Troubleshooting
The following FAQs can help you troubleshoot issues with your Amazon SageMaker Asynchronous Inference endpoints.
You can use the following methods to find the instance count behind your endpoint:
You can use the SageMaker AI DescribeEndpoint API to describe the number of instances behind the endpoint at any given point in time.
You can get the instance count by viewing your Amazon CloudWatch metrics. View the metrics for your endpoint instances, such as
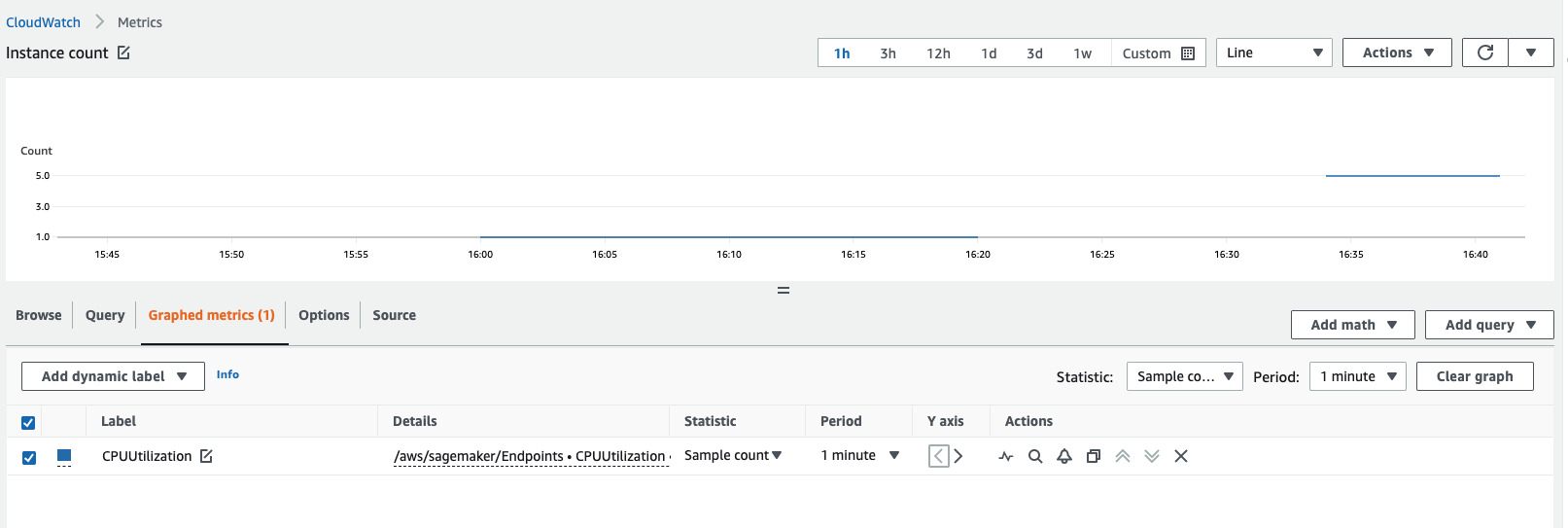
CPUUtilizationorMemoryUtilizationand check the sample count statistic for a 1 minute period. The count should be equal to the number of active instances. The following screenshot shows theCPUUtilizationmetric graphed in the CloudWatch console, where the Statistic is set toSample count, the Period is set to1 minute, and the resulting count is 5.
The following tables outline the common tunable environment variables for SageMaker AI containers by framework type.
TensorFlow
| Environment variable | Description |
|---|---|
|
|
For TensorFlow-based models, the |
|
|
This parameter governs the fraction of the available GPU memory to initialize CUDA/cuDNN and other GPU libraries. |
|
This ties back to the |
|
This ties back to the |
|
This governs the number of worker processes that Gunicorn is requested to spawn for handling requests. This value is used in combination with other parameters
to derive a set that maximizes inference throughput. In addition to this, the |
|
This governs the number of worker processes that Gunicorn is requested to spawn for handling requests. This value is used in combination with other parameters
to derive a set that maximizes inference throughput. In addition to this, the |
|
Python internally uses OpenMP for implementing multithreading within processes. Typically, threads equivalent to the number of CPU cores are spawned.
But when implemented on top of Simultaneous Multi Threading (SMT), such Intel’s HypeThreading, a certain process might oversubscribe a particular core by spawning
twice as many threads as the number of actual CPU cores. In certain cases, a Python binary might end up spawning up to four times as many threads as available processor cores.
Therefore, an ideal setting for this parameter, if you have oversubscribed available cores using worker threads, is |
|
|
In some cases, turning off MKL can speed up inference if |
PyTorch
| Environment variable | Description |
|---|---|
|
|
This is the maximum batch delay time TorchServe waits to receive. |
|
|
If TorchServe doesn’t receive the number of requests specified in |
|
|
The minimum number of workers to which TorchServe is allowed to scale down. |
|
|
The maximum number of workers to which TorchServe is allowed to scale up. |
|
|
The time delay, after which inference times out in absence of a response. |
|
|
The maximum payload size for TorchServe. |
|
|
The maximum response size for TorchServe. |
Multi Model Server (MMS)
| Environment variable | Description |
|---|---|
|
|
This parameter is useful to tune when you have a scenario where the type of the inference request payload is large, and due to the size of payload being larger, you may have
higher heap memory consumption of the JVM in which this queue is being maintained. Ideally you might want to keep the heap memory requirements of JVM lower and allow Python workers
to allot more memory for actual model serving. JVM is only for receiving the HTTP requests, queuing them, and dispatching them to the Python-based workers for inference. If you increase
the |
|
|
This parameter is for the backend model serving and might be valuable to tune since this is the critical component of the overall model serving, based on which the Python processes spawn threads for each Model. If this component is slower (or not tuned properly), the front-end tuning might not be effective. |
You can use the same container for Asynchronous Inference that you do for Real-Time Inference or Batch Transform. You should confirm that the timeouts and payload size limits on your container are set to handle larger payloads and longer timeouts.
Refer to the following limits for Asynchronous Inference:
Payload size limit: 1 GB
Timeout limit: A request can take up to 60 minutes.
Queue message TimeToLive (TTL): 6 hours
Number of messages that can be put inside Amazon SQS: Unlimited. However, there is a quota of 120,000 for the number of in-flight messages for a standard queue, and 20,000 for a FIFO queue.
In general, with Asynchronous Inference, you can scale out based on invocations or instances. For invocation metrics, it's a good idea to look at your ApproximateBacklogSize,
which is a metric that defines the number of items in your queue that have yet to been processed. You can utilize this metric or your InvocationsPerInstance metric to understand what
TPS you may be getting throttled at. At the instance level, check your instance type and its CPU/GPU utilization to define when to scale out. If a singular instance is
above 60-70% capacity, this is often a good sign that you are saturating your hardware.
We don't recommend having multiple scaling policies, as these can conflict and lead to confusion at the hardware level, causing delays when scaling out.
Check if your container is able to handle ping and invoke requests concurrently. SageMaker AI invoke requests take approximately 3 minutes, and in this duration, usually
multiple ping requests end up failing due to the timeout causing SageMaker AI to detect your container as Unhealthy.
Yes. MaxConcurrentInvocationsPerInstance is a feature of asynchronous endpoints. This does not depend on the custom container implementation.
MaxConcurrentInvocationsPerInstance controls the rate at which invoke requests are sent to the customer container. If this value is set as 1, then only 1 request is sent
to the container at a time, no matter how many workers are on the customer container.
The error means that the customer container returned an error. SageMaker AI does not control the behavior of customer containers. SageMaker AI simply returns the response from the ModelContainer
and does not retry. If you want, you can configure the invocation to retry on failure. We suggest that you turn on container logging and check your container logs to find the root cause
of the 500 error from your model. Check the corresponding CPUUtilization and MemoryUtilization metrics at the point of failure as well.
You can also configure the S3FailurePath
to the model response in Amazon SNS as part of the Async Error Notifications to investiage failures.
You can check the metric InvocationsProcesssed, which should align with the number of invocations that you expect to be processed in a minute based on single concurrency.
The best practice is to enable Amazon SNS, which is a notification service for messaging-oriented applications, with multiple subscribers requesting and receiving "push"
notifications of time-critical messages from a choice of transport protocols, including HTTP, Amazon SQS, and email. Asynchronous Inference posts notifications when you create an endpoint with
CreateEndpointConfig and specify an Amazon SNS topic.
To use Amazon SNS to check prediction results from your asynchronous endpoint, you first need to create a topic, subscribe to the topic, confirm your subscription to the topic, and note the Amazon Resource Name (ARN) of that topic. For detailed information on how to create, subscribe, and find the Amazon ARN of an Amazon SNS topic, see Configuring Amazon SNS in the Amazon SNS Developer Guide. For more information about how to use Amazon SNS with Asynchronous Inference, see Check prediction results.
Yes. Asynchronous Inference provides a mechanism to scale down to zero instances when there are no requests. If your endpoint has been scaled down to zero instances during these periods,
then your endpoint won’t scale up again until the number of requests in the queue exceeds the target specified in your scaling policy. This can result in long waiting times for requests
in the queue. In such cases, if you want to scale up from zero instances for new requests less than the queue target specified, you can use an additional scaling policy called
HasBacklogWithoutCapacity. For more information about how to define this scaling policy, see
Autoscale an asynchronous endpoint.
For an exhaustive list of instances supported by Asynchronous Inference per region, see SageMaker pricing
