This whitepaper is for historical reference only. Some content might be outdated and some links might not be available.
Catalog and search
The earliest challenges that inhibited building a data lake were keeping track of all of the raw assets as they were loaded into the data lake, and then tracking all of the new data assets and versions that were created by data transformation, data processing, and analytics. Thus, an essential component of a data lake built on Amazon S3 is the Data Catalog. The Data Catalog provides an interface to query all assets stored in data lake S3 buckets. The Data Catalog is designed to provide a single source of truth about the contents of the data lake.
AWS Glue
AWS Glue
To create a Data Catalog, use AWS Glue crawlers that crawl the data from the data sources as registered with AWS Glue in the AWS Management Console. The data source can be an S3 bucket, a table in Amazon RDS, Amazon DynamoDB, or Amazon Redshift, or any external database that supports JDBC connectivity.
You can define custom classifiers or use the built-in classifiers provided by AWS Glue to classify the data. AWS Glue provides classifiers for common file types, such as CSV, JSON, AVRO, or XML. AWS Glue also provides classifiers for common relational database management systems using a JDBC connection. You can create a custom classifier using a grok pattern, an XML tag, JavaScript Object Notation (JSON), or comma-separated values (CSV). The following figure depicts the working of AWS Glue in building a Data Catalog.
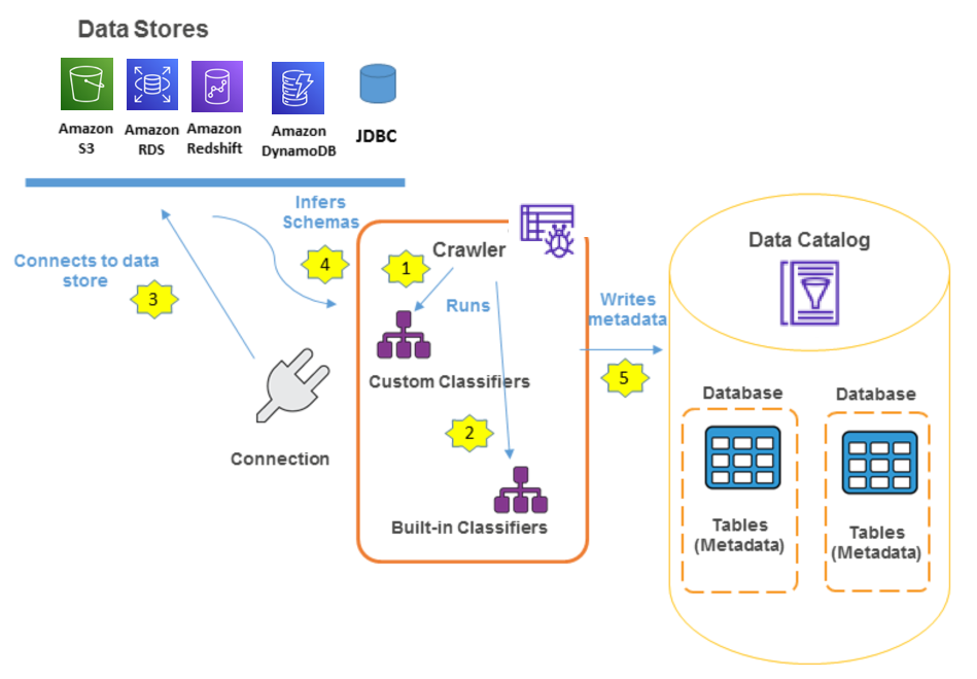
AWS Glue Data Catalog
Data Catalog is a database that stores metadata in tables consisting of data schema, data location, and runtime metrics. Data Catalog is also Apache Hive metastore compatible that can be used as a central repository for storing structural and operational metadata. AWS Glue also provides out-of-box integration with Amazon EMR that allows you to use Data Catalog as an external Hive metastore. Data Catalog is recommended, especially when you need a persistent metastore or a metastore shared between different applications, services, clusters, or AWS accounts. Data Catalog can also be used to create an external table for Athena or Amazon Redshift.
AWS Lake Formation
AWS Lake Formation
Lake Formation uses AWS Glue Data Catalog to automatically classify data in data lakes, data sources, transforms, and targets. Apart from the metadata, the Data Catalog also stores information consisting of resource links to shared databases and tables in external accounts for cross account access to the data in a data lake built on S3.
Lake Formation provides you with a grant/revoke permission model to control access to Data Catalog resources (consisting of database and metadata tables), S3 buckets and underlying data in these buckets. Lake Formation permissions along with IAM policies provide granular access to the data stored in data lakes built on S3. These permissions can be used to share Data Catalog resources with external AWS accounts. The users from these accounts can run jobs and queries by combining data from multiple data catalogs across multiple accounts.
Comprehensive data catalog
You have the flexibility to create a comprehensive data catalog using standard AWS services such as AWS Lambda, DynamoDB, and Amazon OpenSearch Service. At a high level, AWS Lambda triggers are used to populate DynamoDB tables with object names and metadata when those objects are put into S3; Amazon OpenSearch Service is used to search for specific assets, related metadata, and data classifications. The following figure shows a high-level architectural overview of this solution.

Comprehensive data catalog using AWS Lambda, DynamoDB, and Amazon OpenSearch Service
