Data lake lifecycle
Building a data lake typically involves five stages:
-
Setting up storage
-
Moving data
-
Preparing and cataloging data
-
Configuring security policies
-
Making data available for consumption
The following figure is a high-level architecture diagram of an Amazon Connect contact center data lake that integrates with AWS analytics and artificial intelligence / machine learning (AI / ML) services. The following section covers the scenarios and AWS services shown in this figure.
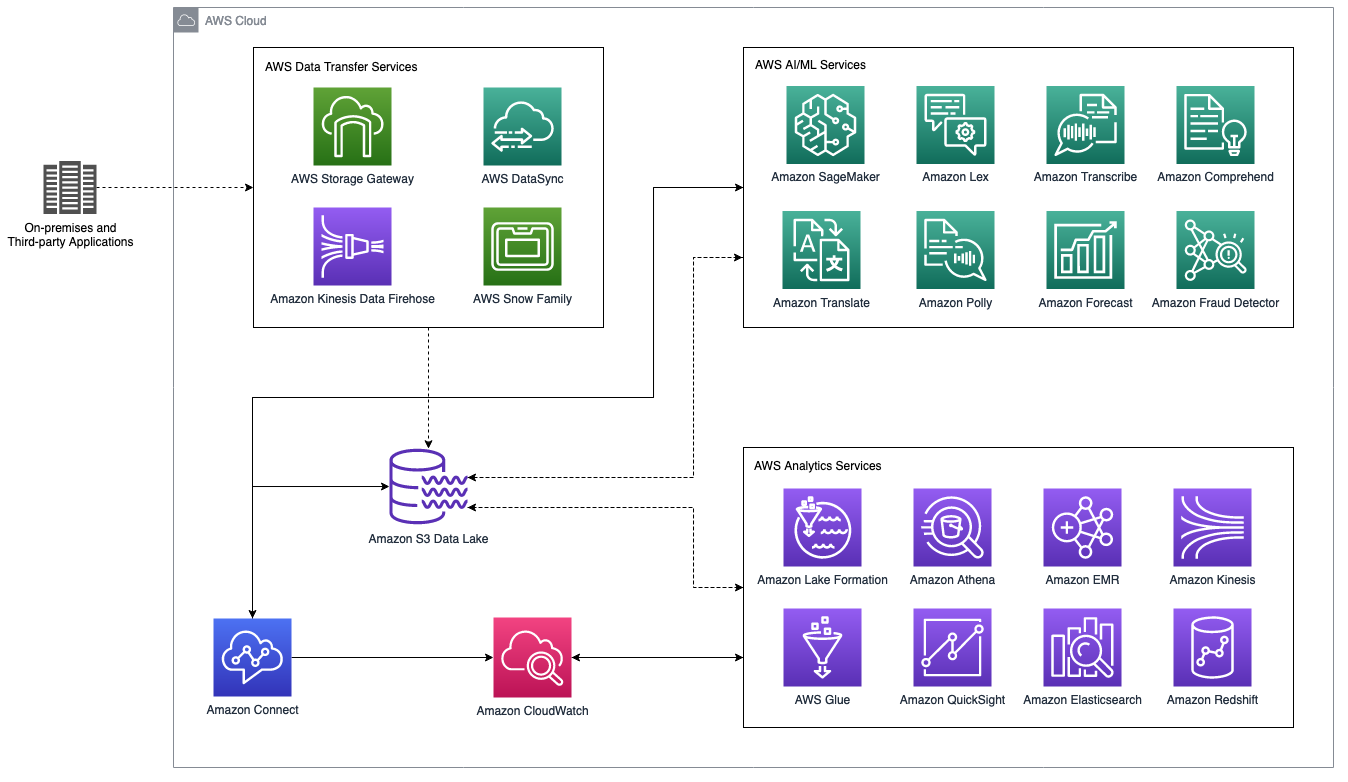
Amazon Connect contact center data lake with AWS analytics and AI / ML services
Storage
Amazon S3
S3 buckets and objects are private with
S3
Block Public Access enabled by default to all Regions
globally. You can set up centralized access controls on S3
resources using
bucket
policies,
AWS Identity and Access Management
AWS CloudTrail
S3
Intelligent-Tiering
Storing data in columnar formats such as
Apache
Parquet
With S3 Select and S3 Glacier Select, you can query object metadata using structured query language (SQL) expression without moving the objects to another data store.
S3
Batch Operations
S3
Access Points
S3
Transfer Acceleration
As your data lake grows, S3
Storage Lens
Ingestion
AWS provides a comprehensive data transfer services portfolio to move your existing data
into a centralized data lake. Amazon Storage
Gateway
-
AWS Storage Gateway extends your on-premises environments to AWS storage by replacing tape libraries with cloud storage, providing cloud storage-backed file shares, or creating a low-latency cache to access your data in AWS from on-premises environments.
-
AWS Direct Connect establishes private connectivity between your on-premises environments and AWS to reduce network costs, increase throughput, and provide a consistent network experience.
-
AWS DataSync can transfer millions of files into S3, Amazon Elastic File System
(Amazon EFS), or Amazon FSx for Windows File Server while optimizing network utilization. -
Amazon Kinesis provides a secure way to capture and load streaming data into S3. Amazon Data Firehose
is a fully managed service for delivering real-time streaming data directly to S3. Firehose automatically scales to match the volume and throughput of streaming data and requires no ongoing administration. You can transform streaming data using compression, encryption, data batching, or AWS Lambda functions within Firehose before storing data in S3. Firehose encryption supports S3 server-side encryption with AWS Key Management Service (AWS KMS). Alternatively, you can encrypt the data with your custom key. Firehose can concatenate and deliver multiple incoming records as a single S3 object to reduce costs and optimize throughput. AWS Snow Family provides an offline data transfer mechanism. AWS Snowball
delivers a portable and ruggedized edge computing device for data collection, processing, and migration. For exabyte-scale data transfer, you can use AWS Snowmobile to move massive data volumes to the cloud. DistCp
provides a distributed copy capability to move data in the Hadoop ecosystem. S3DisctCp is an extension to DistCp optimized for moving data between Hadoop Distributed File System (HDFS) and S3. This blog provides information on how to move data between HDFS and S3 using S3DistCp.
Cataloging
One common challenge with a data lake architecture is the lack of oversight on the contents of raw data stored in the data lake. Organizations need governance, semantic consistency, and access controls to avoid the pitfalls of creating a data swamp with no curation.
AWS Lake Formation
AWS Glue DataBrew
Security
Amazon Connect segregates data by AWS account ID and Amazon Connect instance ID to ensure authorized data access at the Amazon Connect instance level.
Amazon Connect encrypts personally identifiable information (PII) contact data and customer profiles at rest using a time-limited key specific to your Amazon Connect instance. S3 server-side encryption secures both voice and chat recordings at rest using a KMS data key unique per AWS account. You maintain complete security control to configure user access to call recordings in your S3 bucket, including tracking who listens or deletes call recordings. Amazon Connect encrypts the customer voiceprints with a service-owned KMS key to protect customer identity. All data exchanged between Amazon Connect and other AWS services, or external applications is always encrypted in transit using industry-standard transport layer security (TLS) encryption.
Securing a data lake requires fine-grained controls to ensure authorized data access and use. S3 resources are private and only accessible only by their resource owner by default. The resource owner can create a combination of resource-based or identity-based IAM policies to grant and manage permissions to S3 buckets and objects. Resource-based policies such as bucket policies and ACLs are attached to resources. In contrast, identity-based policies are attached to the IAM users, groups, or roles in your AWS account.
We recommend identity-based policies for most data lake environments to simplify resource access management and service permission for your data lake users. You can create IAM users, groups, and roles in AWS accounts and associate them with identity-based policies that grant access to S3 resources.
The AWS Lake Formation permission model works in conjunction with IAM permissions to govern data lake access. The Lake Formation permission model uses a database management system (DBMS)-style GRANT or REVOKE mechanism. IAM permissions contain identity-based policies. For example, a user must pass permission checks by both IAM and Lake Formation permissions before accessing a data lake resource.
AWS CloudTrail tracks Amazon Connect API calls, including the requester’s IP address and identity and the request’s date and time in CloudTrail Event History. Creating an AWS CloudTrail trail enables continuous delivery of AWS CloudTrail logs to your S3 bucket.
Amazon Athena Workgroups can segregate query execution and control access by users, teams, or applications using resource-based policies. You can enforce cost control by limiting data usage on the Workgroups.
Monitoring
Observability is essential to ensure the availability, reliability, and performance of a
contact center and data lake. Amazon CloudWatch
Amazon Connect sends the instance’s usage data as Amazon CloudWatch metrics at a one-minute interval. Data retention for Amazon CloudWatch metrics is two weeks. Define log retention requirements and lifecycle policies early on ensure regulatory compliance and cost savings for long-term data archival.
Amazon CloudWatch Logs provides a simple way to filter log data and identify non-compliance events for incident investigations and expedite resolutions. You can customize contact flows to detect high-risk callers or potentially fraudulent activities. For example, you can disconnect any incoming contacts that are on your predefined Deny list.
Analytics
A contact center data lake built on a descriptive, predictive, and real-time analytics portfolio helps you extract meaningful insights and respond to critical business questions.
Once your data lands in the S3 data lake, you can use any purpose-built analytics services
such as Amazon Athena and Amazon QuickSight
The overall contact center service quality can make a significant and lasting impact on
the customer’s impression of your organization. Measuring call quality is essential to ensure
a consistent customer experience. This
blog
For a highly scalable data warehousing solution, you can enable data streaming in Amazon
Connect to stream contact records into Amazon Redshift
Machine learning
Building a data lake brings a new paradigm to contact center architecture, empowering your business to deliver enhanced and personalized customer service using machine learning (ML) capabilities.
Traditional ML development is a complex and expensive process. AWS provides the depth and
breadth of high-performance, cost-effective, scalable infrastructure, and flexible ML services
Amazon SageMaker
Reducing friction in a customer journey is essential to avoid customer churn. To add
intelligence to your contact center, you can build AI-powered conversational chatbots
Understanding caller-agent dynamics is essential to improve the overall service quality.
See this blog
For organizations with an international presence, you can build a
multilingual voice experience
Traditional financial planning software creates forecasts based on historical time-series
data without correlating inconsistent trends and relevant variables. Amazon Forecast
Amazon Connect provides call attributes from telephony carriers, such as voice equipment’s
geographic location to show where the call originated, phone device types such as landline or
mobile, number of network segments the call traversed, and other call origination information.
Using the fully managed Amazon Fraud
Detector
