This whitepaper is for historical reference only. Some content might be outdated and some links might not be available.
Securing, protecting, and managing data
Building a data lake, and making it the centralized repository for assets that were previously duplicated and placed across many siloes of smaller platforms and groups of users, requires implementing stringent and fine-grained security and access controls along with methods to protect and manage the data assets. A data lake solution on AWS—with S3 as its core—provides a robust set of features and services to secure and protect your data against both internal and external threats, even in large, multi-tenant environments. Additionally, innovative S3 data management features allow automation and scaling of data lake storage management, even when it contains billions of objects and petabytes of dataassets.
Securing your data lake begins with implementing very fine-grained controls that allow authorized users to view, access, process, and modify particular assets, and ensure that unauthorized users are blocked from taking any actions that would compromise data confidentiality and security. A complicating factor is that access roles may evolve over various stages of a data asset’s processing and lifecycle. Fortunately, Amazon has a comprehensive and well-integrated set of security features, such as access policy, resource-based policies, bucket policies, and data encryption, to secure a data lake built on S3.
Access policy options
You can manage access to your S3 resources using access policy options. By default, all S3 resources—buckets, objects, and related sub-resources—are private (only the resource owner, an AWS account that created them, can access the resource). The resource owner can then grant access permissions to other users by writing an access policy. S3 access policy options are broadly categorized as resource-based policies and user policies. Access policies that are attached to resources are referred to as resource-based policies. Examples of resource-based policies include bucket policies and access-control lists. Access policies that are attached to users in an account are called user policies. Typically, a combination of resource-based and user policies are used to manage permissions to S3 buckets, objects, and other resources.
When you are creating a centralized data lake, you want to provide access to various different accounts and users from different accounts. You can define a bucket policy to manage permissions for cross-account access, and manage permissions for users in another account. Bucket policies can be defined based on various factors, such as S3 operations, type of requestor, type of resources, and the nature of the request. A bucket policy defined for a bucket is applicable for all the objects in the bucket. This way you can manage the permissions for all the objects centrally instead of managing access for individual objects. Bucket policies can also be customized as per the user requirements, for example, a bucket policy can be defined to allow access to a particular S3 bucket for a time interval when the request is originated from a particular Classless Inter-Domain Routing (CIDR) block.
Similar to bucket policies, access-control lists are also used for managing permissions to a bucket or an object. Access-control lists differ from bucket policies in multiple ways. Access-control lists can only provide read/write permissions to an object or bucket. Additionally, access-control lists can be used when granting bucket permission to other accounts or users in other accounts. Object access-control lists are helpful when you want to manage access at an object level. The bucket owner can grant permission to another account to upload the object using object access-control lists. However, bucket access-control lists can be used to provide access to the S3 Log Delivery group to write access logs to the S3 bucket.
For most data lake environments, AWS recommends using user policies, so that permissions to access data assets can also be linked to user roles and permissions for the data processing and analytics services and tools that your data lake users will use. User policies are also recommended to be used if you want to provide access to a user for objects in a bucket. User policies are associated with IAM, which allows you to securely control access to AWS services and resources. With IAM, you can create users, groups, and roles in accounts and then attach access policies to them that grant access to AWS resources, including S3. The model for user policies is shown inthe following figure. For more details and information on securing S3 with userpolicies and IAM, refer to Amazon S3 security and Identity and access management in Amazon S3.
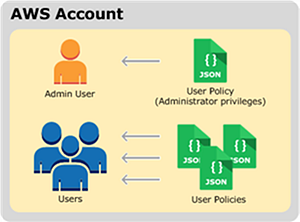
Model for user policies
Data Encryption with Amazon S3 and AWS KMS
Although user policies and IAM control who can review and access data in your data lake built on S3, it’s also important to ensure that users who might inadvertently or maliciously gain access to those data assets can’t review and use them. This is accomplished by using encryption keys to encrypt and decrypt data assets. S3 supports multiple encryption options.
AWS KMS helps scale and simplify management of encryption keys. AWS KMS gives you centralized control over the encryption keys used to protect your data assets. You can create, import, rotate, disable, delete, define usage policies for, and audit the use of encryption keys used to encrypt your data. AWS KMS is integrated with several other AWS services, making it easy to encrypt the data stored in these services with encryption keys. AWS KMS is integrated with AWS CloudTrail, which provides you with the ability to audit who used which keys, on which resources, and when.
Data lakes built on AWS primarily use two types of encryption: server-side encryption and client-side encryption. Server-side encryption provides data-at-rest encryption for data written to S3. With server-side encryption, S3 encrypts user data assets at the object level, stores the encrypted objects, and then decrypts them as they are accessed and retrieved. With client-side encryption, data objects are encrypted before they are written into S3. For example, a data lake user can specify client-side encryption before transferring data assets into S3 from the internet, or can specify that services such as Amazon EMR, Amazon Athena, or Amazon Redshift use client-side encryption with S3.
Server-side encryption and client-side encryption can be combined for the highest levels of protection. Given the intricacies of coordinating encryption key management in a complex environment, such as a data lake, AWS strongly recommends using AWS KMS to coordinate keys across client-side and server-side encryption and across multiple data processing and analytics services.
For even greater levels of data lake protection, other services, such as Amazon API Gateway, Amazon Cognito,
and IAM, can be combined to create a “shopping cart” model for users to check in and check
out data lake assets. This data Lake on AWS
solution architecture
Based on the compliance requirements, PII data must be handled separately and setup encryption with dedicated hardware. However, using a dedicated hardware hosted in the security account will introduce additional latency during data processing. You can use AWS CloudHSM or HashiCorp Vault to store the keys. By using CloudHSM you can configure a CloudHSM cluster to store your custom keys and authorize AWS KMS to use it as a dedicated key store. The following figure shows the primary components of CloudHSM and a cluster of two CloudHSM instances connected to AWS KMS to create a customer-controlled key store.
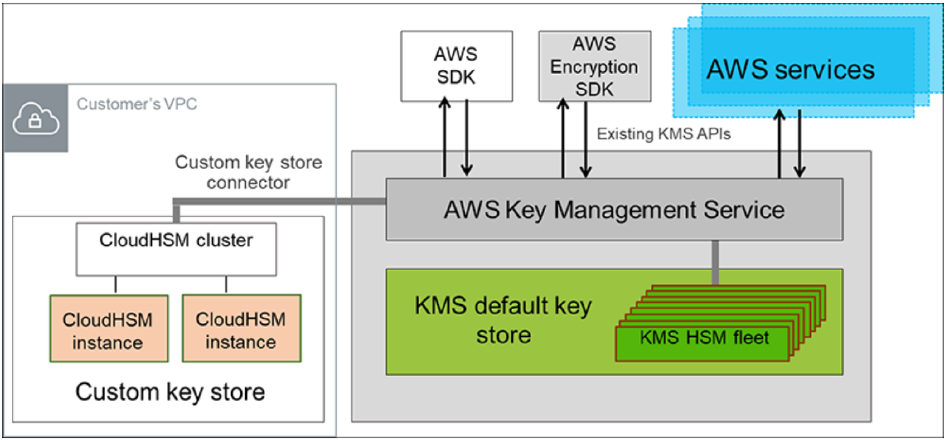
Customer-controlled key store using AWS CloudHSM cluster and AWS KMS
Protecting data with Amazon S3
A vital function of a centralized data lake is data asset protection—primarily protection against corruption, loss, and accidental or malicious overwrites, modifications, or deletions. Amazon S3 has several intrinsic features and capabilities to provide the highest levels of data protection when it is used as the core platform for a data lake.
Data protection rests on the inherent durability of the storage platform used. Durability is defined as the ability to protect data assets against corruption and loss. Amazon S3 provides 99.999999999% data durability, which is 4 to 6 orders of magnitude greater than that which most on-premises, single-site storage platforms can provide. Put another way, the durability of Amazon S3 is designed so that 10,000,000 data assets can be reliably stored for 10,000 years.
Amazon S3 achieves this durability in all 24 of its global Regions by using multiple Availability Zones. Availability Zones consist of one or more discrete data centers, each with redundant power, networking, and connectivity, housed in separate facilities. Availability Zones offer the ability to operate production applications and analytics services, which are more highly available, fault tolerant, and scalable than would be possible from a single data center. Data written to Amazon S3 is redundantly stored across three Availability Zones and multiple devices within each Availability Zone to achieve 99.9999999% durability. This means that even in the event of an entire data center failure, data would not be lost.
In addition to core data protection, another key element for data assets is to protect against unintentional and malicious deletion and corruption, whether through users accidentally deleting data assets, applications inadvertently deleting or corrupting data, or rogue actors trying to tamper with the data. This becomes especially important in a large multi-tenant data lake, which will have a large number of users, many applications, and constant necessary data processing and application development.
S3 provides versioning to protect data assets against these scenarios. When enabled, S3 versioning will retain multiple copies of a data asset. When an asset is updated, prior versions of the asset will be retained and can be retrieved at any time. If an asset is deleted, the last version of it can be retrieved.
Data asset versioning can be managed by policies, to automate management at large scale. These policies can be combined with other Amazon S3 capabilities, such as lifecycle management for long-term retention of versions on lower cost storage tiers. Examples of such storage tiers include Amazon S3 Glacier, and Multi-Factor-Authentication (MFA) Delete. These lower cost tiers require a second layer of authentication—typically through an approved external authentication device—to delete data asset versions. Even though S3 provides 99.999999999% data durability within an AWS Region, many enterprise organizations may have compliance and risk models that require them to replicate their data assets to a second geographically distant location and build disaster recovery architectures in a second location.
S3 Cross-Region Replication is an integral S3 capability that automatically and asynchronously copies data assets from a data lake in one AWS Region to a data lake in a different AWS Region. The data assets in the second Region are exact replicas of the source data assets that they were copied from, including their names, metadata, versions, and access controls. All data assets are encrypted during transit with SSL to ensure the highest levels of data security.
Another Amazon S3 feature is S3 Object
Lock. This feature allows you to write objects using the WORM model. You can use
Object Lock for scenarios which make it imperative that the data is not updated or deleted
after it is written. You can also use Object Lock to satisfy compliance regulations in the
financial and healthcare sectors, or retain the original copies of the data for reconciliation
and auditing purposes. Object Lock has been assessed for SEC Rule 17a-4(f), FINRA Rule 4511,
and CFTC Regulation 1.31 by Cohasset Associates. You can download a copy of the Cohasset Associates Assessment report
When creating a data lake on S3, you store millions of objects in the data lake, necessitating an information asset register to keep track of the different objects, their replication status, updates, and versions. You can use Amazon S3 Inventory to audit and report on the replication and encryption status of the objects for business, compliance, and regulatory needs.
All of these S3 features and capabilities—when combined with other AWS services such as IAM, AWS KMS, Amazon Cognito, and Amazon API Gateway—ensure that a data lake using Amazon S3 as its core storage platform will meet the most stringent data security, compliance, privacy, and protection requirements. Amazon S3 includes a broad range of certifications, including PCI-DSS, HIPAA/HITECH, FedRAMP, SEC Rule 17-a-4, FISMA, EU Data Protection Directive, and many other global agency certifications. These levels of compliance and protection allow organizations to build a data lake on AWS that operates more securely and with less risk than one built in their own on-premises data centers.
Managing data with object tagging
Because data lake solutions are inherently multi-tenant, with many organizations, lines of businesses, users, and applications using and processing data assets, it becomes very important to associate data assets to all of these entities and set policies to manage these assets coherently. S3 has introduced a new capability—object tagging—to assist with categorizing and managing S3 data assets. An object tag is a mutable key-value pair. Each S3 object can have up to 10 object tags. Each tag key can be up to 128 Unicode characters in length, and each tag value can be up to 256 Unicode characters in length. For example, suppose an object contains protected health information (PHI) data. A user, administrator, or application that uses object tags might tag the object using the key-value pair PHI=True or Classification=PHI.
In addition to being used for data classification, object tagging offers other important capabilities. Object tags can be used in conjunction with IAM to enable fine-grained controls of access permissions. For example, a particular data lake user can be granted permissions to only read objects with specific tags.
Object tags can also be used to manage S3 data lifecycle policies, which is discussed in the Monitoring and optimizing the data lake environment section of this document. A data lifecycle policy can contain tag-based filters. Finally, object tags can be combined with Amazon CloudWatch metrics and AWS CloudTrail logs—also discussed in the Monitoring and optimizing the data lake environment section of this document—to display monitoring and action audit data by specific data asset tag filters. In addition to object tags, you can also enable cost allocation tags for your S3 buckets to track storage cost across projects. Cost allocation tags are used for itemized costs for resources in the cost allocation report.
The following tags are recommended based on the requirements and specific use cases.
Table 1 — Recommended tags
| Key | Value | Description |
|---|---|---|
| Owner | Team | Can be used in different stages of the bucket, and in user buckets to create data ownership. |
| Security | Private, Public, or Role based | Helps in creating access control and data inventory. |
| Environment | Non-Production (Development, Testing) or Production | Helps in sharing the bucket across environments, minimizing data duplication, and helps in complete testing. |
| Privileged | Yes or No | Helps in finer access control without the need to replicate data in separate buckets. |
| Retention | Time frame | Helps lifecycle policy to move data across different storage classes (S3 Standard-IA, S3 One Zone-IA, and S3 Glacier) for cost optimization. |
AWS Lake Formation: Centralized governance and access control
Using AWS Lake Formation, you can centrally govern your data lake and control access to your data by defining granular data access policies to the metadata and data through grant or revoke permissions model. Lake Formation integrates with IAM to define access control across the following two areas:
-
Metadata access control – Permissions for Data Catalog resources. These permissions enable principals to create, read, update, and delete metadata databases and tables in the Data Catalog.
-
Underlying data access control – Permissions on locations in Amazon S3. Data access permissions enable principals to read and write data to underlying S3 locations. Data location permissions enable principals to create metadata databases and tables that point to specific S3 locations.
Lake Formation uses the same metadata catalog used by AWS Glue and you can use AWS Glue crawlers to create data catalogs for the data stored in your data lakes. Because Lake Formation combines with IAM permissions, you should have the necessary IAM permissions and Lake Formation permissions to use Lake Formation and the integrated services (AWS Glue for Data Catalog and crawlers, Amazon Athena, Amazon Redshift, and Amazon EMR).
Lake Formation also controls access of integrated services to data stored in data lakes using fine-grained policies. You can define named resources access control to grant permissions to specific databases or tables by specifying database or table names. The recommended method to grant permissions is tag-based access control (TBAC) because it simplifies access control while managing a large number of Data Catalog resources and principals.
TBAC allows you to grant permissions based on one or more Lake Formation tags (LF-tags). You can create LF-tags; assign LF-tags to Data Catalog resources such as databases, tables, and columns; and grant LF-tags permissions to principals optionally with grant option. The tag-based access control method is recommended when you want to manage a large number of Data Catalog resources.
