This whitepaper is for historical reference only. Some content might be outdated and some links might not be available.
Logical architecture of modern data lake centric analytics platforms
The following diagram illustrates the architecture of a data lake centric analytics platform.
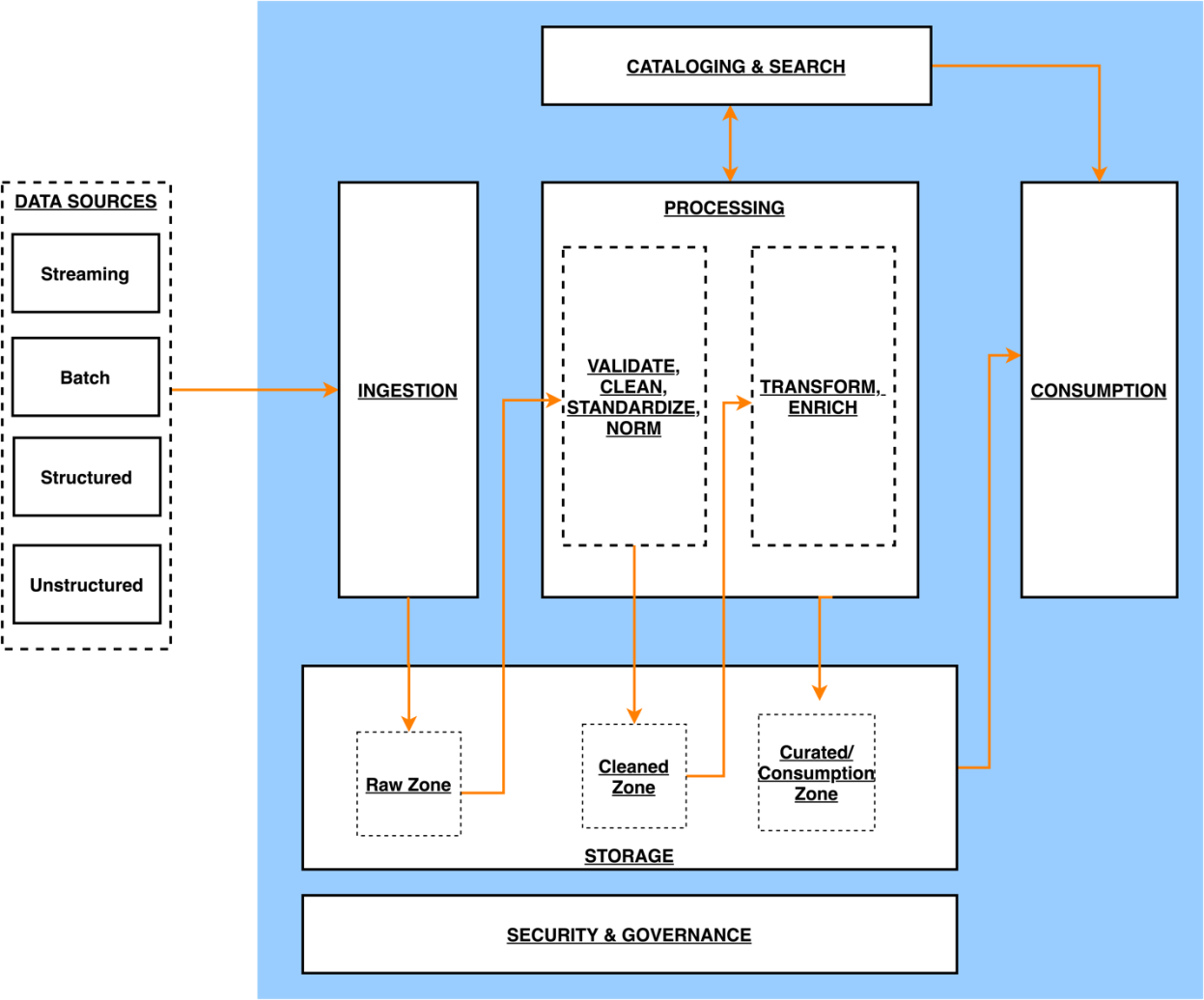
Architecture of a data lake centric analytics platform
You can think of a data lake centric analytics architecture as a stack of six logical layers, where each layer is composed of multiple components. A layered, component-oriented architecture promotes separation of concerns, decoupling of tasks, and flexibility. This provides the agility needed to quickly integrate new data sources, support new analytics methods, and add tools required to keep up with the accelerating pace of changes in the analytics landscape. In the following sections, we look at the key responsibilities, capabilities, and integrations of each logical layer.
Ingestion layer
The ingestion layer is responsible for bringing data into the data lake. It provides the ability to connect to internal and external data sources over a variety of protocols. It can ingest batch and streaming data into the storage layer. The ingestion layer is also responsible for delivering ingested data to a diverse set of targets in the data storage layer including the object store, databases, and warehouses.
Storage layer
The storage layer is responsible for providing durable, scalable, secure, and money- saving components to store vast quantities of data. It supports storing unstructured data and datasets of a variety of structures and formats. It supports storing source data as-is without first needing to structure it to conform to a target schema or format.
Components from all other layers provide easy and native integration with the storage layer. To store data based on its consumption readiness for different personas across organization, the storage layer is organized into the following zones:
-
Raw zone – The storage area where components from the ingestion layer land data. This is a transient area where data is ingested from sources as-is. Typically, data engineering personas interact with the data stored in this zone.
-
Cleaned zone – After the preliminary quality checks, the data from the raw zone is moved to the cleaned zone for permanent storage where the data is stored in its original format. Having all data from all sources permanently stored in the cleaned zone provides the ability to replay downstream data processing in case of errors or data loss in downstream storage zones. Typically, data engineering and data science personas interact with the data stored in this zone.
-
Curated zone – This zone hosts data that is in the most consumption-ready state and conforms to organizational standards and data models. Datasets in the curated zone are typically partitioned, cataloged, and stored in formats that support performant and cost-effective access by the consumption layer. The processing layer creates datasets in the curated zone after cleaning, normalizing, standardizing, and enriching data from the cleaned zone. All personas across organizations use the data stored in this zone to drive business decisions.
Cataloging and search layer
The cataloging and search layer is responsible for storing business and technical metadata about datasets hosted in the storage layer. It provides the ability to track schema and the granular partitioning of dataset information in the lake. It also supports mechanisms to track versions to keep track of changes to the metadata. As the number of datasets in the data lake grows, this layer makes datasets in the data lake discoverable by providing search capabilities.
Processing layer
The processing layer is responsible for transforming data into a consumable state through data validation, cleanup, normalization, transformation, and enrichment. It’s responsible for advancing the consumption readiness of datasets along the raw, cleaned, and curated zones and registering metadata for the cleaned and transformed data into the cataloging layer. The processing layer is composed of purpose-built data- processing components to match the right dataset characteristic and processing task at hand. The processing layer can handle large data volumes and support schema-on- read, partitioned data, and diverse data formats. The processing layer also provides the ability to build and orchestrate multi-step data processing pipelines that use purpose- built components for each step.
Consumption layer
The consumption layer is responsible for providing scalable and performant tools to gain insights from the vast amount of data in the data lake. It supports analytics across all personas across the organization through several purpose-built analytics tools that support analysis methods, including SQL, batch analytics, BI dashboards, reporting, and ML. The consumption layer natively integrates with the data lake’s storage, cataloging, and security layers. Components in the consumption layer support schema- on-read, a variety of data structures and formats, and use data partitioning for cost and performance optimization.
Security and governance layer
The security and governance layer is responsible for protecting the data in the storage layer and processing resources in all other layers. It provides mechanisms for access control, encryption, network protection, usage monitoring, and auditing. The security layer also monitors activities of all components in other layers and generates a detailed audit trail. Components of all other layers provide native integration with the security and governance layer.
