Understand Coordinate Systems and Sensor Fusion
Point cloud data is always located in a coordinate system. This coordinate system may be local to the vehicle or the device sensing the surroundings, or it may be a world coordinate system. When you use Ground Truth 3D point cloud labeling jobs, all the annotations are generated using the coordinate system of your input data. For some labeling job task types and features, you must provide data in a world coordinate system.
In this topic, you'll learn the following:
-
When you are required to provide input data in a world coordinate system or global frame of reference.
-
What a world coordinate is and how you can convert point cloud data to a world coordinate system.
-
How you can use your sensor and camera extrinsic matrices to provide pose data when using sensor fusion.
Coordinate System Requirements for Labeling Jobs
If your point cloud data was collected in a local coordinate system, you can use an extrinsic matrix of the sensor used to collect the data to convert it to a world coordinate system or a global frame of reference. If you cannot obtain an extrinsic for your point cloud data and, as a result, cannot obtain point clouds in a world coordinate system, you can provide point cloud data in a local coordinate system for 3D point cloud object detection and semantic segmentation task types.
For object tracking, you must provide point cloud data in a world coordinate system. This is because when you are tracking objects across multiple frames, the ego vehicle itself is moving in the world and so all of the frames need a point of reference.
If you include camera data for sensor fusion, it is recommended that you provide camera poses in the same world coordinate system as the 3D sensor (such as a LiDAR sensor).
Using Point Cloud Data in a World Coordinate System
This section explains what a world coordinate system (WCS), also referred to as a global frame of reference, is and explains how you can provide point cloud data in a world coordinate system.
What is a World Coordinate System?
A WCS or global frame of reference is a fixed universal coordinate system in which vehicle and sensor coordinate systems are placed. For example, if multiple point cloud frames are located in different coordinate systems because they were collected from two sensors, a WCS can be used to translate all of the coordinates in these point cloud frames into a single coordinate system, where all frames have the same origin, (0,0,0). This transformation is done by translating the origin of each frame to the origin of the WCS using a translation vector, and rotating the three axes (typically x, y, and z) to the right orientation using a rotation matrix. This rigid body transformation is called a homogeneous transformation.
A world coordinate system is important in global path planning, localization,
mapping, and driving scenario simulations. Ground Truth uses the right-handed Cartesian
world coordinate system such as the one defined in ISO 8855
The global frame of reference depends on the data. Some datasets use the LiDAR position in the first frame as the origin. In this scenario, all the frames use the first frame as a reference and device heading and position will be near the origin in the first frame. For example, KITTI datasets have the first frame as a reference for world coordinates. Other datasets use a device position that is different from the origin.
Note that this is not the GPS/IMU coordinate system, which is typically rotated by 90 degrees along the z-axis. If your point cloud data is in a GPS/IMU coordinate system (such as OxTS in the open source AV KITTI dataset), then you need to transform the origin to a world coordinate system (typically the vehicle's reference coordinate system). You apply this transformation by multiplying your data with transformation metrics (the rotation matrix and translation vector). This will transform the data from its original coordinate system to a global reference coordinate system. Learn more about this transformation in the next section.
Convert 3D Point Cloud Data to a WCS
Ground Truth assumes that your point cloud data has already been transformed into a reference coordinate system of your choice. For example, you can choose the reference coordinate system of the sensor (such as LiDAR) as your global reference coordinate system. You can also take point clouds from various sensors and transform them from the sensor's view to the vehicle's reference coordinate system view. You use the a sensor's extrinsic matrix, made up of a rotation matrix and translation vector, to convert your point cloud data to a WCS or global frame of reference.
Collectively, the translation vector and rotation matrix can be used to make up an
extrinsic matrix, which can be used to convert data from a
local coordinate system to a WCS. For example, your LiDAR extrinsic matrix may be
composed as follows, where R is the rotation matrix and T
is the translation vector:
LiDAR_extrinsic = [R T;0 0 0 1]
For example, the autonomous driving KITTI dataset includes a rotation matrix and
translation vector for the LiDAR extrinsic transformation matrix for each frame. The
pykittidataset.oxts[i].T_w_imu gives the LiDAR extrinsic transform for the
ith frame with can be multiplied with
points in that frame to convert them to a world frame -
np.matmul(lidar_transform_matrix, points). Multiplying a point in
LiDAR frame with a LiDAR extrinsic matrix transforms it into world coordinates.
Multiplying a point in the world frame with the camera extrinsic matrix gives the
point coordinates in the camera's frame of reference.
The following code example demonstrates how you can convert point cloud frames from the KITTI dataset into a WCS.
import pykitti import numpy as np basedir = '/Users/nameofuser/kitti-data' date = '2011_09_26' drive = '0079' # The 'frames' argument is optional - default: None, which loads the whole dataset. # Calibration, timestamps, and IMU data are read automatically. # Camera and velodyne data are available via properties that create generators # when accessed, or through getter methods that provide random access. data = pykitti.raw(basedir, date, drive, frames=range(0, 50, 5)) # i is frame number i = 0 # lidar extrinsic for the ith frame lidar_extrinsic_matrix = data.oxts[i].T_w_imu # velodyne raw point cloud in lidar scanners own coordinate system points = data.get_velo(i) # transform points from lidar to global frame using lidar_extrinsic_matrix def generate_transformed_pcd_from_point_cloud(points, lidar_extrinsic_matrix): tps = [] for point in points: transformed_points = np.matmul(lidar_extrinsic_matrix, np.array([point[0], point[1], point[2], 1], dtype=np.float32).reshape(4,1)).tolist() if len(point) > 3 and point[3] is not None: tps.append([transformed_points[0][0], transformed_points[1][0], transformed_points[2][0], point[3]]) return tps # customer transforms points from lidar to global frame using lidar_extrinsic_matrix transformed_pcl = generate_transformed_pcd_from_point_cloud(points, lidar_extrinsic_matrix)
Sensor Fusion
Ground Truth supports sensor fusion of point cloud data with up to 8 video camera inputs. This feature allows human labellers to view the 3D point cloud frame side-by-side with the synchronized video frame. In addition to providing more visual context for labeling, sensor fusion allows workers to adjust annotations in the 3D scene and in 2D images and the adjustment are projected into the other view. The following video demonstrates a 3D point cloud labeling job with LiDAR and camera sensor fusion.
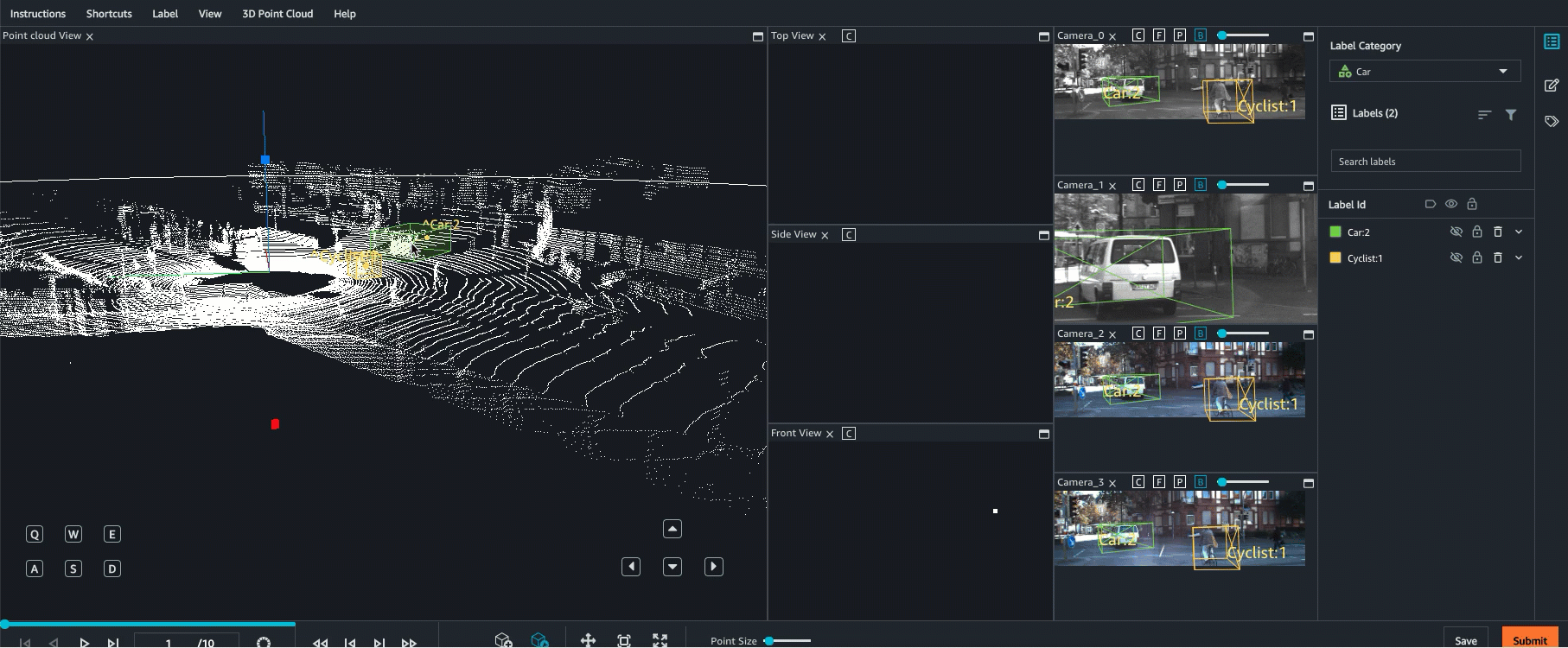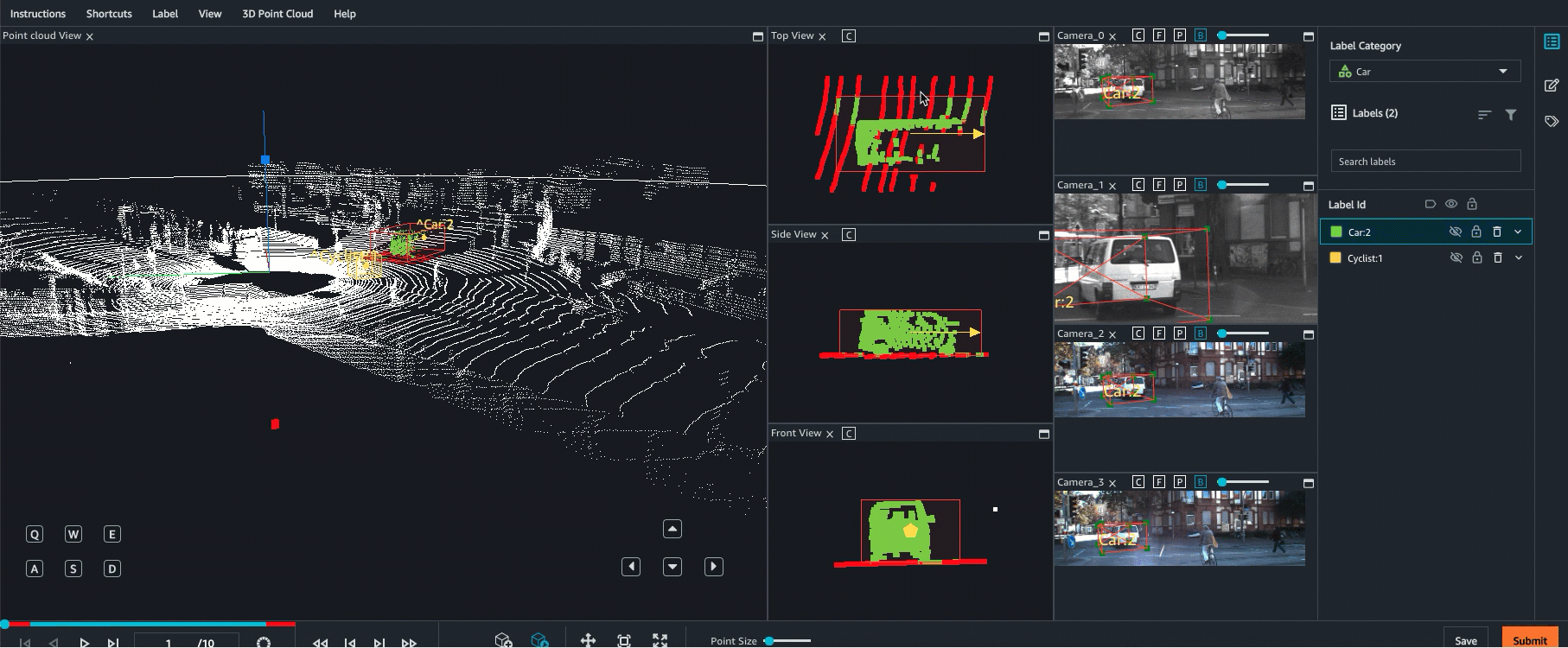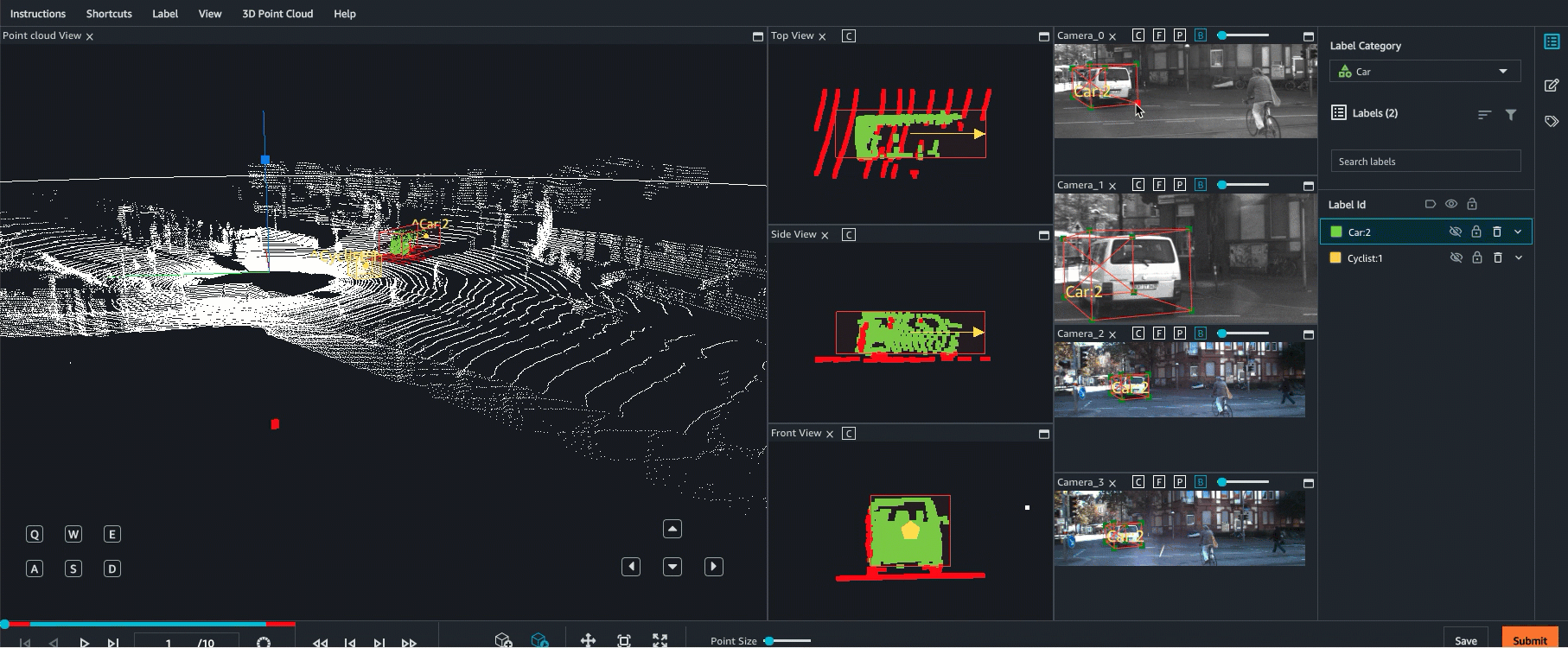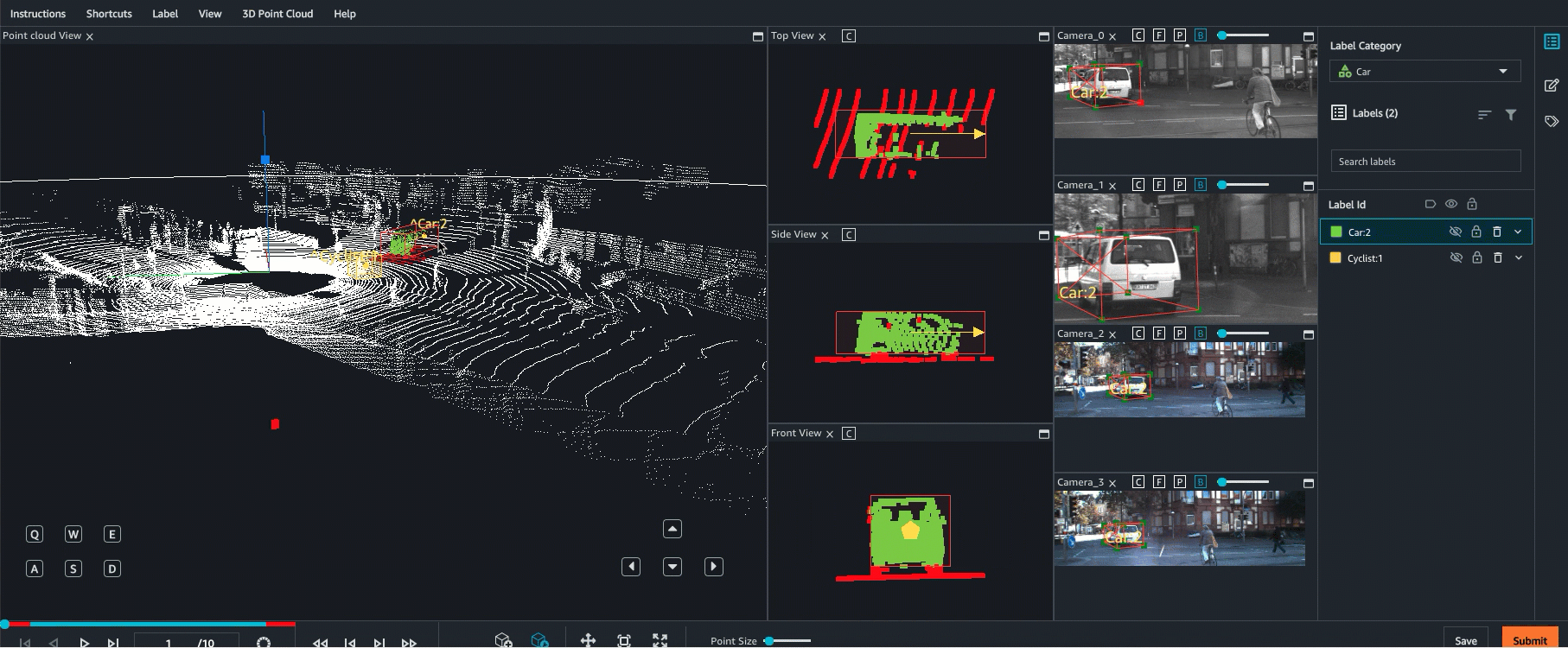
For best results, when using sensor fusion, your point cloud should be in a WCS. Ground Truth uses your sensor (such as LiDAR), camera, and ego vehicle pose information to compute extrinsic and intrinsic matrices for sensor fusion.
Extrinsic Matrix
Ground Truth uses sensor (such as LiDAR) extrinsic and camera extrinsic and intrinsic matrices to project objects to and from the point cloud data's frame of reference to the camera's frame of reference.
For example, in order to project a label from the 3D point cloud to camera image plane, Ground Truth transforms 3D points from LiDAR’s own coordinate system to the camera's coordinate system. This is typically done by first transforming 3D points from LiDAR’s own coordinate system to a world coordinate system (or a global reference frame) using the LiDAR extrinsic matrix. Ground Truth then uses the camera inverse extrinsic (which converts points from a global frame of reference to the camera's frame of reference) to transform the 3D points from world coordinate system obtained in previous step into the camera image plane. The LiDAR extrinsic matrix can also be used to transform 3D data into a world coordinate system. If your 3D data is already transformed into world coordinate system then the first transformation doesn’t have any impact on label translation, and label translation only depends on the camera inverse extrinsic. A view matrix is used to visualize projected labels. To learn more about these transformations and the view matrix, see Ground Truth Sensor Fusion Transformations.
Ground Truth computes these extrinsic matrices by using LiDAR and camera pose
data that you provide: heading ( in quaternions:
qx, qy, qz, and qw) and
position (x, y, z). For the
vehicle, typically the heading and position are described in vehicle's reference
frame in a world coordinate system and are called a ego vehicle
pose. For each camera extrinsic, you can add pose information for
that camera. For more information, see Pose.
Intrinsic Matrix
Ground Truth use the camera extrinsic and intrinsic matrices to compute view metrics to
transform labels to and from the 3D scene to camera images. Ground Truth computes the
camera intrinsic matrix using camera focal length (fx, fy)
and optical center coordinates (cx,cy) that you provide.
For more information, see
Intrinsic and Distortion.
Image Distortion
Image distortion can occur for a variety of reasons. For example, images may be distorted due to barrel or fish-eye effects. Ground Truth uses intrinsic parameters along with distortion co-efficient to undistort images you provide when creating 3D point cloud labeling jobs. If a camera image is already been undistorted, all distortion coefficients should be set to 0.
For more information about the transformations Ground Truth performs to undistort images, see Camera Calibrations: Extrinsic, Intrinsic and Distortion.
Ego Vehicle
To collect data for autonomous driving applications, the measurements used to generate point cloud data and are taken from sensors mounted on a vehicle, or the ego vehicle. To project label adjustments to and from the 3D scene and 2D images, Ground Truth needs your ego vehicle pose in a world coordinate system. The ego vehicle pose is comprised of position coordinates and orientation quaternion.
Ground Truth uses your ego vehicle pose to compute rotation and transformations matrices. Rotations in 3 dimensions can be represented by a sequence of 3 rotations around a sequence of axes. In theory, any three axes spanning the 3D Euclidean space are enough. In practice, the axes of rotation are chosen to be the basis vectors. The three rotations are expected to be in a global frame of reference (extrinsic). Ground Truth does not a support body centered frame of reference (intrinsic) which is attached to, and moves with, the object under rotation. To track objects, Ground Truth needs to measure from a global reference where all vehicles are moving. When using Ground Truth 3D point cloud labeling jobs, z specifies the axis of rotation (extrinsic rotation) and yaw Euler angles are in radians (rotation angle).
Pose
Ground Truth uses pose information for 3D visualizations and sensor fusion. Pose information you input through your manifest file is used to compute extrinsic matrices. If you already have an extrinsic matrix, you can use it to extract sensor and camera pose data.
For example in the autonomous driving KITTI dataset, the pykittidataset.oxts[i].T_w_imu
gives the LiDAR extrinsic transform for the
ith frame and it can be multiplied with
the points to get them in a world frame - matmul(lidar_transform_matrix,
points). This transform can be converted into position (translation
vector) and heading (in quaternion) of LiDAR for the input manifest file JSON
format. Camera extrinsic transform for cam0 in
ith frame can be calculated by
inv(matmul(dataset.calib.T_cam0_velo,
inv(dataset.oxts[i].T_w_imu))) and this can be converted into heading and
position for cam0.
import numpy rotation = [[ 9.96714314e-01, -8.09890350e-02, 1.16333982e-03], [ 8.09967396e-02, 9.96661051e-01, -1.03090934e-02], [-3.24531964e-04, 1.03694477e-02, 9.99946183e-01]] origin= [1.71104606e+00, 5.80000039e-01, 9.43144935e-01] from scipy.spatial.transform import Rotation as R # position is the origin position = origin r = R.from_matrix(np.asarray(rotation)) # heading in WCS using scipy heading = r.as_quat() print(f"pose:{position}\nheading: {heading}")
Position
In the input manifest file, position refers to the position of
the sensor with respect to a world frame. If you are unable to put the device
position in a world coordinate system, you can use LiDAR data with local
coordinates. Similarly, for mounted video cameras you can specify the position
and heading in a world coordinate system. For camera, if you do not have
position information, please use (0, 0, 0).
The following are the fields in the position object:
-
x(float) – x coordinate of ego vehicle, sensor, or camera position in meters. -
y(float) – y coordinate of ego vehicle, sensor, or camera position in meters. -
z(float) – z coordinate of ego vehicle, sensor, or camera position in meters.
The following is an example of a position JSON object:
{ "position": { "y": -152.77584902657554, "x": 311.21505956090624, "z": -10.854137529636024 } }
Heading
In the input manifest file, heading is an object that represents
the orientation of a device with respect to world frame. Heading values should
be in quaternion. A quaternion(qx = 0, qy = 0, qz
= 0, qw = 1). Similarly, for cameras, specify the heading in
quaternions. If you are unable to obtain extrinsic camera calibration
parameters, please also use the identity quaternion.
Fields in heading object are as follows:
-
qx(float) - x component of ego vehicle, sensor, or camera orientation. -
qy(float) - y component of ego vehicle, sensor, or camera orientation. -
qz(float) - z component of ego vehicle, sensor, or camera orientation. -
qw(float) - w component of ego vehicle, sensor, or camera orientation.
The following is an example of a heading JSON object:
{ "heading": { "qy": -0.7046155108831117, "qx": 0.034278837280808494, "qz": 0.7070617895701465, "qw": -0.04904659893885366 } }
To learn more, see Compute Orientation Quaternions and Position.
Compute Orientation Quaternions and Position
Ground Truth requires that all orientation, or heading, data be given in quaternions. A
quaternions
You can compute quaternions from a rotation matrix or a transformation matrix.
If you have a rotation matrix (made up of the axis rotations) and translation vector
(or origin) in world coordinate system instead of a single 4x4 rigid transformation
matrix, then you can directly use the rotation matrix and translation vector to compute
quaternions. Libraries like scipy
import numpy rotation = [[ 9.96714314e-01, -8.09890350e-02, 1.16333982e-03], [ 8.09967396e-02, 9.96661051e-01, -1.03090934e-02], [-3.24531964e-04, 1.03694477e-02, 9.99946183e-01]] origin = [1.71104606e+00, 5.80000039e-01, 9.43144935e-01] from scipy.spatial.transform import Rotation as R # position is the origin position = origin r = R.from_matrix(np.asarray(rotation)) # heading in WCS using scipy heading = r.as_quat() print(f"position:{position}\nheading: {heading}")
A UI tool like 3D
Rotation Converter
If you have a 4x4 extrinsic transformation matrix, note that the transformation matrix
is in the form [R T; 0 0 0 1] where R is the rotation
matrix and T is the origin translation vector. That means you can
extract rotation matrix and translation vector from the transformation matrix as
follows.
import numpy as np transformation = [[ 9.96714314e-01, -8.09890350e-02, 1.16333982e-03, 1.71104606e+00], [ 8.09967396e-02, 9.96661051e-01, -1.03090934e-02, 5.80000039e-01], [-3.24531964e-04, 1.03694477e-02, 9.99946183e-01, 9.43144935e-01], [ 0, 0, 0, 1]] transformation = np.array(transformation ) rotation = transformation[0:3,0:3] translation= transformation[0:3,3] from scipy.spatial.transform import Rotation as R # position is the origin translation position = translation r = R.from_matrix(np.asarray(rotation)) # heading in WCS using scipy heading = r.as_quat() print(f"position:{position}\nheading: {heading}")
With your own setup, you can compute an extrinsic transformation matrix using the
GPS/IMU position and orientation (latitude, longitude, altitude and roll, pitch, yaw)
with respect to the LiDAR sensor on the ego vehicle. For example, you can compute pose
from KITTI raw data using pose = convertOxtsToPose(oxts) to transform the
oxts data into a local euclidean poses, specified by 4x4 rigid transformation matrices.
You can then transform this pose transformation matrix to a global reference frame using
the reference frames transformation matrix in the world coordinate system.
struct Quaternion { double w, x, y, z; }; Quaternion ToQuaternion(double yaw, double pitch, double roll) // yaw (Z), pitch (Y), roll (X) { // Abbreviations for the various angular functions double cy = cos(yaw * 0.5); double sy = sin(yaw * 0.5); double cp = cos(pitch * 0.5); double sp = sin(pitch * 0.5); double cr = cos(roll * 0.5); double sr = sin(roll * 0.5); Quaternion q; q.w = cr * cp * cy + sr * sp * sy; q.x = sr * cp * cy - cr * sp * sy; q.y = cr * sp * cy + sr * cp * sy; q.z = cr * cp * sy - sr * sp * cy; return q; }
Ground Truth Sensor Fusion Transformations
The following sections go into greater detail about the Ground Truth sensor fusion transformations that are performed using the pose data you provide.
LiDAR Extrinsic
In order to project to and from a 3D LiDAR scene to a 2D camera image, Ground Truth computes the rigid transformation projection metrics using the ego vehicle pose and heading. Ground Truth computes rotation and translation of a world coordinates into the 3D plane by doing a simple sequence of rotations and translation.
Ground Truth computes rotation metrics using the heading quaternions as follows:

Here, [x, y, z, w] corresponds to parameters in the
heading JSON object, [qx, qy, qz, qw]. Ground Truth computes
the translation column vector as T = [poseX, poseY, poseZ]. Then the
extrinsic metrics is simply as follows:
LiDAR_extrinsic = [R T;0 0 0 1]
Camera Calibrations: Extrinsic, Intrinsic and Distortion
Geometric camera calibration, also referred to as camera resectioning, estimates the parameters of a lens and image sensor of an image or video camera. You can use these parameters to correct for lens distortion, measure the size of an object in world units, or determine the location of the camera in the scene. Camera parameters include intrinsics and distortion coefficients.
Camera Extrinsic
If the camera pose is given, then Ground Truth computes the camera extrinsic based on
a rigid transformation from the 3D plane into the camera plane. The calculation
is the same as the one used for the LiDAR
Extrinsic, except that
Ground Truth uses camera pose (position and heading) and
computes the inverse extrinsic.
camera_inverse_extrinsic = inv([Rc Tc;0 0 0 1]) #where Rc and Tc are camera pose components
Intrinsic and Distortion
Some cameras, such as pinhole or fisheye cameras, may introduce significant
distortion in photos. This distortion can be corrected using distortion
coefficients and the camera focal length. To learn more, see Camera calibration With OpenCV
There are two types of distortion Ground Truth can correct for: radial distortion and tangential distortion.
Radial distortion occurs when light rays bend more near the edges of a lens than they do at its optical center. The smaller the lens, the greater the distortion. The presence of the radial distortion manifests in form of the barrel or fish-eye effect and Ground Truth uses Formula 1 to undistort it.
Formula 1:

Tangential distortion occurs because the lenses used to take the images are not perfectly parallel to the imaging plane. This can be corrected with Formula 2.
Formula 2:

In the input manifest file, you can provide distortion coefficients and Ground Truth will undistort your images. All distortion coefficients are floats.
-
k1,k2,k3,k4– Radial distortion coefficients. Supported for both fisheye and pinhole camera models. -
p1,p2– Tangential distortion coefficients. Supported for pinhole camera models.
If images are already undistorted, all distortion coefficients should be 0 in your input manifest.
In order to correctly reconstruct the corrected image, Ground Truth does a unit conversion of the images based on focal lengths. If a common focal length is used with a given aspect ratio for both axes, such as 1, in the upper formula we will have a single focal length. The matrix containing these four parameters is referred to as the in camera intrinsic calibration matrix.

While the distortion coefficients are the same regardless of the camera resolutions used, these should be scaled with the current resolution from the calibrated resolution.
The following are float values.
-
fx- focal length in x direction. -
fy- focal length in y direction. -
cx- x coordinate of principal point. -
cy- y coordinate of principal point.
Ground Truth use the camera extrinsic and camera intrinsic to compute view metrics as shown in the following code block to transform labels between the 3D scene and 2D images.
def generate_view_matrix(intrinsic_matrix, extrinsic_matrix): intrinsic_matrix = np.c_[intrinsic_matrix, np.zeros(3)] view_matrix = np.matmul(intrinsic_matrix, extrinsic_matrix) view_matrix = np.insert(view_matrix, 2, np.array((0, 0, 0, 1)), 0) return view_matrix
