Starting a post-call analytics transcription
Before starting a post-call analytics transcription, you must create all the categories you want Amazon Transcribe to match in your audio.
Note
Call Analytics transcripts can't be retroactively matched to new categories. Only the categories you create before starting a Call Analytics transcription can be applied to that transcription output.
If you've created one or more categories, and your audio matches all the rules within at least one of your categories, Amazon Transcribe flags your output with the matching category. If you choose not to use categories, or if your audio doesn't match the rules specified in your categories, your transcript isn't flagged.
To start a post-call analytics transcription, you can use the AWS Management Console, AWS CLI, or AWS SDKs; see the following for examples:
Use the following procedure to start a post-call analytics job. The calls that match all characteristics defined by a category are labeled with that category.
-
In the navigation pane, under Amazon Transcribe Call Analytics, choose Call analytics jobs.
-
Choose Create job.
-
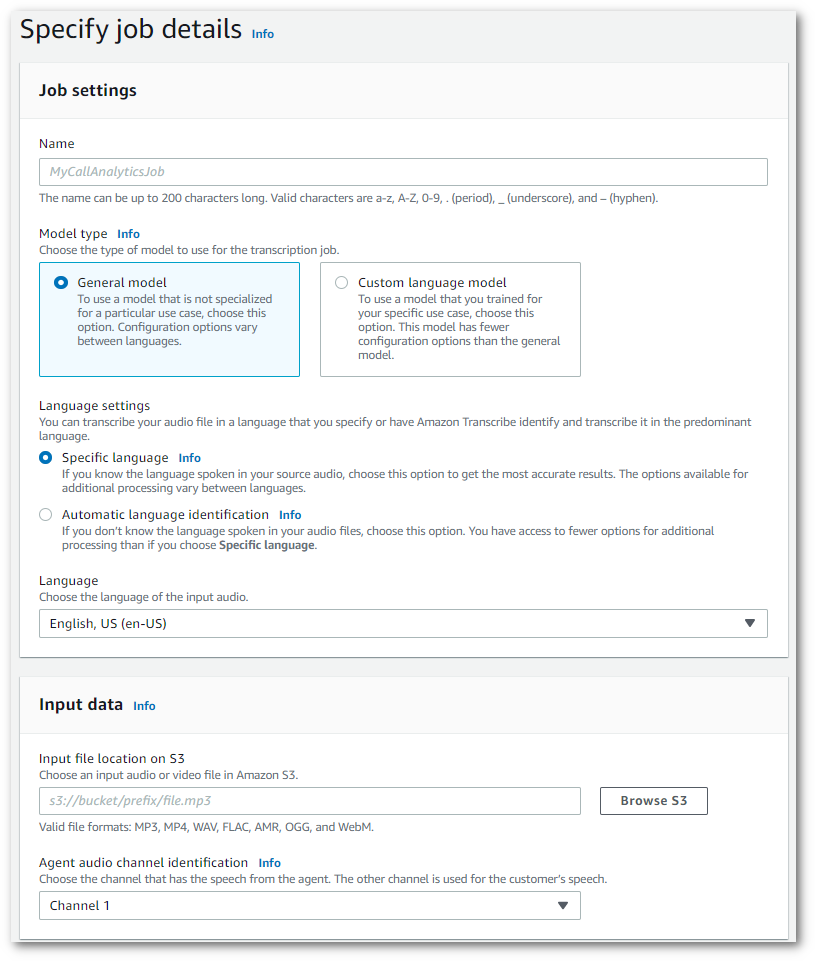
On the Specify job details page, provide information about your Call Analytics job, including the location of your input data.
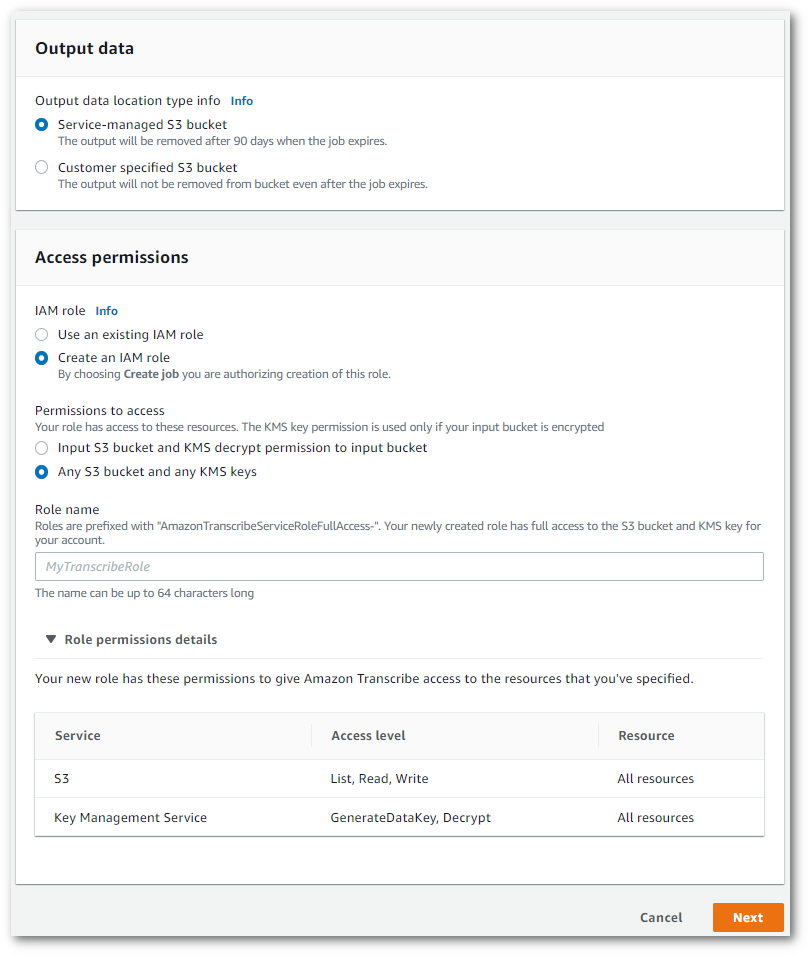
Specify the desired Amazon S3 location of your output data and which IAM role to use.
-
Choose Next.
-
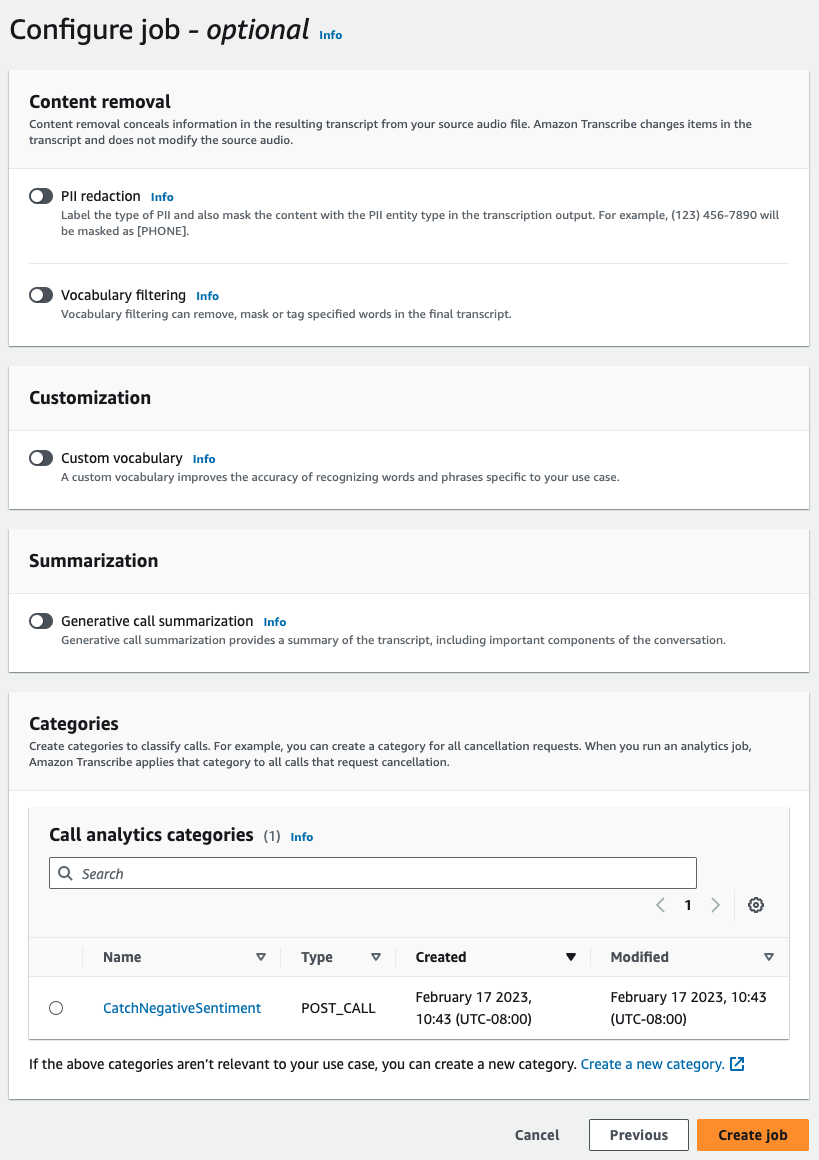
For Configure job, turn on any optional features you want to include with your Call Analytics job. If you previously created categories, they appear in the Categories panel and are automatically applied to your Call Analytics job.

-
Choose Create job.
This example uses the
start-call-analytics-jobchannel-definitions parameter. For more information, see
StartCallAnalyticsJob
and ChannelDefinition.
aws transcribe start-call-analytics-job \ --regionus-west-2\ --call-analytics-job-namemy-first-call-analytics-job\ --media MediaFileUri=s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac\ --output-location s3://amzn-s3-demo-bucket/my-output-files/ \ --data-access-role-arn arn:aws:iam::111122223333:role/ExampleRole\ --channel-definitions ChannelId=0,ParticipantRole=AGENTChannelId=1,ParticipantRole=CUSTOMER
Here's another example using the
start-call-analytics-job
aws transcribe start-call-analytics-job \ --regionus-west-2\ --cli-input-json file://filepath/my-call-analytics-job.json
The file my-call-analytics-job.json contains the following request body.
{ "CallAnalyticsJobName": "my-first-call-analytics-job", "DataAccessRoleArn": "arn:aws:iam::111122223333:role/ExampleRole", "Media": { "MediaFileUri": "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" }, "OutputLocation": "s3://amzn-s3-demo-bucket/my-output-files/", "ChannelDefinitions": [ { "ChannelId": 0, "ParticipantRole": "AGENT" }, { "ChannelId": 1, "ParticipantRole": "CUSTOMER" } ] }
This example uses the AWS SDK for Python (Boto3) to start a Call Analytics job using the
start_call_analytics_jobStartCallAnalyticsJob and
ChannelDefinition.
For additional examples using the AWS SDKs, including feature-specific, scenario, and cross-service examples, refer to the Code examples for Amazon Transcribe using AWS SDKs chapter.
from __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe', 'us-west-2') job_name = "my-first-call-analytics-job" job_uri = "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" output_location = "s3://amzn-s3-demo-bucket/my-output-files/" data_access_role = "arn:aws:iam::111122223333:role/ExampleRole" transcribe.start_call_analytics_job( CallAnalyticsJobName = job_name, Media = { 'MediaFileUri': job_uri }, DataAccessRoleArn = data_access_role, OutputLocation = output_location, ChannelDefinitions = [ { 'ChannelId': 0, 'ParticipantRole': 'AGENT' }, { 'ChannelId': 1, 'ParticipantRole': 'CUSTOMER' } ] ) while True: status = transcribe.get_call_analytics_job(CallAnalyticsJobName = job_name) if status['CallAnalyticsJob']['CallAnalyticsJobStatus'] in ['COMPLETED', 'FAILED']: break print("Not ready yet...") time.sleep(5) print(status)
