Best practices and recommendations for SQL Server clustering on Amazon EC2
You can configure Microsoft SQL Server on Amazon EC2 instances for high availability. SQL Server Always On availability
groups offer high availability without the requirement for shared storage. The list of best
practices in this topic, in addition to the prerequisites listed at Prerequisites,
Restrictions, and Recommendations for Always On availability groups
Note
When nodes are deployed in different Availability Zones, or in different subnets within the same Availability Zone, they should be treated as a multi-subnet cluster. Keep this in mind as you apply these best practices and when you address possible failure scenarios.
Assign IP addresses
Each cluster node should have one elastic network interface assigned that includes three private IP addresses on the subnet: a primary IP address, a cluster IP address, and an Availability Group IP address. The operating system (OS) should have the NIC configured for DHCP. It should not be set for a static IP address because the IP addresses for the cluster IP and Availability Group will be handled virtually in the Failover Cluster Manager. The NIC can be configured for a static IP as long as it is configured to only use the primary IP of eth0. If the other IPs are assigned to the NIC, it can cause network drops for the instance during failover events.
When the network drops because the IPs are incorrectly assigned, or when there is a failover event or network failure, it is not uncommon to see the following event log entries at the time of failure.
Isatap interface isatap.{9468661C-0AEB-41BD-BB8C-1F85981D5482} is no longer active.
Isatap interface isatap.{9468661C-0AEB-41BD-BB8C-1F85981D5482} with address fe80::5efe:169.254.1.105 has been brought up.
Because these messages seem to describe network issues, you could potentially mistake the cause of the outage or failure as a network error. However, these errors describe a symptom, rather than cause, of the failure. ISATAP is a tunneling technology that uses IPv6 over IPv4. When the IPv4 connection fails, the ISATAP adapter also fails. When the network issues are resolved, these entries should no longer appear in the event logs. Alternately, you can reduce network errors by safely disabling ISATAP with the following command.
netsh int ipv6 isatap set state disabled
When you run this command, the adapter is removed from Device Manager. This command should be run on all nodes. It does not impact the ability of the cluster to function. Instead, when the command has been run, ISATAP is no longer used. However, because this command might cause unknown impacts on other applications that use ISATAP, you should test it.
Cluster properties
To see the complete cluster configuration, run the following PowerShell command.
Get-Cluster | Format-List -Property *
Cluster quorum votes and 50/50 splits in a multi-site cluster
To learn how the cluster quorum works and what to expect if a failure occurs, see
Understanding Cluster and Pool Quorum
DNS registration
In Windows Server 2012, Failover Clustering, by default, attempts to register each DNS
node under the cluster name. This is acceptable for applications that are aware the SQL
target is configured for multi-site. However, when the client is not configured this
way, it can result in timeouts, delays, and application errors due to attempts to
connect to each individual node and failing on the inactive ones. To prevent these
problems, the Cluster Resource parameter RegisterAllProvidersIp must be changed to 0. For more information, see RegisterAllProvidersIP Setting
The RegisterAllProvidersIp can be modified with the
following PowerShell script.
Import-Module FailoverClusters $cluster = (Get-ClusterResource | where {($_.ResourceType -eq "Network Name") -and ($_.OwnerGroup -ne "Cluster Group")}).Name Get-ClusterResource $cluster | Set-ClusterParameter RegisterAllProvidersIP 0 Get-ClusterResource $cluster |Set-ClusterParameter HostRecordTTL 300 Stop-ClusterResource $cluster Start-ClusterResource $cluster
In addition to setting the Cluster Resource parameter to 0, you must ensure that the cluster has permissions to modify the DNS entry for your cluster name.
-
Log in to the Domain Controller (DC) for the domain, or a server that hosts the forward lookup zone for the domain.
-
Launch the DNS Management Console and locate the
Arecord for the cluster. -
Choose or right-click the
Arecord, and choose Properties. -
Choose Security.
-
Choose Add.
-
Choose Object Types..., select the box for Computers, and choose OK.
-
Enter the name of the cluster resource object and choose Check name and OK if resolve.
-
Select the check box for Full Control.
-
Choose OK.
Elastic Network Adapters (ENAs)
AWS has identified known issues with some clustering workloads running on ENA driver version 1.2.3. We recommend upgrading to the latest version, and adjusting settings on the NIC in the operating system. For the latest versions, see Amazon ENA Driver Versions. The first setting, which applies to all systems, increases Receive Buffers, which you can do with the following example PowerShell command.
Set-NetAdapterAdvancedProperty -Name (Get-NetAdapter | Where-Object {$_.InterfaceDescription -like '*Elastic*'}).Name -DisplayName "Receive Buffers" -DisplayValue 8192
For instances with more than 16 vCPUs, we recommend preventing RSS from running on CPU 0.
Run the following command.
Set-NetAdapterRss -name (Get-NetAdapter | Where-Object {$_.InterfaceDescription -like '*Elastic*'}).Name -Baseprocessorgroup 0 -BaseProcessorNumber 1
Multi-site clusters and EC2 instance placement
Each cluster is considered a multi-site cluster
Instance type selection
The type of instance recommended for Windows Server Failover Clustering depends on the workload. For production workloads, we recommend instances that support Amazon Elastic Block Store (Amazon EBS) optimization and enhanced networking. For more information, see EBS optimization and Enhanced networking in the Amazon EC2 User Guide.
Assign elastic network interfaces and IPs to the instance
Each node in an EC2 cluster should have only one attached elastic network interface. The network interface should have a minimum of two assigned private IP addresses. However, for workloads that use Availability Groups, such as SQL Always On, you must include an additional IP address for each Availability Group. The primary IP address is used for accessing and managing the server, the secondary IP address is used as the cluster IP address, and each additional IP address is assigned to Availability Groups, as needed.
Heartbeat network
Some Microsoft documentation recommends using a dedicated heartbeat network
Configure the network adapter in the OS
The NIC in the OS can keep using DHCP as long as the DNS servers that are being retrieved from the DHCP Options Set allow for the nodes to resolve each other. You can set the NIC to be configured statically. When completed, you then manually configure only the primary IP address for the elastic network interface. Failover Clustering manages and assigns additional IP addresses, as needed.
For certain instance types, you can increase the maximum transmission unit (MTU) on the network adapter to support Jumbo Frames. This configuration reduces fragmentation of packets wherever Jumbo Frames are supported. For more information, see Network maximum transmission unit (MTU) for your EC2 instance in the Amazon Elastic Compute Cloud User Guide.
IPv6
Microsoft does not recommend disabling IPv6 in a Windows Cluster. While Failover
Clustering works in an IPv4-only environment, Microsoft tests clusters with IPv6
enabled. See Failover Clustering and IPv6 in Windows Server 2012 R2
Host record TTL for SQL Availability Group Listeners
Set the host record TTL to 300 seconds instead of
the default 20 minutes (1200 seconds). For legacy client comparability, set
RegisterAllProvidersIP to 0 for SQL
Availability Group Listeners. This is not required in all environments. These settings
are important because some legacy client applications cannot use
MultiSubnetFailover in their connection strings. See HostRecordTTL SettingRESOLVING state.
The following are example PowerShell scripts for changing the TTL and
RegisterAllProvidersIP settings.
Get-ClusterResourceyourListenerName| Set-ClusterParameter RegisterAllProvidersIP 0
Get-ClusterResourceyourListenerName|Set-ClusterParameter HostRecordTTL 300
Stop-ClusterResourceyourListenerName
Start-ClusterResourceyourListenerName
Start-ClusterGroupyourListenerGroupName
Logging
The default logging level for the cluster log is 3.
To increase the detail of log information, set the logging level to 5. See Set-ClusterLog
Set-ClusterLog -Level 5
NetBIOS over TCP
In Windows Server 2012 R2, you can increase the speed of the failover process by
disabling NetBIOS over TCP. This feature was removed from Windows Server 2016. You
should test this procedure if you are using earlier operating systems in your
environment. For more information, see Speeding Up Failover Tips-n-Tricks
Get-ClusterResource“Cluster IP Address”| Set-ClusterParameter EnableNetBIOS 0
NetFT Virtual Adapter
For Windows Server versions earlier than 2016 and non-Hyper-V workloads, Microsoft
recommends you enable the NetFT Virtual Adapter Performance Filter on the adapter in the
OS. When you enable the NetFT Virtual Adapter, internal cluster traffic is routed
directly to the NetFT Virtual Adapter. For more information, see NetFT Virtual Adapter Performance Filter
Get-NetAdapter | Set-NetAdapterBinding -ComponentID ms_netftflt -Enable $true
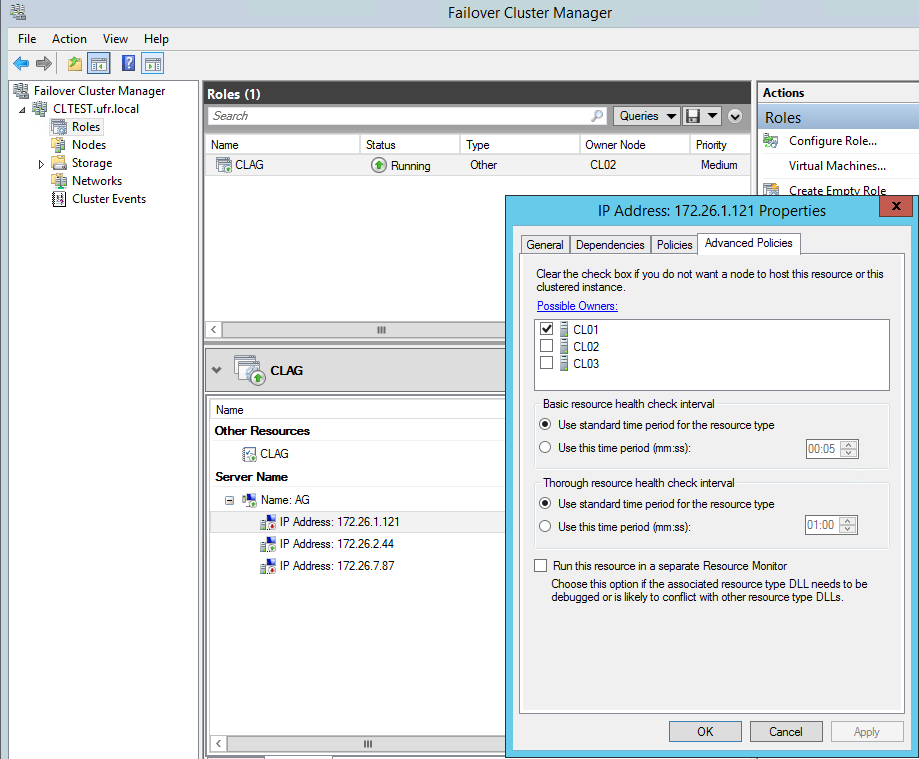
Set possible owners
The Failover Cluster Manager can be configured so that each IP address specified
on the Cluster Core Resources and Availability Group resources can be brought online
only on the node to which the IP belongs. When the Failover Cluster Manager is not
configured for this and a failure occurs, there will be some delay in failover as the
cluster attempts to bring up the IPs on nodes that do not recognize the address. For
more information, see SQL Server Manages Preferred and Possible Owner Properties for AlwaysOn
Availability Group/Role
Each resource in a cluster has a setting for Possible Owners. This setting tells the cluster which nodes are permitted to “online” a resource. Each node is running on a unique subnet in a VPC. Because EC2 cannot share IPs between instances, the IP resources in the cluster can be brought online only by specific nodes. By default, each IP address that is added to the cluster as a resource has every node listed as a Possible Owner. This does not result in failures. However, during expected and unexpected failures, you can see errors in the logs about conflicting IPs and failures to bring IPs online. These errors can be ignored. If you set the Possible Owner property, you can eliminate these errors entirely, and also prevent down time while the services are moved to another node.
The following image shows an example of configuring an IP address so that it can only be brought online on the node to which the IP belongs:
Tune the failover thresholds
In Windows Server 2012 R2, the network thresholds for the failover heartbeat
network default to high values. See Tuning Failover Cluster Network Thresholds
The only time a cluster should fail over is when there is a legitimate outage,
such as a service or node that experiences a hard failover, as opposed to a few UDP
packets lost in transit. To ensure legitimate outages, we recommend that you adjust the
thresholds to match, or even exceed, the settings for Server 2016 listed in Tuning Failover Cluster Network Thresholds
(get-cluster).SameSubnetThreshold = 10
(get-cluster).CrossSubnetThreshold = 20
When you set these values, unexpected failovers should be dramatically reduced. You can fine tune these settings by increasing the delays between heartbeats. However, we recommend that you send the heartbeats more frequently with greater thresholds. Setting these thresholds even higher ensures that failovers occur only for hard failover scenarios, with longer delays before failing over. You must decide how much down time is acceptable for your applications.
After increasing the SameSubnetThreshold or
CrossSubnetThreshold, we recommend that you increase the
RouteHistoryLength to double the higher of the two values. This ensures
that there is sufficient logging for troubleshooting. You can set the
RouteHistoryLength with the following PowerShell command.
(Get-Cluster).RouteHistoryLength = 20
Witness importance and Dynamic Quorum Architecture
There is a difference between Disk Witness and File Share Witness. Disk Witness
keeps a backup of the cluster database while File Share Witness does not. Both add a
vote to the cluster. You can use Disk
Witness if you use iSCSI-based storage. For more about witness options, see File Share witness vs Disk witness for local clusters
Troubleshoot
If you experience unexpected failovers, first make sure that you are not experiencing networking, service, or infrastructure issues.
-
Check that your nodes are not experiencing network-related issues.
-
Check driver updates. If you are using outdated drivers on your instance, you should update them. Updating your drivers might address bugs and stability issues that might be present in your currently installed version.
-
Check for any possible resource bottlenecks that could cause an instance to become unresponsive, such as CPU and disk I/O. If the node cannot service requests, it might appear to be down by the cluster service.
