This whitepaper is for historical reference only. Some content might be outdated and some links might not be available.
Caching patterns
When you are caching data from your database, there are caching patterns for Redis and Memcached that you can implement, including proactive and reactive approaches. The patterns you choose to implement should be directly related to your caching and application objectives.
Two common approaches are cache-aside or lazy loading (a reactive approach) and write-through (a proactive approach). A cache-aside cache is updated after the data is requested. A write-through cache is updated immediately when the primary database is updated. With both approaches, the application is essentially managing what data is being cached and for how long.
The following diagram is a typical representation of an architecture
that uses a remote
distributed
cache
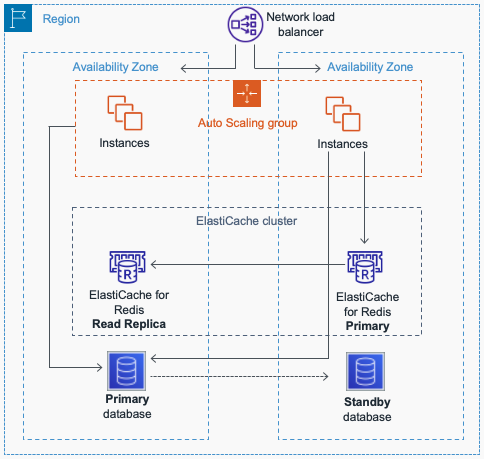
Architecture using remote distributed cache
Cache-Aside (Lazy Loading)
A cache-aside cache is the most common caching strategy available. The fundamental data retrieval logic can be summarized as follows:
-
When your application needs to read data from the database, it checks the cache first to determine whether the data is available.
-
If the data is available (a cache hit), the cached data is returned, and the response is issued to the caller.
-
If the data isn’t available (a cache miss), the database is queried for the data. The cache is then populated with the data that is retrieved from the database, and the data is returned to the caller.
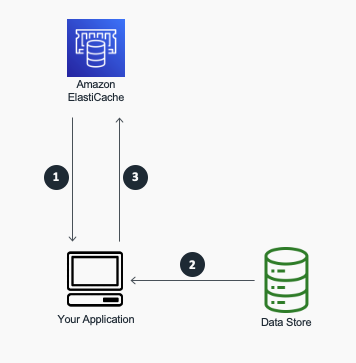
A cache-aside cache
This approach has a couple of advantages:
-
The cache contains only data that the application actually requests, which helps keep the cache size cost-effective.
-
Implementing this approach is straightforward and produces immediate performance gains, whether you use an application framework that encapsulates lazy caching or your own custom application logic.
A disadvantage when using cache-aside as the only caching pattern is that because the data is loaded into the cache only after a cache miss, some overhead is added to the initial response time because additional roundtrips to the cache and database are needed.
Write-Through
A write-through cache reverses the order of how the cache is populated. Instead of lazy-loading the data in the cache after a cache miss, the cache is proactively updated immediately following the primary database update. The fundamental data retrieval logic can be summarized as follows:
-
The application, batch, or backend process updates the primary database.
-
Immediately afterward, the data is also updated in the cache.
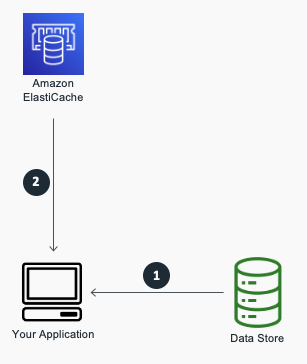
A write-through cache
The write-through pattern is almost always implemented along with lazy loading. If the application gets a cache miss because the data is not present or has expired, the lazy loading pattern is performed to update the cache.
The write-through approach has a couple of advantages:
-
Because the cache is up-to-date with the primary database, there is a much greater likelihood that the data will be found in the cache. This, in turn, results in better overall application performance and user experience.
-
The performance of your database is optimal because fewer database reads are performed.
A disadvantage of the write-through approach is that infrequently-requested data is also written to the cache, resulting in a larger and more expensive cache.
A proper caching strategy includes effective use of both write-through and lazy loading of your data and setting an appropriate expiration for the data to keep it relevant and lean.
-
