This whitepaper is for historical reference only. Some content might be outdated and some links might not be available.
Example 1: Queries against an Amazon S3 data lake
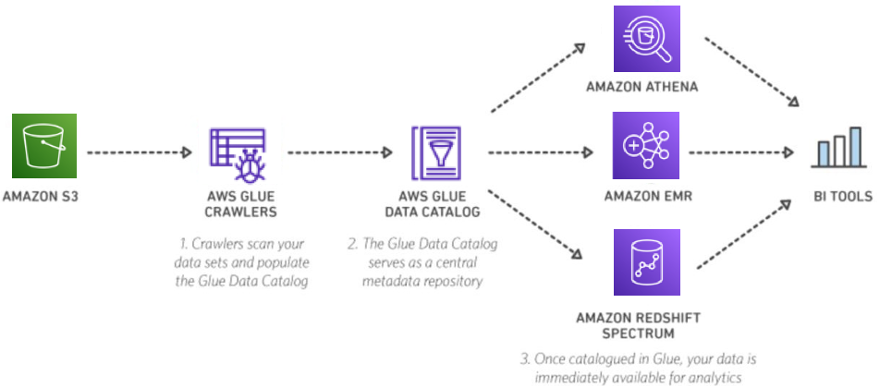
Data lakes are an increasingly popular way to store and analyze both structured and
unstructured data. If you use an Amazon S3 data lake, AWS Glue can make all your data immediately
available for analytics without moving the data. AWS Glue crawlers can scan your data lake
and keep the AWS Glue Data Catalog in sync with the underlying data. You can then directly query your
data lake with Amazon Athena and Amazon Redshift Spectrum. You can also use the AWS Glue Data Catalog as your external
Apache Hive
Metastore
Queries against an Amazon S3 data lake
-
An AWS Glue crawler connects to a data store, progresses through a prioritized list of classifiers to extract the schema of your data and other statistics, and then populates the AWS Glue Data Catalog with this metadata. Crawlers can run periodically to detect the availability of new data as well as changes to existing data, including table definition changes. Crawlers automatically add new tables, new partitions to existing table, and new versions of table definitions. You can customize AWS Glue crawlers to classify your own file types.
-
The AWS Glue Data Catalog is a central repository to store structural and operational metadata for all your data assets. For a given data set, you can store its table definition, physical location, add business relevant attributes, as well as track how this data has changed over time. The AWS Glue Data Catalog is Apache Hive Metastore compatible and is a drop-in replacement for the Apache Hive Metastore for Big Data applications running on Amazon EMR. For more information on setting up your EMR cluster to use AWS Glue Data Catalog as an Apache Hive Metastore, see AWS Glue documentation.
-
The AWS Glue Data Catalog also provides out-of-box integration with Amazon Athena, Amazon EMR, and Amazon Redshift Spectrum. After you add your table definitions to the AWS Glue Data Catalog, they are available for ETL and also readily available for querying in Amazon Athena, Amazon EMR, and Amazon Redshift Spectrum so that you can have a common view of your data between these services.
-
Using a BI tool like Amazon Quick Suite enables you to easily build visualizations, perform ad hoc analysis, and quickly get business insights from your data. Amazon Quick Suite supports data sources such as Amazon Athena, Amazon Redshift Spectrum, Amazon S3 and many others. See Supported Data Sources.
