This whitepaper is for historical reference only. Some content might be outdated and some links might not be available.
Transferring genomics data to the Cloud and establishing data access patterns using AWS DataSync and AWS Storage Gateway for files
Transferring genomics data to the AWS Cloud requires preparation in order to manage data transfer and storage cost, optimize data transfer performance, and manage the data lifecycle.
Recommendations
When you are ready to transfer your organization’s genomics data to the AWS Cloud, consider the following recommendations to help optimize the data transfer process.
Use Amazon Simple Storage Service (Amazon S3) for genomics data storage—Genomics data is persisted in files by sequencers while genomics analysis tools take files as inputs and write files as outputs. This makes Amazon S3 a natural fit for storing genomics data, data lake analytics, and managing the data lifecycle.
Use the Amazon S3 Standard-Infrequent
Access storage tier for transferring genomics data to Amazon S3—Typically, genomics Binary Base Call (BCL) files and
Binary Alignment Map (BAM) files are accessed infrequently,
perhaps a few times in a month. These files can be stored using
the
Amazon S3 Standard-Infrequent Access
Manage genomics data lifecycle by archiving to a low-cost storage option such as Amazon S3 Glacier Deep Archive—Typically, genomics data is written to Amazon S3 using the Standard-Infrequent Access storage class before transitioning for long term storage to a lower cost storage option such as Amazon S3 Glacier Deep Archive. Even if you restore a sizeable amount of the data from archival storage to infrequent-access in a month, there is still a significant cost savings in archiving the data. Perform the storage class analysis and compute your expected cost before making any changes to your lifecycle policies in Amazon S3. You can learn more about archiving genomics data in Optimizing storage cost and data lifecycle management.
Stage genomics data on-premises first before uploading the data to Amazon S3—To keep genomics sequencers running 24/7, sequencer output files such as Binary Base Call (BCL) files are written to on-premises storage first before uploading those files to the cloud. If there is a network outage, the sequencers can continue to run for as long as you have local storage available. Verify that you have enough local storage available to meet your organization’s disaster recovery plans including Recovery Point Objective (RPO) and Recovery Time Objective (RTO). Data can always be written to external storage on-premises before being uploaded to the cloud.
Filter genomics sequencing data before uploading the data to the cloud—Consider eliminating log and thumbnail files that are not used for cloud-based analytics to minimize transfer cost, transfer time, and storage cost for a specified instrument run.
Use AWS DataSync to transfer data to Amazon S3—AWS DataSync makes it simple to transfer large amounts of data to Amazon S3 with minimal IT operational burden and optimal data transfer performance. DataSync eliminates or handles common tasks including scripting copy jobs, scheduling and monitoring transfers, validating data, and optimizing network utilization.
If file-system based access to data in Amazon S3 is required, use Amazon FSx or AWS Storage Gateway—Many research organizations use third-party tools, open-source tools, or their own tools to work with their research data. These tools often use file system-based access to data. Consider creating an Amazon Elastic Compute Cloud (Amazon EC2) instance to perform analytics on data in Amazon S3. If your applications require file-based access to Amazon S3, use Amazon FSx to provide a file-system that can be mounted on your Amazon EC2 instance. If your applications must run on-premises and require file-based access to Amazon S3, use File Gateway.
Reference architecture
Transferring your organization’s genomics data to Amazon S3 using AWS DataSync starts with setting up your sequencing instruments to write data to a common folder on your on-premises storage system. Writing first to on-premises storage enables you to take advantage of the high availability (HA) built into your storage system and stage your data for processing before transferring to the cloud.
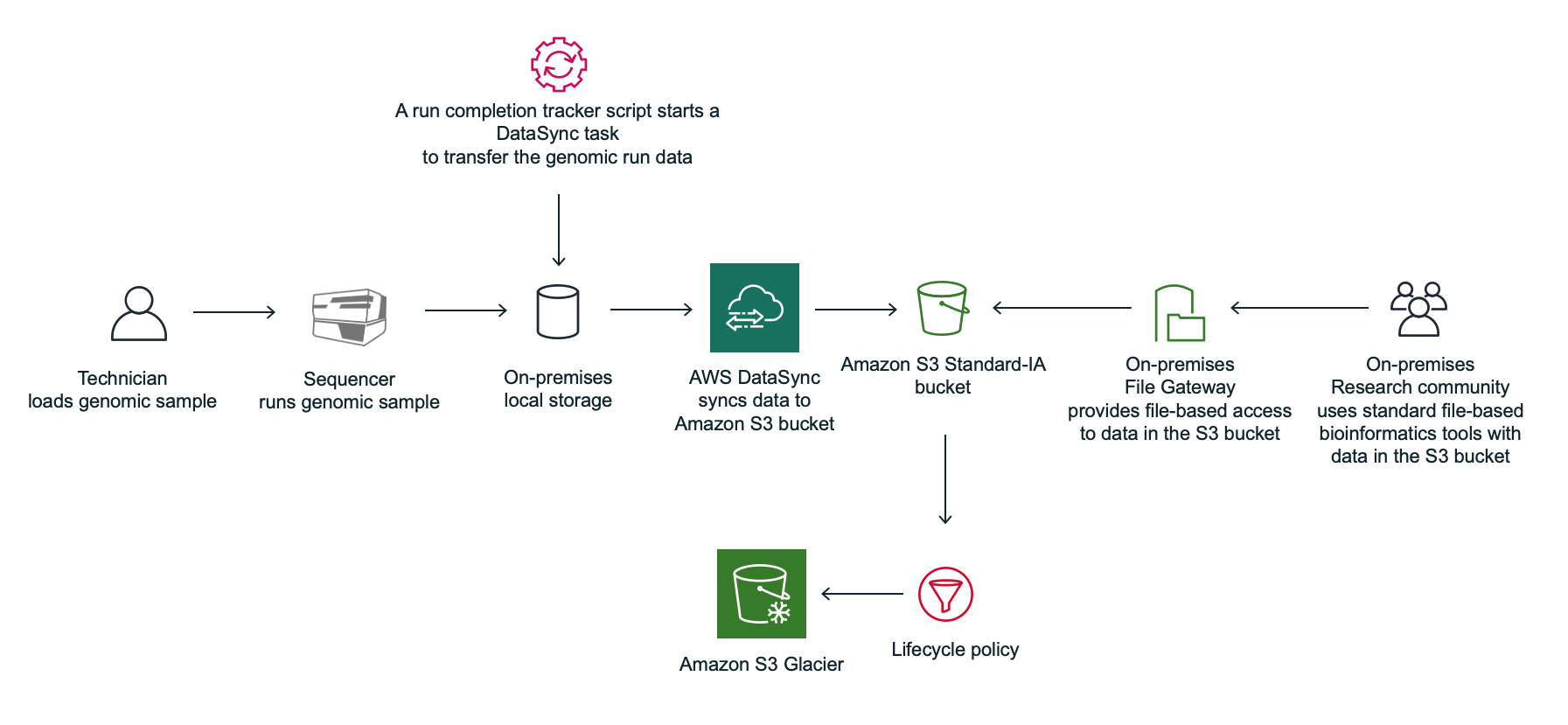
Figure 1: Process workflow using a run completion tracker script with AWS DataSync
Figure 1 shows the process workflow using a run completion tracker script with AWS DataSync:
-
A technician loads a genomic sample on a sequencer.
-
The genomic sample is sequenced and written to a landing folder that is stored in a local on-premises storage system.
-
An AWS DataSync sync task is preconfigured to sync the data from the parent directory of the landing folder on on-premises storage, to an Amazon S3 bucket.
-
A run completion tracker script starts a DataSync task run to transfer the run data to an Amazon S3 bucket. An inclusion filter can be used when running a DataSync task run, to only include a given run folder. Exclusion filters can be used to exclude files from data transfer. In addition, consider incorporating a zero-byte file as a flag when uploading the data. Technicians can then indicate when a run has passed a manual Quality Control (QC) check by placing an empty file in the data folder. Then, the run completion tracker script will only trigger a sync task if the success file is present.
-
On-premises researchers use existing bioinformatics tools with data in Amazon S3 via NFS or SMB using the File Gateway solution from AWS Storage Gateway.
In this scenario, a run completion tracker is used to monitor the staging folder and start DataSync task runs to transfer the data to Amazon S3. See Appendix E: Optimizing data transfer, cost, and performance for information about the run completion tracker pattern.
For information about getting started with DataSync, see
Getting
started with AWS DataSync
File-based access to Amazon S3
Amazon EC2 file-based access to Amazon S3 starts with setting up an FSx file system that can be mounted on your EC2 instance. Amazon FSx provides two file systems to choose from: Amazon FSx for Windows File Server for business applications and Amazon FSx for Lustre for compute-intensive workloads.
For information about setting up Amazon FSx for Windows File Server, see Create Your File System in the Amazon FSx for Windows File Server User Guide. For information about setting up Amazon FSx for Lustre User Guide, see Create Your Amazon FSx for Lustre File System in the Amazon FSx for Lustre Users Guide.
On-premises file-based access to Amazon S3 starts with setting up a file gateway on-premises to present objects stored in Amazon S3 as NFS or SMB on-premises.
AWS Storage Gateway connects an on-premises software appliance with cloud-based storage to provide seamless integration with data security features between your on-premises IT environment and the AWS storage infrastructure. You can use the service to store data in the AWS Cloud for scalable and cost-effective storage that helps maintain data security. A file gateway supports a file interface into Amazon S3 and combines a service and a virtual software appliance. By using this combination, you can store and retrieve objects in Amazon S3 using industry-standard file protocols such as NFS and SMB. For information about setting up a file gateway, see Creating a file gateway in the AWS Storage Gateway User Guide.
Note
You will incur egress charges when transferring data to on-premises from Amazon S3.
