Refreshing SPICE data
Refreshing a dataset
Use the following procedure to refresh a SPICE dataset based on an Amazon S3 or database data source on the Datasets page.
To refresh SPICE data from the datasets page
-
On the Datasets page, choose the dataset to open it.
-
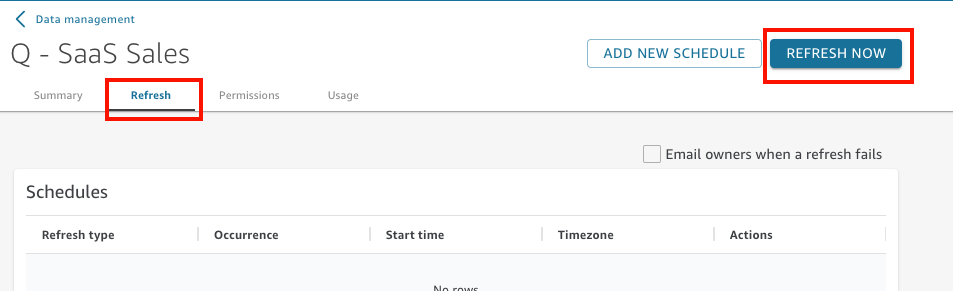
On the dataset details page that opens, choose the Refresh tab and then choose Refresh now.
-
Keep the refresh type as Full refresh.
-
If you are refreshing an Amazon S3 dataset, choose one of the following options for S3 Manifest:
-
To use the same manifest file you last provided to Amazon QuickSight, choose Existing Manifest. If you have changed the manifest file at the file location or URL that you last provided, the data returned reflects those changes.
-
To specify a new manifest file by uploading it from your local network, choose Upload Manifest, and then choose Upload manifest file. For Open, choose a file, and then choose Open.
-
To specify a new manifest file by providing a URL, enter the URL of the manifest in Input manifest URL. You can find the manifest file URL in the Amazon S3 console by opening the context (right-click) menu for the manifest file, choosing Properties, and looking at the Link box.
-
-
Choose Refresh.
-
If you are refreshing an Amazon S3 dataset, choose OK, then OK again.
If you are refreshing a database dataset, choose OK.
Incrementally refreshing a dataset
| Applies to: Enterprise Edition |
For SQL-based data sources, such as Amazon Redshift, Amazon Athena, PostgreSQL, or Snowflake, you can refresh your data incrementally within a look-back window of time.
An incremental refresh queries only data defined by the dataset within a specified look-back window. It transfers all insertions, deletions, and modifications to the dataset, within that window's timeframe, from its source to the dataset. The data currently in SPICE that's within that window is deleted and replaced with the updates.
With incremental refreshes, less data is queried and transferred for each refresh. For example, let's say you have a dataset with 180,000 records that contains data from January 1 to June 30. On July 1, you run an incremental refresh on the data with a look-back window of seven days. QuickSight queries the database asking for all data since June 24 (7 days ago), which is 7,000 records. QuickSight then deletes the data currently in SPICE from June 24 and after, and appends the newly queried data. The next day (July 2), QuickSight does the same thing, but queries from June 25 (7,000 records again), and then deletes from the existing dataset from the same date. Rather than having to ingest 180,000 records every day, it only has to ingest 7,000 records.
Use the following procedure to incrementally refresh a SPICE dataset based on a SQL data source on the Datasets page.
To incrementally refresh a SQL-based SPICE dataset
-
On the Datasets page, choose the dataset to open it.
-
On the dataset details page that opens, choose the Refresh tab and then choose Refresh now.
-
For Refresh type, choose Incremental refresh.
-
If this is your first incremental refresh on the dataset, choose Configure.
-
On the Configure incremental refresh page, do the following:
-
For Date column, choose a date column that you want to base the look-back window on.
-
For Window size, enter a number for size, and then choose an amount of time that you want to look back for changes.
You can choose to refresh changes to the data that occurred within a specified number of hours, days, or weeks from now. For example, you can choose to refresh changes to the data that occurred within two weeks of the current date.
-
-
Choose Submit.
Refreshing a dataset during data preparation
Use the following procedure to refresh a SPICE dataset based on an Amazon S3 or database data source during data preparation.
To refresh SPICE data during data preparation
-
On the Datasets page, choose the dataset, and then choose Edit Data Set.
-
On the dataset screen, choose Refresh now.
-
Keep the refresh type set to Full refresh.
-
(Optional) If you are refreshing an Amazon S3 dataset, choose one of the following options for S3 Manifest:
-
To use the same manifest file that you last provided to Amazon QuickSight, choose Existing Manifest. If you have changed the manifest file at the file location or URL that you last provided, the data returned reflects those changes.
-
To specify a new manifest file by uploading it from your local network, choose Upload Manifest, and then choose Upload manifest file. For Open, choose a file, and then choose Open.
-
To specify a new manifest file by providing a URL, enter the URL of the manifest in Input manifest URL. You can find the manifest file URL in the Amazon S3 console by opening the context (right-click) menu for the manifest file, choosing Properties, and looking at the Link box.
-
-
Choose Refresh.
-
If you are refreshing an Amazon S3 dataset, choose OK, then OK again.
If you are refreshing a database dataset, choose OK.
Refreshing a dataset on a schedule
Use the following procedure to schedule refreshing the data. If your dataset is based on a direct query and not stored in SPICE, you can refresh your data by opening the dataset. You can also refresh your data by refreshing the page in an analysis or dashboard.
To refresh SPICE data on a schedule
-
On the Datasets page, choose the dataset to open it.
-
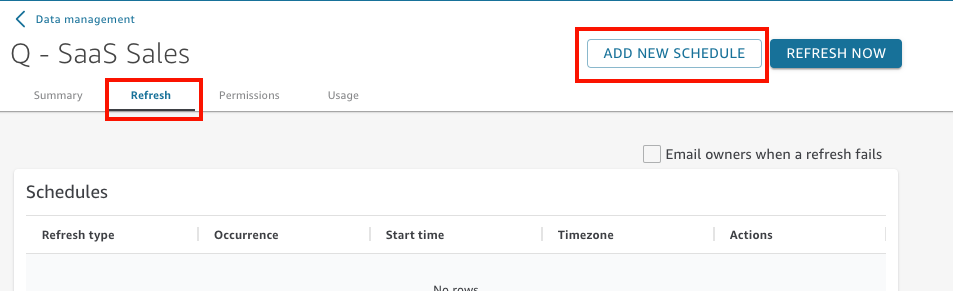
On the dataset details page that opens, choose the Refresh tab and then choose Add new schedule.
-
On the Create a refresh schedule screen, choose settings for your schedule:
-
For Time zone, choose the time zone that applies to the data refresh.
-
For Starting time, choose a date and time for the refresh to start. Use HH:MM and 24-hour format, for example 13:30.
-
For Frequency, choose one of the following:
-
For Standard or Enterprise editions, you can choose Daily, Weekly, or Monthly.
-
Daily: Repeats every day.
-
Weekly: Repeats on the same day of each week.
-
Monthly: Repeats on the same day number of each month. To refresh data on the 29th, 30th or 31st day of the month, choose Last day of month from the list.
-
-
For Enterprise edition only, you can choose Hourly. This setting refreshes your dataset every hour, beginning at the time that you choose. So, if you select 1:05 as the starting time, the data refreshes at five minutes after the hour, every hour.
If you decide to use an hourly refresh, you can't also use additional refresh schedules. To create an hourly schedule, remove any other existing schedules for that dataset. Also, remove any existing hourly schedule before you create a daily, weekly, or monthly schedule.
-
-
-
Choose Save.
Scheduled dataset ingestions take place within 10 minutes of the scheduled date and time.
Using the Amazon QuickSight console, you can create five schedules for each dataset. When you have created five, the Create button is turned off.
Incrementally refreshing a dataset on a schedule
| Applies to: Enterprise Edition |
For SQL-based data sources, such as Amazon Redshift, Athena, PostgreSQL, or Snowflake, you can schedule incremental refreshes. Use the following procedure to incrementally refresh a SPICE dataset based on a SQL data source on the Datasets page.
To set an incremental refresh schedule for a SQL-based SPICE dataset
-
On the Datasets page, choose the dataset to open it.
-
On the dataset details page that opens, choose the Refresh tab and then choose Add new schedule.
-
On the Create a schedule page, for Refresh type, choose Incremental refresh.
-
If this is your first incremental refresh for this dataset, choose Configure, and then do the following:
-
For Date column, choose a date column that you want to base the look-back window on.
-
For Window size, enter a number for size, and then choose an amount of time that you want to look back for changes.
You can choose to refresh changes to the data that occurred within a specified number of hours, days, or weeks from now. For example, you can choose to refresh changes to the data that occurred within two weeks of the current date.
-
Choose Submit.
-
-
For Time zone, choose the time zone that applies to the data refresh.
-
For Repeats, choose one of the following:
-
You can choose Every 15 minutes, Every 30 minutes, Hourly, Daily, Weekly, or Monthly.
-
Every 15 minutes: Repeats every 15 minutes, beginning at the time you choose. So, if you select 1:05 as the starting time, the data refreshes at 1:20, then again at 1:35, and so on.
-
Every 30 minutes: Repeats every 30 minutes, beginning at the time you choose. So, if you select 1:05 as the starting time, the data refreshes at 1:35, then again at 2:05, and so on.
-
Hourly: Repeats every hour, beginning at the time you choose. So, if you select 1:05 as the starting time, the data refreshes at five minutes after the hour, every hour.
-
Daily: Repeats every day.
-
Weekly: Repeats on the same day of each week.
-
Monthly: Repeats on the same day number of each month. To refresh data on the 29th, 30th or 31st day of the month, choose Last day of month from the list.
-
-
If you decide to use refresh every 15 or 30 minutes, or hourly, you can't also use additional refresh schedules. To create a refresh schedule every 15 minutes, 30 minutes, or hourly, remove any other existing schedules for that dataset. Also, remove any existing minute or hourly schedule before you create a daily, weekly, or monthly schedule.
-
-
For Starting, choose a date for the refresh to start.
-
For At, specify the time that the refresh should start. Use HH:MM and 24-hour format, for example 13:30.
Scheduled dataset ingestions take place within 10 minutes of the scheduled date and time.
In some cases, something might go wrong with the incremental refresh dataset that makes you want to roll back your dataset. Or you might no longer want to refresh the dataset incrementally. If so, you can delete the scheduled refresh.
To do so, choose the dataset on the Datasets page, choose Schedule a refresh, and then choose the x icon to the right of the scheduled refresh. Deleting an incremental refresh configuration starts a full refresh. As part of this full refresh, all the configurations prepared for incremental refreshes are removed.
