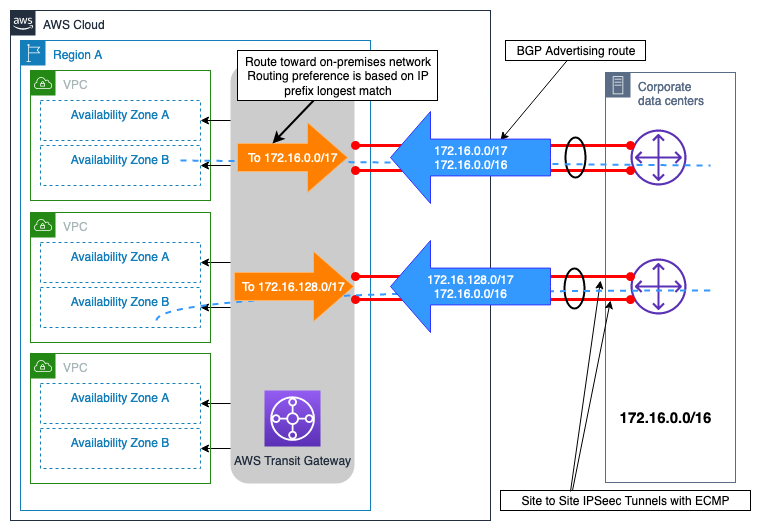
Figura 10 — Exemplo de Site-to-Site VPN conexões duplas com rotas mais específicas
Exemplo de sites on-premises duplos com várias conexões DX
O cenário ilustrado na Figura 11 mostra dois sites de data center locais localizados em diferentes regiões geográficas e conectados AWS usando o modelo de conectividade de resiliência máxima (descrito nas Recomendações de AWS Direct Connect resiliência
Ao associar os atributos da BGP comunidade às rotas anunciadas AWS DXGW, você pode influenciar a seleção lateral do caminho de saída. AWS DXGW Esses atributos da comunidade controlam AWS o atributo de preferência BGP local atribuído à rota anunciada. Para obter mais informações, consulte as políticas e BGP comunidades de roteamento AWS DX.
Para maximizar a confiabilidade da conectividade no Região da AWS nível, cada par de conexões AWS DX é configurado ECMP para que ambas possam ser utilizadas ao mesmo tempo para transferência de dados entre cada site local e. AWS
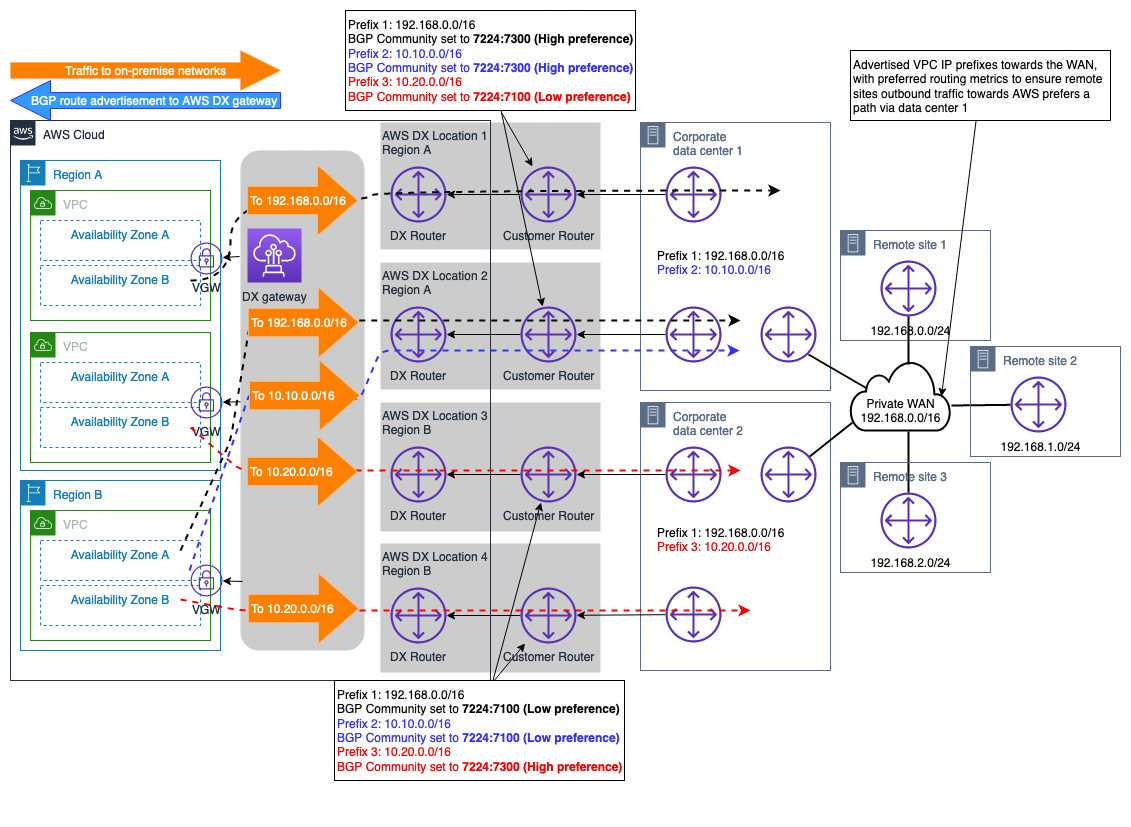
Figura 11 – exemplo de sites on-premises duplos com várias conexões DX
Com esse design, os fluxos de tráfego destinados às redes locais (com o mesmo comprimento de prefixo e BGP comunidade anunciados) serão distribuídos pelas conexões DX duplas por site usando. ECMP No entanto, se não ECMP for necessário em toda a conexão DX, o mesmo conceito discutido anteriormente e descrito na documentação de BGPcomunidades e políticas de roteamento pode ser usado para aprimorar ainda mais a seleção do caminho em um nível de conexão DX.
Nota: Se houver dispositivos de segurança no caminho dentro dos data centers locais, esses dispositivos precisam ser configurados para permitir fluxos de tráfego saindo de um link DX e vindo de outro link DX (ambos os links utilizados comECMP) no mesmo site do data center.
VPNconexão como backup para exemplo de conexão AWS DX
VPNpode ser selecionado para fornecer uma conexão de rede de backup a uma AWS Direct Connect conexão. Normalmente, esse tipo de modelo de conectividade é impulsionado pelo custo, pois fornece um nível mais baixo de confiabilidade à solução geral de conectividade híbrida devido ao desempenho indeterminístico na Internet, e não há nada SLA que possa ser obtido para uma conexão pela Internet pública. É um modelo de conectividade válido e econômico e deve ser usado quando o custo é a principal consideração prioritária e há um orçamento limitado, ou possivelmente como uma solução provisória até que um DX secundário possa ser provisionado. A Figura 12 ilustra o design desse modelo de conectividade. Uma consideração importante com esse design, em que as conexões DX VPN e DX terminam no AWS Transit Gateway, é que a VPN conexão pode anunciar um número maior de rotas em comparação com aquelas que podem ser anunciadas por meio de uma conexão DX conectada a. AWS Transit Gateway Isso pode causar uma situação de roteamento abaixo do ideal. Uma opção para resolver esse problema é configurar a filtragem de rotas no dispositivo de gateway do cliente (CGW) para as rotas recebidas da VPN conexão, permitindo que somente as rotas resumidas sejam aceitas.
Nota: Para criar a rota resumida no AWS Transit Gateway, você precisa especificar uma rota estática para um anexo arbitrário na tabela de AWS Transit Gateway rotas para que o resumo seja enviado ao longo da rota mais específica.
Do ponto de vista da tabela de AWS Transit Gateway roteamento, as rotas para o prefixo local são recebidas da conexão AWS DX (viaDXGW) e deVPN, com o mesmo tamanho de prefixo. Seguindo a lógica de prioridade de rota de AWS Transit Gateway, as rotas recebidas pelo Direct Connect têm uma preferência maior do que as recebidas e Site-to-SiteVPN, portanto, o caminho através delas AWS Direct Connect será o preferido para alcançar a (s) rede (s) local (s).
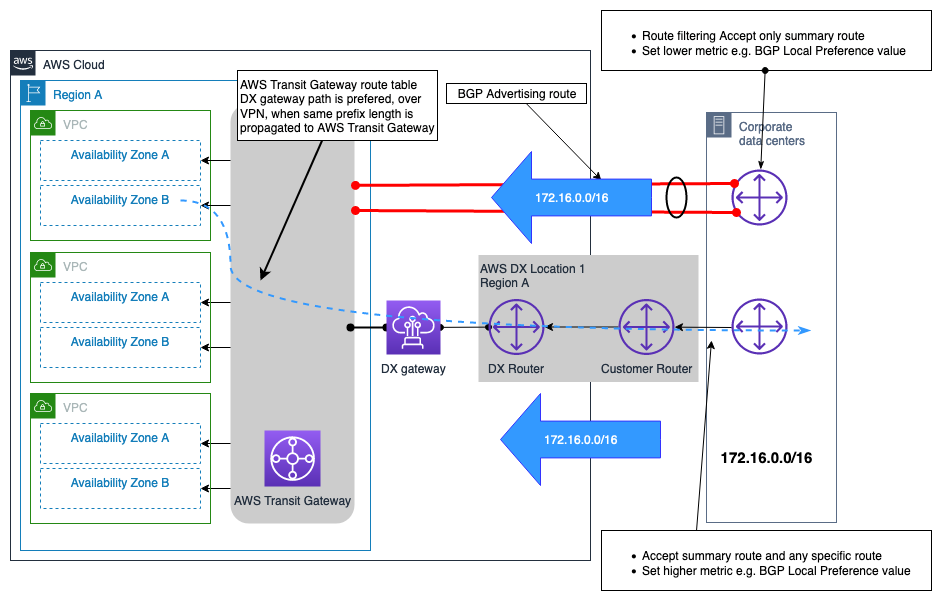
Figura 12 — VPN exemplo de conexão como backup para conexão AWS DX
A árvore decisória a seguir orienta você na tomada da decisão desejada para obter uma conectividade de rede híbrida resiliente (o que resultará em uma conectividade de rede híbrida confiável). Para obter mais informações, consulte o AWS Direct Connect Resiliency Toolkit.
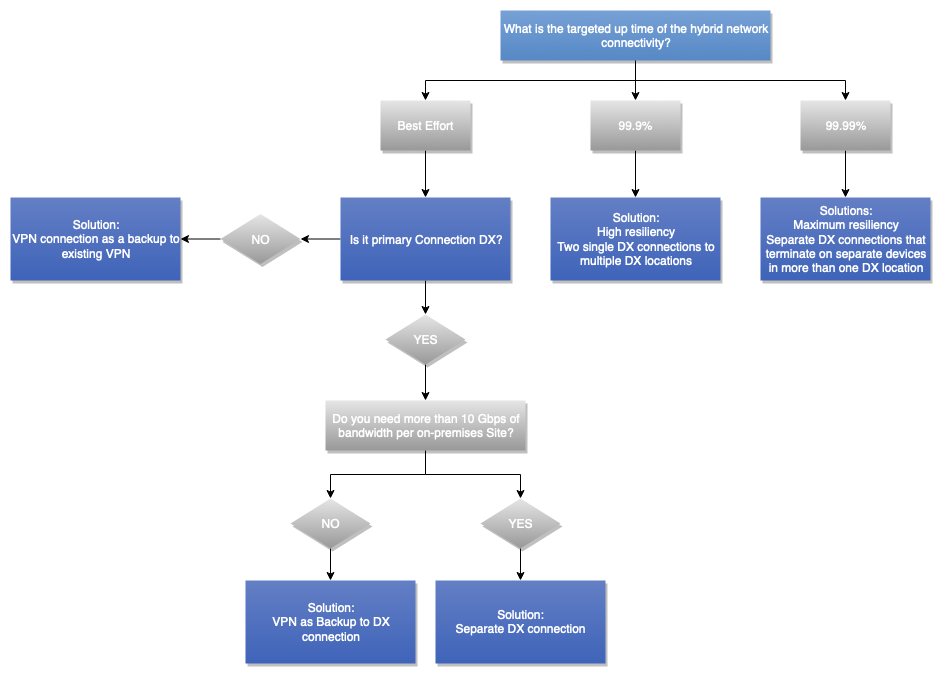
Figura 13 – Árvore de decisão de confiabilidade
