As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Gerenciamento distribuído de dados
Em aplicativos tradicionais, todos os componentes geralmente compartilham um único banco de dados. Por outro lado, cada componente de um aplicativo baseado em microsserviços mantém seus próprios dados, promovendo independência e descentralização. Essa abordagem, conhecida como gerenciamento distribuído de dados, traz novos desafios.
Um desses desafios surge da troca entre consistência e desempenho em sistemas distribuídos. Geralmente, é mais prático aceitar pequenos atrasos nas atualizações de dados (consistência eventual) do que insistir em atualizações instantâneas (consistência imediata).
Às vezes, as operações comerciais exigem que vários microsserviços funcionem juntos. Se uma peça falhar, talvez seja necessário desfazer algumas tarefas concluídas. O padrão Saga ajuda a gerenciar isso coordenando uma série de ações compensatórias.
Para ajudar os microsserviços a permanecerem sincronizados, um armazenamento de dados centralizado pode ser usado. Essa loja, gerenciada com ferramentas como AWS Lambda, AWS Step Functions, e Amazon EventBridge, pode ajudar na limpeza e desduplicação de dados.
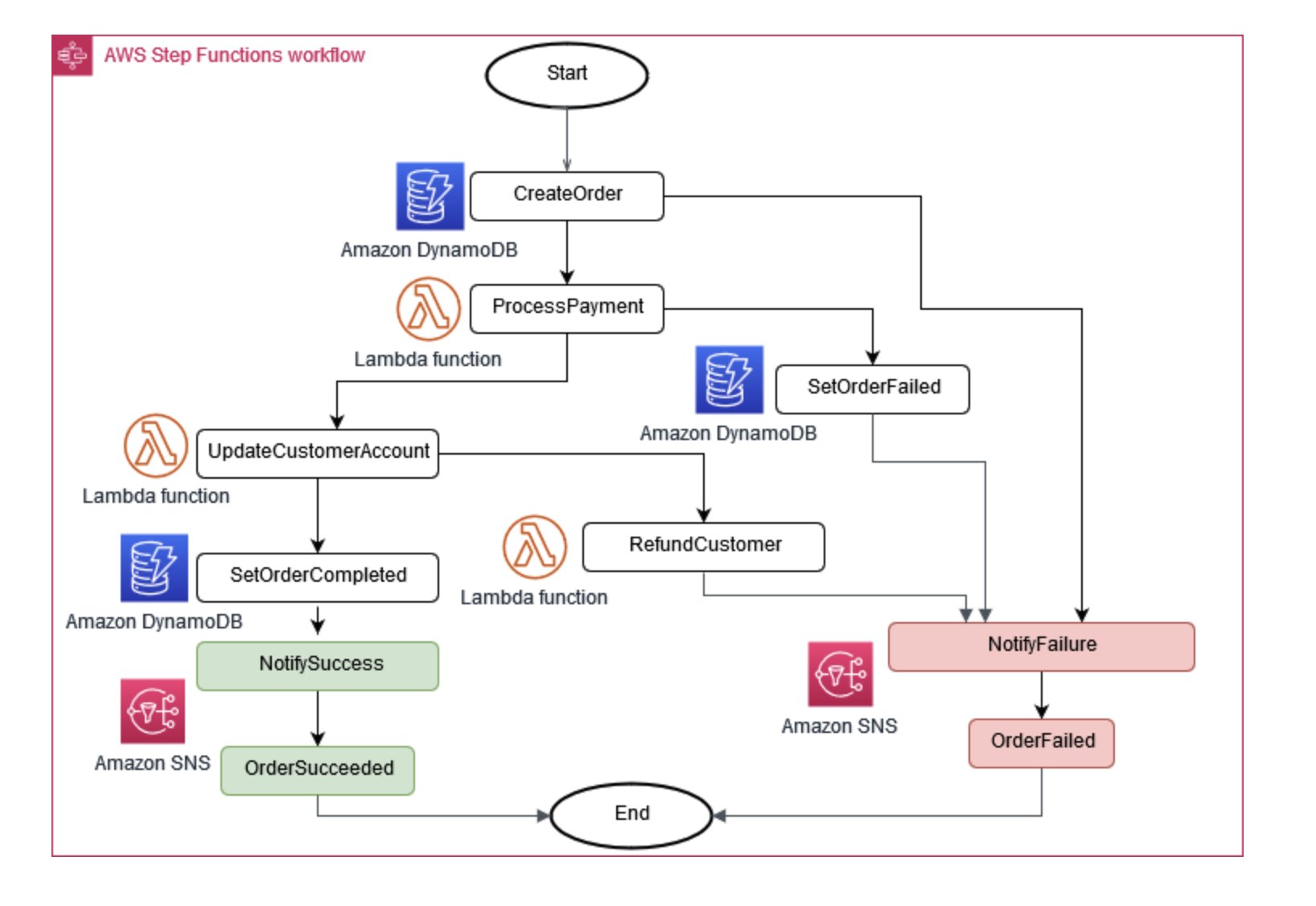
Figura 6: Coordenador de execução da Saga
Uma abordagem comum no gerenciamento de mudanças em microsserviços é o fornecimento de eventos. Cada alteração no aplicativo é registrada como um evento, criando uma linha do tempo do estado do sistema. Essa abordagem não só ajuda a depurar e auditar, mas também permite que diferentes partes de um aplicativo reajam aos mesmos eventos.
O fornecimento de eventos geralmente funciona hand-in-hand com o padrão Command Query Responsibility Segregation (CQRS), que separa a modificação e a consulta de dados em módulos diferentes para melhor desempenho e segurança.
Ativado AWS, você pode implementar esses padrões usando uma combinação de serviços. Como você pode ver na Figura 7, o Amazon Kinesis Data Streams pode servir como sua loja central de eventos, enquanto o Amazon S3 fornece um armazenamento durável para todos os registros de eventos. AWS Lambda, o Amazon DynamoDB e o Amazon API Gateway trabalham juntos para lidar e processar esses eventos.
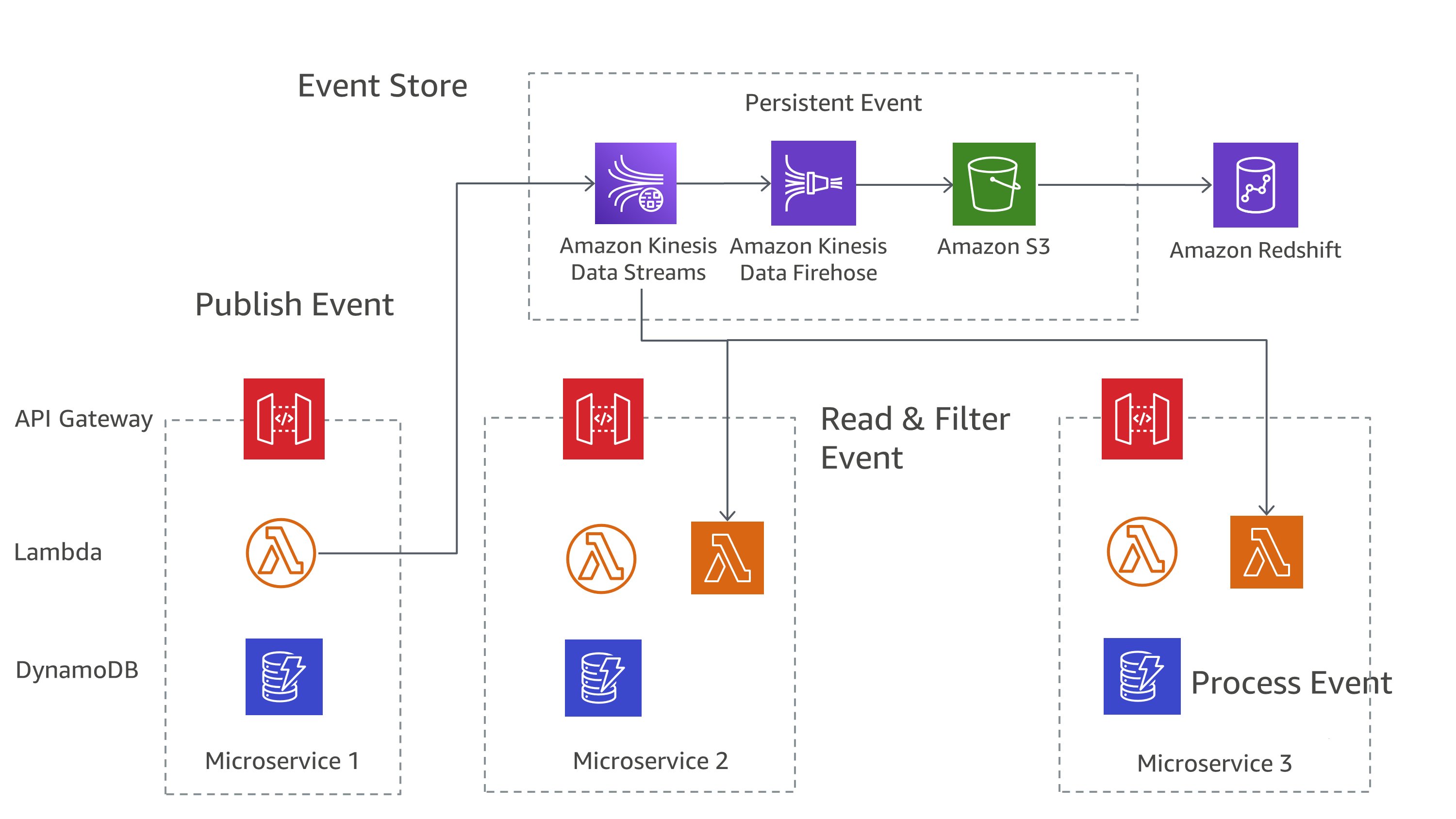
Figura 7: Padrão de fornecimento de eventos em AWS
Lembre-se de que, em sistemas distribuídos, os eventos podem ser entregues várias vezes devido a novas tentativas, por isso é importante projetar seus aplicativos para lidar com isso.
