This whitepaper is for historical reference only. Some content might be outdated and some links might not be available.
Measuring availability
As we saw earlier, creating a forward-looking availability model for a distributed system is difficult to do and may not provide the desired insights. What can provide more utility is developing consistent ways to measure the availability of your workload.
The definition of availability as uptime and downtime represents failure as a binary option, either the workload is up or it’s not.
However, this is rarely the case. Failure has a degree of impact and is often experienced in some subset of the workload, affecting a percentage of users or requests, a percentage of locations, or a percentile of latency. These are all partial failure modes.
And while MTTR and MTBF are useful in understanding what drives the resulting availability of a system, and hence, how to improve it, their utility is not as an empirical measure of availability. Additionally, workloads are composed of many components. For example, a workload like a payment processing system is made up of many application programming interfaces (APIs) and subsystems. So, when we want to ask a question like, “what is the availability of the entire workload?”, it's actually a complex and nuanced question.
In this section, we’ll examine three ways availability can be empirically measured: server-side request success rate, client-side request success rate, and annual downtime.
Server-side and client-side request success rate
The first two methods are very similar, only differing from the point of view the measurement is taken. Server-side metrics can be collected from instrumentation in the service. However, they're not complete. If clients aren't able to reach the service, you're unable to collect those metrics. In order to understand the client experience, instead of relying on telemetry from clients about failed requests, an easier way to collect client-side metrics is to simulate customer traffic with canaries, software that regularly probes your services and records metrics.
These two methods calculate availability as the fraction of total valid units of work that the service receives and the ones it processes successfully (this ignores invalid units of work, like an HTTP request that results in a 404 error).

Equation 8
For a request-based service, the unit of work is the request, like an HTTP request. For event-based or task-based services, the units of work are events or tasks, like processing a message off of a queue. This measure of availability is meaningful in short time intervals, like one-minute or five-minute windows. It is also best suited at a granular perspective, like at a per API level for a request-based service. The following figure provides a view of what availability over time might look like when calculated this way. Each data point on the graph is calculated using Equation (8) over a five-minute window (you can choose other time dimensions like one-minute or ten-minute intervals). For example, data point 10 shows 94.5% availability. That means during minutes t+45 to t+50 if the service received 1,000 requests, only 945 of them were processed successfully.
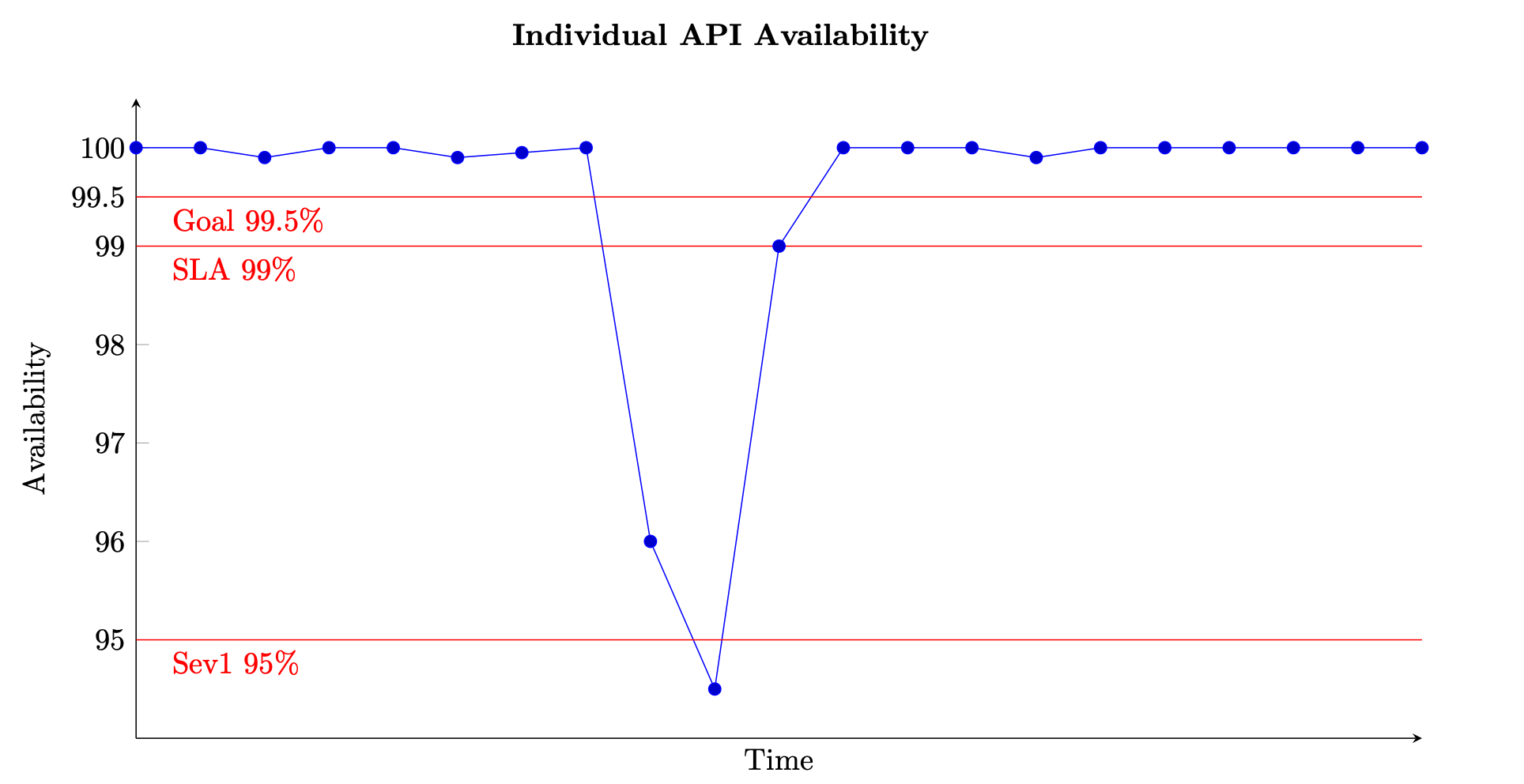
Example of measuring availability over time for a single API
The graph also shows the API’s availability goal, 99.5% availability, the service-level agreement (SLA) it offers to customers, 99% availability, and the threshold for a high-severity alarm, 95%. Without the context of these different thresholds, a graph of availability might not provide significant insight to how your service is operating.
We also want to be able to track and describe the availability of a larger subsystem, like a control plane, or an entire service. One way to do this is to take the average of each five-minute data point for each subsystem. The graph will look similar to the previous one, but will be representative of a larger set of inputs. It also gives equal weight to all subsystems that make up your service. An alternative approach might be to sum all of the requests received and successfully processed from all APIs in the service to calculate availability in five-minute intervals.
However, this latter method might hide an individual API that has low throughput and bad availability. As a simple example, consider a service with two APIs.
The first API receives 1,000,000 requests in a five-minute window and successfully processes 999,000 of them, giving a 99.9% availability. The second API receives 100 requests in that same five-minute window and only successfully processes 50 of them, giving a 50% availability.
If we sum the requests from each API together, there are 1,000,100 total valid requests and 999,050 of them are processed successfully, giving a 99.895% availability for the service overall. But, if we average the availabilities of the two APIs, the former method, we get a resulting availability of 74.95%, which might be more telling of the actual experience.
Neither approach is wrong, but it shows the importance of understanding what availability metrics are telling you. You might choose to favor summing requests for all subsystems if your workload receives a similar request volume across each one. This approach focuses on the “request” and its success as the measure of availability and the customer experience. Alternatively, you might choose to average subsystem availabilities to equally represent their criticality despite request volume differences. This approach focuses on the subsystem and each one’s ability as a proxy for the customer experience.
Annual downtime
The third approach is calculating annual downtime. This form of availability metric is more appropriate to longer-term goal setting and review. It requires defining what downtime means for your workload. You can then measure availability based on the number of minutes that the workload was not in an “outage” condition relative to the total number of minutes in the given period.
Some workloads might be able to define downtime as something like
a drop below 95% availability of a single API or workload function
for a one-minute or five-minute interval (which occurred in the
previous availability graph). You might also only consider
downtime as it applies to a subset of critical data plane
operations. For example, the
Amazon
Messaging (SQS, SNS) Service Level Agreement
Larger, more complex workloads might need to define system-wide availability metrics. For a large e-commerce site, a system-wide metric can be something like customer order rate. Here, a drop of 10% or more in orders compared to the forecasted quantity during any five-minute window can define downtime.
In either approach, you can then sum all periods of outage to calculate an annual availability. For example, if during a calendar year, there were 27 five-minute periods of downtime, defined as the availability of any data plane API dropping below 95%, the overall downtime was 135 minutes (some five-minute periods might have been consecutive, others isolated), representing an annual availability of 99.97%.
This additional method of measuring availability can provide data
and insight missing from client-side and server-side metrics. For
example, consider a workload that’s impaired and experiencing
significantly elevated error rates. Customers of this workload
might stop making calls to its services altogether. Maybe they’ve
activated a
circuit
breaker or followed
their
disaster recovery plan
Latency
Finally, it’s also important to measure the latency of processing units of work within your workload. Part of the availability definition is doing the work within an established SLA. If returning a response takes longer than the client timeout, the perception from the client is that the request failed and the workload is unavailable. However, on the server-side, the request might have appeared to have been processed successfully.
Measuring latency provides another lens with which to evaluate availability. Using percentiles and trimmed mean are good statistics for this measurement. They are commonly measured at the 50th percentile (P50 and TM50) and 99th percentile (P99 and TM99). Latency should be measured with canaries to represent the client experience as well as with server-side metrics. Whenever the average of some percentile latency, like P99 or TM99.9, goes above a target SLA, you can consider that downtime, which contributes to your annual downtime calculation.
