This whitepaper is for historical reference only. Some content might be outdated and some links might not be available.
Availability with dependencies
In the previous section, we mentioned that hardware, software, and potentially other distributed systems are all components of your workload. We call these components dependencies, the things your workload depends on to provide its functionality. There are hard dependencies, which are those things that your workload cannot function without, and soft dependencies whose unavailability can go unnoticed or tolerated for some period of time. Hard dependencies have a direct impact on your workload’s availability.
We might want to try and calculate the theoretical maximum availability of a workload. This is the product of the availability of all of the dependencies, including the software itself, (αn is the availability of a single subsystem) because each one must be operational.
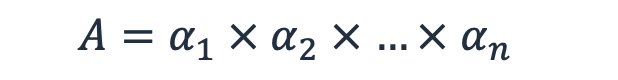
Equation 4 - Theoretical maximum availability
The availability numbers used in these calculations are usually associated with things like SLAs or Service-Level Objectives (SLOs). SLAs define the expected level of service customers will receive, the metrics by which the service is measured, and remediations or penalties (usually monetary) should the service levels not be achieved.
Using the above formula, we can conclude that, purely mathematically, a workload can be no more available than any of its dependencies. But in reality, what we typically see is that this is not the case. A workload built using two or three dependencies with 99.99% availability SLAs can still achieve 99.99% availability itself, or higher.
This is because as we outlined in the previous section, these availability numbers are estimates. They estimate or predict how often a failure occurs and how quickly it can be repaired. They are not a guarantee of downtime. Dependencies frequently exceed their stated availability SLA or SLO.
Dependencies may also have higher internal availability objectives that they target performance against than numbers provided in public SLAs. This provides a level of risk mitigation in meeting SLAs when the unknown or unknowable happens.
Finally, your workload might have dependencies whose SLAs can’t be known or don’t offer an SLA or SLO. For example, world-wide internet routing is a common dependency for many workloads, but it’s hard to know which internet service provider(s) your global traffic is using, whether they have SLAs, and how consistent they are across providers.
What this all tells us is that computing a maximum theoretical availability is only likely to produce a rough order of magnitude calculation, but by itself is likely not to be accurate or provide meaningful insight. What the math does tell us is that the fewer things that your workload relies on reduces the overall likelihood of failure. The fewer numbers less than one multiplied together, the larger the result.
Rule 3
Reducing dependencies can have a positive impact on availability.
The math also helps inform the dependency selection process. The selection process affects how you design your workload, how you take advantage of redundancy in dependencies to improve their availability, and whether you take those dependencies as soft or hard. Dependencies that can have impact on your workload should be carefully chosen. The next rule provides guidance on how to do so.
Rule 4
In general, select dependencies whose availability goals are equal to or greater than the goals of your workload.
