Etapa 4: Avaliar os previsores
Um fluxo de trabalho típico em machine learning consiste em treinar um conjunto de modelos ou uma combinação de modelos em um conjunto de treinamento e avaliar sua precisão em um conjunto de dados de retenção. Esta seção discute como dividir dados históricos e quais métricas usar para avaliar modelos na previsão de séries temporais. Para a previsão, a técnica de simulação é a principal ferramenta para avaliar a precisão da previsão.
Simulação
Uma estrutura de avaliação e simulação adequada está entre os fatores mais importantes para tornar uma aplicação de machine learning um sucesso. Você pode contar com simulações bem-sucedidas com os modelos para ganhar confiança sobre o poder preditivo futuro dos modelos. Além disso, você pode ajustar os modelos por meio da otimização de hiperparâmetros (HPO), aprender combinações de modelos e ativar o meta-aprendizado e o AutoML.
O tempo característico da previsão de séries temporais o torna diferente, em termos de metodologia de avaliação e simulação, de outros campos de machine learning aplicado. Normalmente, em tarefas de ML, para avaliar o erro preditivo em uma simulação, você divide um conjunto de dados por itens. Por exemplo, para validação cruzada em tarefas relacionadas a imagens, você treina em uma porcentagem das imagens e usa outras partes para testes e validação. Na previsão, é necessário dividir principalmente por tempo (e, em menor grau, por itens) para garantir que você não vaze informações do conjunto de treinamento para o conjunto de teste ou validação e que simule o caso de produção o mais próximo possível.
A divisão por tempo deve ser feita com cuidado, pois você não deseja escolher um único ponto no tempo, mas vários pontos. Caso contrário, a precisão é muito dependente da data de início da previsão, conforme definido pelo ponto de divisão. Uma avaliação de previsão contínua, na qual você faz uma série de divisões em vários momentos e gera o resultado médio, leva a resultados de simulação mais robustos e confiáveis. A seguinte figura ilustra quatro divisões de simulação diferentes.

Ilustração de quatro cenários diferentes de simulação com tamanho de conjunto de treinamento crescente, mas tamanho de teste constante
Na figura anterior, todos os cenários de simulação têm dados disponíveis durante sua totalidade para que seja possível avaliar os valores previstos em relação aos reais.
A razão pela qual várias janelas de simulação são necessárias é que a maioria das séries temporais no mundo real normalmente não são estacionárias. A empresa de comércio eletrônico no estudo de caso está sediada na América do Norte e grande parte da demanda de produtos é impulsionada pelo pico do 4.º trimestre, com picos específicos no Dia de Ação de Graças e antes do Natal. Na temporada de compras do 4.º trimestre, a variabilidade das séries temporais é maior do que no resto do ano. Com várias janelas de simulação, é possível avaliar os modelos de previsão em um ambiente mais equilibrado.
Para cada cenário de simulação, a figura a seguir mostra os elementos básicos na terminologia do Amazon Forecast. O Amazon Forecast divide automaticamente os dados nos conjuntos de dados de treinamento e teste. Ele decide como dividir os dados de entrada usando o parâmetro BackTestWindowOffset que é especificado como um parâmetro na API create_predictor ou usa seu valor padrão de ForecastHorizon.
Na seguinte figura, você vê o primeiro caso mais geral quando os parâmetros BackTestWindowOffset e ForecastHorizon não são iguais. O parâmetro BackTestWindowOffset define a data de início da previsão virtual, exibida como a linha vertical tracejada na figura a seguir. Ele pode ser usado para responder à seguinte pergunta hipotética: se o modelo fosse implantado neste dia, qual seria a previsão? O ForecastHorizon define o número de etapas de tempo a partir da data de início da previsão virtual a serem previstos.
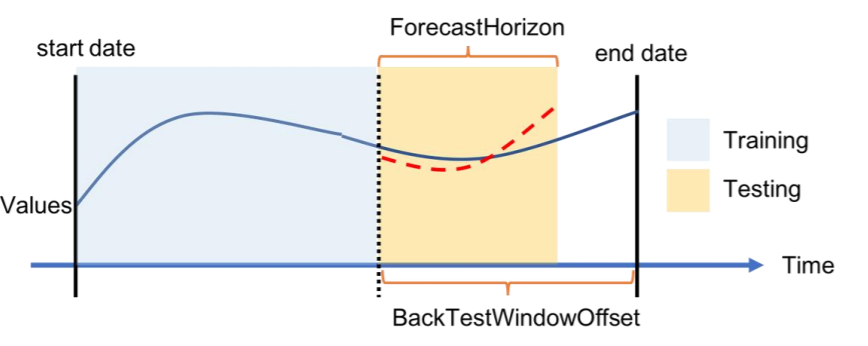
Ilustração de um cenário de simulação única e sua configuração no Amazon Forecast
O Amazon Forecast pode exportar os valores previstos e as métricas de precisão geradas durante a simulação. Os dados exportados podem ser usados para avaliar itens específicos em momentos e quantis específicos.
Quantis de previsão e métricas de precisão
Os quantis de previsão podem fornecer um limite superior e inferior para as previsões. Por exemplo, usar os tipos de previsão 0,1 (P10), 0,5 (P50) e 0,9 (P90) fornece uma faixa de valores conhecida como intervalo de confiança de 80% em torno da previsão P50. Ao gerar previsões em P10, P50 e P90, você pode esperar que o valor real fique entre esses limites em 80% das vezes.
Este artigo discute ainda mais os quantis na Etapa 5.
O Amazon Forecast usa as métricas de precisão de Weighted Quantile Loss (wQL – Perda quantil ponderada), Root Mean Square Error (RMSE – Raiz do erro quadrático médio) e Weighted Absolute Percentage Error (WAPE – Erro percentual absoluto ponderado) para avaliar os previsores durante a simulação.
Perda quantil ponderada (wQL)
A métrica de erro de perda quantil ponderada (wQL) mede a precisão da previsão de um modelo em um quantil especificado. É particularmente útil quando há custos diferentes de subprevisão e superprevisão. Definir o peso (τ) da função wQL incorpora automaticamente diferentes penalidades por subprevisão e superprevisão.
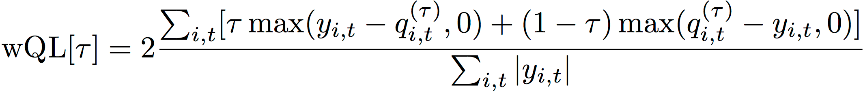
Função wQL
Onde:
-
τ – Um conjunto no quantil {0,01, 0,02, ..., 0,99}
-
qi,t(τ) – O quantil-τ que o modelo prevê.
-
yi,t – O valor observado no ponto (i,t)
Erro percentual absoluto ponderado (WAPE)
O erro percentual absoluto ponderado (WAPE) é uma métrica comumente usada para medir a precisão do modelo. Ele mede o desvio geral dos valores previstos em relação aos valores observados.
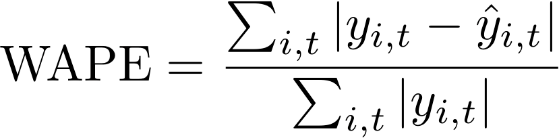
WAPE
Onde:
-
yi,t – O valor observado no ponto (i,t)
-
ŷi,t – O valor observado no ponto (i,t)
A previsão usa a previsão média como o valor previsto, ŷi,t.
Raiz do erro quadrático médio (RMSE)
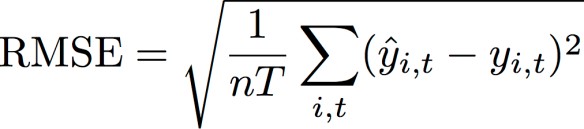
A raiz do erro quadrático médio (RMSE) é uma métrica comumente usada para medir a precisão do modelo. Como o WAPE, ele mede o desvio geral das estimativas em relação aos valores observados.
Onde:
-
yi,t – O valor observado no ponto (i,t)
-
ŷi,t – O valor observado no ponto (i,t)
-
nT – O número de pontos de dados em um conjunto de testes
A previsão usa a previsão média como o valor previsto, ŷi,t. Ao calcular métricas previsoras, nT é o número de pontos de dados em uma janela de simulação.
Problemas com WAPE e RMSE
Na maioria dos casos, as previsões pontuais que podem ser geradas internamente ou de outras ferramentas de previsão devem corresponder ao quantil p50 ou às previsões médias. Tanto para o WAPE quanto para o RMSE, o Amazon Forecast usa a previsão média para representar o valor previsto (yhat).
Para tau = 0,5 na equação wQL[tau], os dois pesos são iguais, e a wQL [0,5] se reduz ao erro percentual absoluto ponderado (WAPE) comumente usado para previsões pontuais:
![Imagem da equação wQL [0,5].](images/wql.png)
em que yhat = q(0,5) é a previsão computacional. Um fator de escalabilidade 2 é usado na fórmula wQL para cancelar o fator 0,5 para obter a expressão WAPE[mediana] exata.
Observe que a definição acima do WAPE difere de uma interpretação comum para o erro percentual absoluto médio (MAPE
Ao contrário da métrica de perda quantil ponderada para tau diferente de 0,5, a tendência inerente em cada quantil não pode ser capturada por um cálculo como o WAPE, no qual os pesos são iguais. Outras desvantagens do WAPE incluem que ele não é simétrico, tem uma superinflação de erros percentuais para números pequenos e é apenas uma métrica pontual.
O RMSE é o quadrado do termo de erro no WAPE e uma métrica de erro comum em outras aplicações de ML. A métrica RMSE favorece um modelo no qual os erros individuais são de magnitude consistente, como grandes variações de erros que aumentarão a RMSE de forma proporcional exagerada. Devido ao erro quadrático, alguns valores mal previstos em uma previsão que, do contrário, seria adequada podem aumentar o RMSE. Além disso, devido aos termos quadráticos, os termos de erro menores têm menos peso no RMSE do que no WAPE.
As métricas de precisão permitem uma avaliação quantitativa das previsões. Em especial para comparações em grande escala (o método A é melhor do que o método B em geral), elas são cruciais. No entanto, complementar isso com imagens para SKUs individuais é importante.
