Transcribing multi-channel audio
If your audio has two channels, you can use channel identification to transcribe the speech from each channel separately. Amazon Transcribe doesn't currently support audio with more than two channels.
In your transcript, channels are assigned the labels ch_0 and
ch_1.
In addition to the standard transcript sections
(transcripts and items), requests with channel identification
enabled include a channel_labels section. This section contains each utterance or
punctuation mark, grouped by channel, and its associated channel label, timestamps, and confidence
score.
"channel_labels": { "channels": [ { "channel_label": "ch_0", "items": [ { "channel_label": "ch_0", "start_time": "4.86", "end_time": "5.01", "alternatives": [ { "confidence": "1.0", "content": "I've" } ], "type": "pronunciation" },..."channel_label": "ch_1", "items": [ { "channel_label": "ch_1", "start_time": "8.5", "end_time": "8.89", "alternatives": [ { "confidence": "1.0", "content": "Sorry" } ], "type": "pronunciation" },..."number_of_channels": 2 },
Note that if a person on one channel speaks at the same time as a person on a separate channel, timestamps for each channel overlap while the individuals are speaking over each other.
To view a complete example transcript with channel identification, see Example channel identification output (batch).
Using channel identification in a batch transcription
To identify channels in a batch transcription, you can use the AWS Management Console, AWS CLI, or AWS SDKs; see the following for examples:
-
Sign in to the AWS Management Console
. -
In the navigation pane, choose Transcription jobs, then select Create job (top right). This opens the Specify job details page.

-
Fill in any fields you want to include on the Specify job details page, then select Next. This takes you to the Configure job - optional page.
In the Audio settings panel, select Channel identification (under the 'Audio identification type' heading).
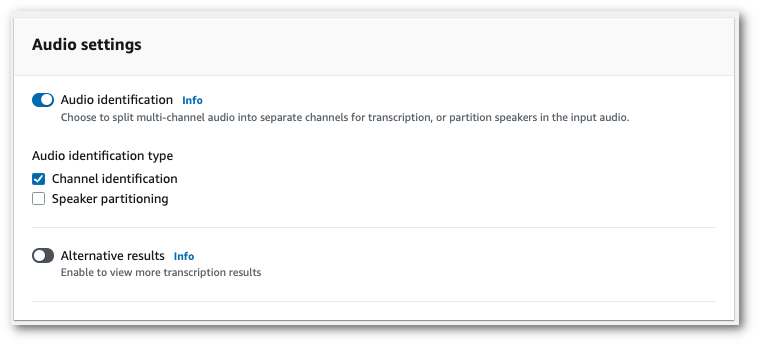
-
Select Create job to run your transcription job.
This example uses the start-transcription-jobStartTranscriptionJob.
aws transcribe start-transcription-job \ --regionus-west-2\ --transcription-job-namemy-first-transcription-job\ --media MediaFileUri=s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac\ --output-bucket-nameamzn-s3-demo-bucket\ --output-keymy-output-files/ \ --language-codeen-US\ --settings ChannelIdentification=true
Here's another example using the start-transcription-job
aws transcribe start-transcription-job \ --regionus-west-2\ --cli-input-json file://my-first-transcription-job.json
The file my-first-transcription-job.json contains the following request body.
{ "TranscriptionJobName": "my-first-transcription-job", "Media": { "MediaFileUri": "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" }, "OutputBucketName": "amzn-s3-demo-bucket", "OutputKey": "my-output-files/", "LanguageCode": "en-US", "Settings": { "ChannelIdentification": true } }
This example uses the AWS SDK for Python (Boto3) to identify channels using the
start_transcription_job
from __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe', 'us-west-2') job_name = "my-first-transcription-job" job_uri = "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" transcribe.start_transcription_job( TranscriptionJobName = job_name, Media = { 'MediaFileUri': job_uri }, OutputBucketName = 'amzn-s3-demo-bucket', OutputKey = 'my-output-files/', LanguageCode = 'en-US', Settings = { 'ChannelIdentification':True } ) while True: status = transcribe.get_transcription_job(TranscriptionJobName = job_name) if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']: break print("Not ready yet...") time.sleep(5) print(status)
Using channel identification in a streaming transcription
To identify channels in a streaming transcription, you can use HTTP/2 or WebSockets; see the following for examples:
This example creates an HTTP/2 request that separates channels in your transcription output. For more information on using HTTP/2 streaming with Amazon Transcribe, see Setting up an HTTP/2 stream. For more detail on parameters and headers specific to Amazon Transcribe, see StartStreamTranscription.
POST /stream-transcription HTTP/2 host: transcribestreaming.us-west-2.amazonaws.com X-Amz-Target: com.amazonaws.transcribe.Transcribe.StartStreamTranscriptionContent-Type: application/vnd.amazon.eventstream X-Amz-Content-Sha256:stringX-Amz-Date:20220208T235959Z Authorization: AWS4-HMAC-SHA256 Credential=access-key/20220208/us-west-2/transcribe/aws4_request, SignedHeaders=content-type;host;x-amz-content-sha256;x-amz-date;x-amz-target;x-amz-security-token, Signature=stringx-amzn-transcribe-language-code:en-USx-amzn-transcribe-media-encoding:flacx-amzn-transcribe-sample-rate:16000x-amzn-channel-identification: TRUE transfer-encoding: chunked
Parameter definitions can be found in the API Reference; parameters common to all AWS API operations are listed in the Common Parameters section.
This example creates a presigned URL that separates channels in your transcription output.
Line breaks have been added for readability. For more information
on using WebSocket streams with Amazon Transcribe, see
Setting up a WebSocket stream.
For more detail on parameters, see
StartStreamTranscription.
GET wss://transcribestreaming.us-west-2.amazonaws.com:8443/stream-transcription-websocket? &X-Amz-Algorithm=AWS4-HMAC-SHA256 &X-Amz-Credential=AKIAIOSFODNN7EXAMPLE%2F20220208%2Fus-west-2%2Ftranscribe%2Faws4_request &X-Amz-Date=20220208T235959Z &X-Amz-Expires=300&X-Amz-Security-Token=security-token&X-Amz-Signature=string&X-Amz-SignedHeaders=content-type%3Bhost%3Bx-amz-date &language-code=en-US &specialty=PRIMARYCARE&type=DICTATION&media-encoding=flac&sample-rate=16000&channel-identification=TRUE
Parameter definitions can be found in the API Reference; parameters common to all AWS API operations are listed in the Common Parameters section.
