This whitepaper is for historical reference only. Some content might be outdated and some links might not be available.
Building the ML platform
To support data science workflows from experimentation to ML model productionization, an ML platform needs to provide several core platform capabilities, including:
-
Data management with tooling for data ingestion, processing, distribution, orchestration, and data access control
-
Data science experimentation environment with tooling for data analysis / preparation, model training / debugging / validation / deployment, access to code management repos and library packages, and self-service provisioning
-
Workflow automation and CI/CD pipelines for automated model training, code / Docker image packaging, and model deployment in the production environment
Data management
Amazon S3 is the primary storage for building an ML platform on AWS. The datasets needed for
machine learning workflow should be ingested into S3 for easy and secure access from other
data processing and machine learning services. AWS recommends that you build a data lake on S3
to centrally manage data storage, ETL, data catalog, and security. You can consider the AWS Lake Formation
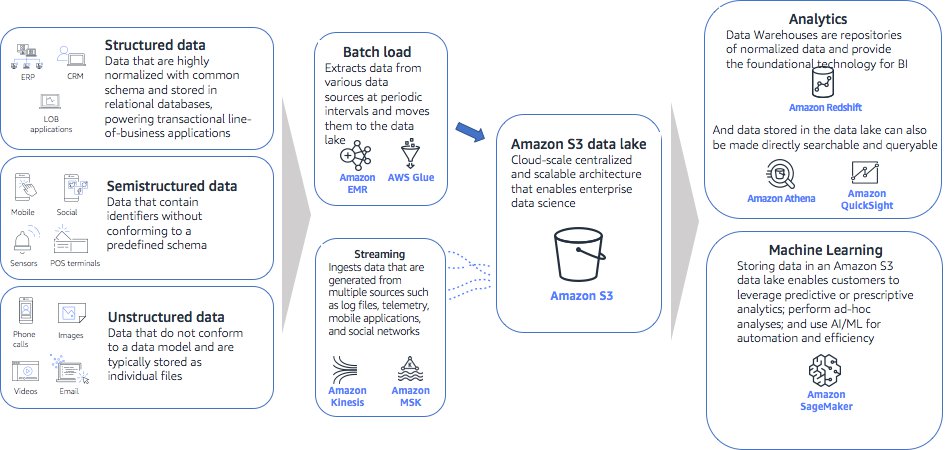
Data management architecture for analytics and machine learning
Detailed enterprise data management design is out of scope for this document. The following section focuses on the S3 bucket design to support machine learning tasks in various environments.
Machine learning services such as SageMaker AI use Amazon S3 as the primary storage for experimentation, data processing, model training, and model hosting. To support data scientists' workflow and the automated CI/CD ML pipelines, a set of S3 buckets or folders should be created with proper data classification and data access control in mind. S3 provides security and access management features through IAM to control access to different buckets and folders. Follow known S3 best practices and other techniques such as data partitioning to optimize S3 performance. For machine learning workflow support, the following S3 buckets should be considered:
-
Buckets for users / project teams — These buckets are used by individual data scientists or teams of data scientists with common access permission to the experimentation data. Data scientists pull data from the enterprise data management platform or other data sources and store them in these buckets for further wrangling and analysis. Data scientists also store training / validation / test datasets, and other experimentation artifacts such as training scripts and Docker files in these buckets for individual / team experimentations.
-
Buckets for common features — Common features (for example, customer features, product features, and embedding features) that can be shared across different teams or projects can be stored in a set of common feature buckets. Organizational data access policies should govern access to these buckets, and consider providing individual data scientists with read-only access to these datasets if the data is not meant to be modified by individual data scientists. If you want to use a managed feature store, consider the SageMaker AI Feature Store
to share features across teams. -
Buckets for training / validation/test datasets — For formal model training and tracking, the training / validation/test datasets for each model training pipeline need to be properly managed and versioned for traceability and reproducibility. These buckets will be the data sources for automated ML training pipelines.
-
Buckets for ML automation pipelines — These are buckets used to store data needed for automation pipelines and should only be accessible by the automation services. For example, a bucket used by AWS CodePipeline to store artifacts (such as training script or Docker files) checked out from a code repository.
-
Buckets for models — Model artifacts generated by the automation pipelines are stored in model buckets. Models used in production should be properly version controlled and tracked for lineage traceability.
