Asynchronous inference
Amazon SageMaker Asynchronous Inference is a capability in SageMaker AI that queues incoming requests and processes them asynchronously. This option is ideal for requests with large payload sizes (up to 1GB), long processing times (up to one hour), and near real-time latency requirements. Asynchronous Inference enables you to save on costs by autoscaling the instance count to zero when there are no requests to process, so you only pay when your endpoint is processing requests.
How It Works
Creating an asynchronous inference endpoint is similar to creating real-time inference
endpoints. You can use your existing SageMaker AI models and only need to specify the
AsyncInferenceConfig object while creating your endpoint configuration
with the EndpointConfig field in the CreateEndpointConfig API.
The following diagram shows the architecture and workflow of Asynchronous Inference.
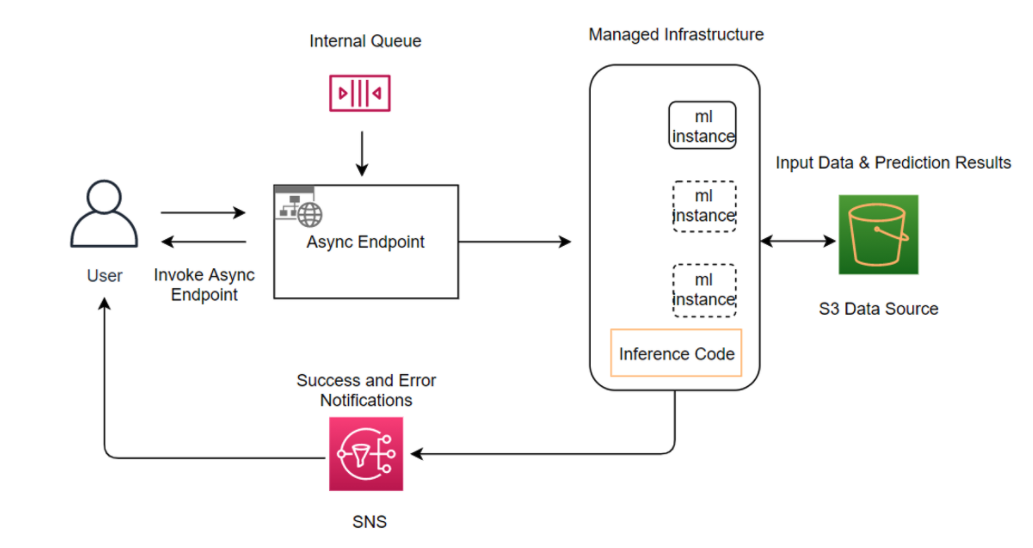
To invoke the endpoint, you need to place the request payload in Amazon S3. You also need
to provide a pointer to this payload as a part of the InvokeEndpointAsync
request. Upon invocation, SageMaker AI queues the request for processing and returns an
identifier and output location as a response. Upon processing, SageMaker AI places the result in
the Amazon S3 location. You can optionally choose to receive success or error notifications
with Amazon SNS. For more information about how to set up asynchronous notifications, see
Check prediction results.
Note
The presence of an asynchronous inference configuration
(AsyncInferenceConfig) object in the endpoint configuration implies
that the endpoint can only receive asynchronous invocations.
How Do I Get Started?
If you are a first-time user of Amazon SageMaker Asynchronous Inference, we recommend that you do the following:
-
Read Asynchronous endpoint operations for information on how to create, invoke, update, and delete an asynchronous endpoint.
-
Explore the Asynchronous Inference example notebook
in the aws/amazon-sagemaker-examples GitHub repository.
Note that if your endpoint uses any of the features listed in this Exclusions page, you cannot use Asynchronous Inference.
