This whitepaper is for historical reference only. Some content might be outdated and some links might not be available.
What is a modern data architecture?
A modern
data architecture on AWS
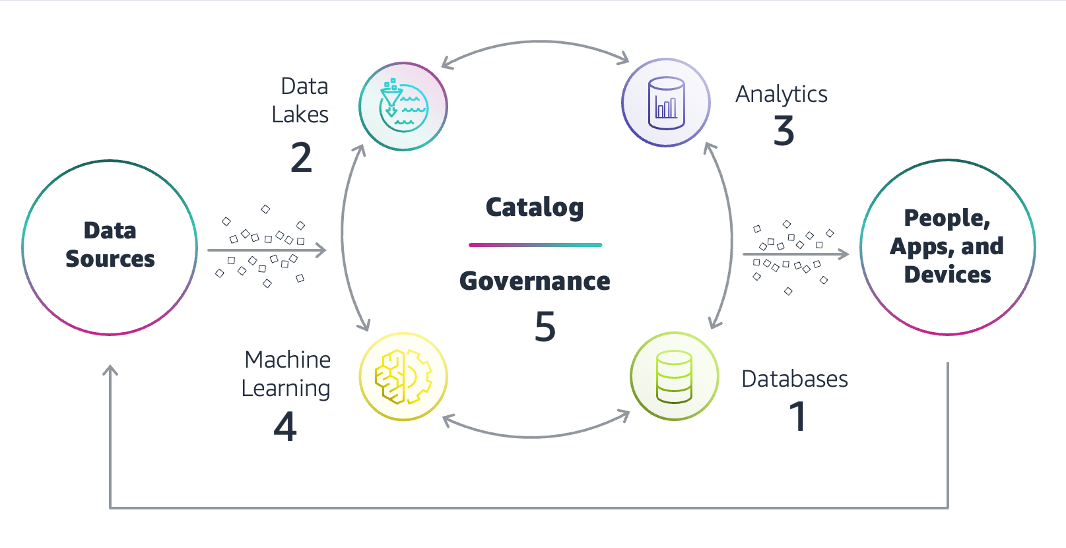
Modern data architecture on AWS
The modern data architecture includes the following key components:
-
Databases – You can store data in purpose-built databases that can support a modern application and its different features. This database no longer needs to be a single type of relational database—it could be a NoSQL database, cache store, or anything else that works for the application. AWS offers over 15 purpose-built engines
to support diverse data models, including relational, key-value, document, in-memory, graph, time series, wide column, and ledger databases. -
Data lakes – It makes sense to then use a data lake on a storage service like Amazon S3
so you can store data from all those purposes-built databases, preferably in its native format or in an open file format. AWS-powered data lakes , supported by the unmatched availability of Amazon S3, can handle the scale, agility, and flexibility required to combine different data and analytics approaches. -
Analytics – Once the data lake is hydrated with data, you can easily build modern analytics, which might range from traditional data warehousing and batch reporting to more real-time analytics, near real-time alerting and reporting, and so on. It might even be one-time querying of data or more advanced ML-based analytics use cases. Organizations aren’t constrained within data silos because data is now stored in a layer that is more open and allows more freedom for performing comprehensive analytics. AWS provides the broadest and deepest portfolio of purpose-built analytics services
, including Athena , Amazon EMR , OpenSearch Service , Kinesis , Amazon MSK , and Amazon Redshift for your unique analytics use cases. -
Machine learning – ML and AI are also critical for a modern data strategy to help organizations predict what might happen in the future and build intelligence into their systems and applications. AWS offers the broadest and deepest set of machine learning services
and supporting cloud infrastructure , putting machine learning in the hands of every developer, data scientist, and expert practitioner. When you build an ML-based workload in AWS, you can choose from three different levels of ML services to balance speed-to-market with your level of customization and ML skill level: AI services , ML services , and ML frameworks and infrastructure . -
Data governance – Finally, data governance is a critical element to combining and sharing data from different sources so you can put data in the hands of people at all levels of your organization. Metadata is an integral part of data management and governance. The AWS Glue
Data Catalog can provide a uniform repository to store and share metadata. The main purpose of the Data Catalog is to provide a central metadata store where disparate systems can store, discover, and use that metadata to query and process the data. Another important aspect of data governance is serving and managing the relationship between data stores and external clients, which are the producers and consumers of data. As the data evolves, especially in streaming use cases, we need a central framework that provides a contract between producers and consumers to enable schema evolution and improved governance. The AWS Glue Data Catalog provides a centralized framework to help manage and enforce schemas on data streaming applications using convenient integrations with Apache Kafka and Amazon Managed Streaming for Apache Kafka , Amazon Kinesis Data Streams , Apache Flink , Amazon Managed Service for Apache Flink , and Lambda .
AWS provides a broad platform of managed services to help you build, secure, and seamlessly scale end-to-end data analytics applications quickly, using the modern data architecture approach. There is no hardware to procure, no infrastructure to maintain and scale—only what you need to collect, store, process, and analyze your data. AWS offers analytical solutions specifically designed to handle this growing amount of data, and provide insight into your business.
