Derive insights with outside-in data movement
You can also move data in the other direction: from the outside-in. For example, you can copy query results for sales of products in a given Region from your data warehouse into your data lake, to run product recommendation algorithms against a larger data set using machine learning. Think of this concept as outside-in data movement.
Outside-in data movement
Derive insights from Amazon DynamoDB data for real-time prediction with Amazon SageMaker
Amazon DynamoDB
The following diagram illustrates the Modern Data outside-in data movement with DynamoDB data to derive personalized recommendations.

Derive insights from Amazon DynamoDB data for real-time prediction with Amazon SageMaker
The steps that data follows through the architecture are as follows:
-
Export DynamoDB tables as JSON into Amazon S3.
-
Exported JSON files are converted to comma-separated value (
.csv) format to use as a data source for Amazon SageMakerby using AWS Glue. -
Amazon SageMaker renews the model artifact and updates the endpoint.
-
The converted
.csvfile is available for ad hoc queries with Athena.
Derive insights from Amazon Aurora data with Apache Hudi, AWS Glue, AWS DMS, and Amazon Redshift
AWS Database Migration Service
The following diagram illustrates the Modern Data outside-in data movement with Amazon Aurora Postgres-changed data to derive analytics.
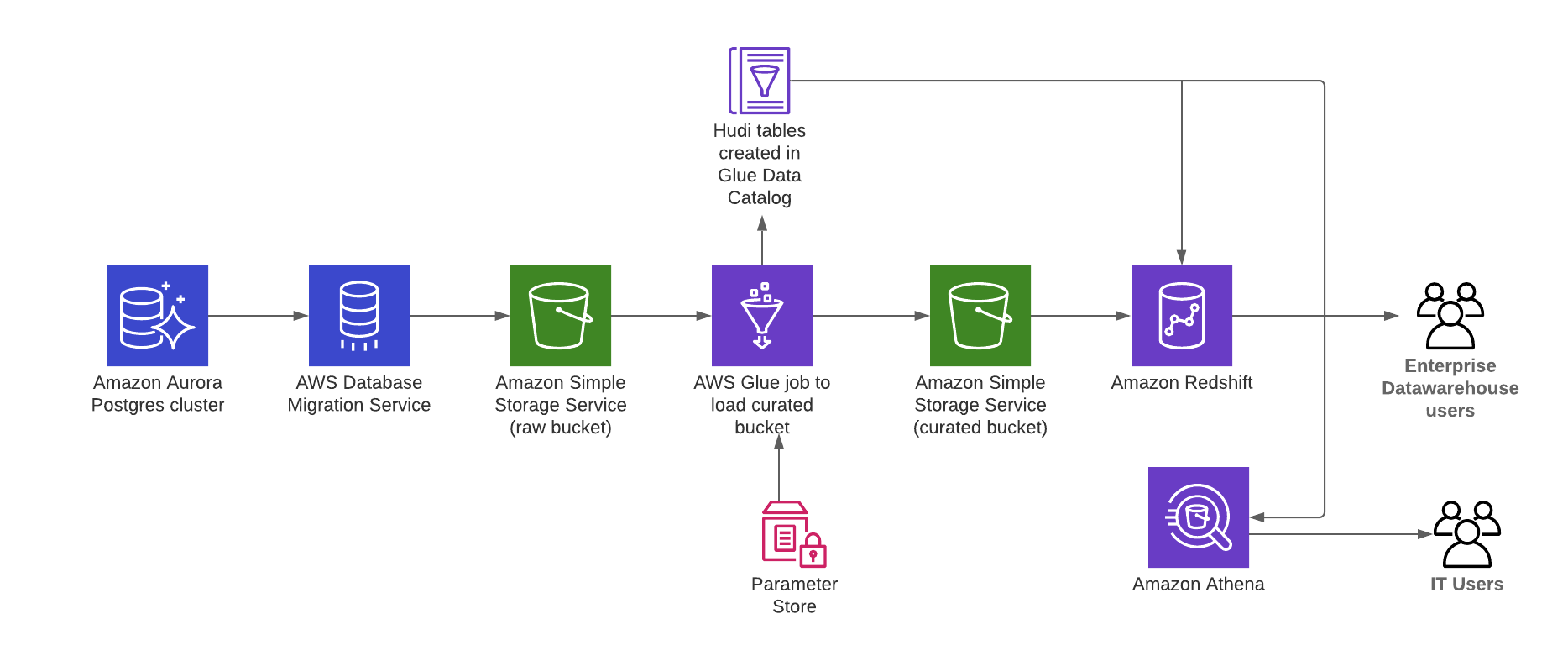
Derive insights from Amazon Aurora data with Apache Hudi, AWS Glue, AWS DMS, and Amazon Redshift
The steps that data follows through the architecture are as follows:
-
AWS DMS replicates the data from the Aurora cluster to the raw S3 bucket.
-
Use Apache Hudi
to create tables in the AWS Glue Data Catalog using AWS Glue jobs. An AWS Glue job (HudiJob) that is scheduled to run at a frequency set in the ScheduleToRunGlueJob parameter. -
This job reads the data from the raw S3 bucket, writes to the curated S3 bucket, and creates a Hudi table in the Data Catalog.
-
The job also creates an Amazon Redshift
external schema in the Amazon Redshift cluster. -
You can now query the Hudi table in Amazon Athena
or Amazon Redshift .
Refer to the blog post Creating a source to Lakehouse data replication pipe using Apache Hudi, AWS Glue, AWS
DMS, and Amazon Redshift
