This whitepaper is for historical reference only. Some content might be outdated and some links might not be available.
Reliability
Definition
Reliability refers to the ability of a service or system to perform its expected function when required. The reliability of a system can be measured by the level of its operational quality within a given timeframe. Contrast this to resiliency, which refers to the ability of a system to recover from infrastructure or service disruptions, dynamically and reliably.
For more details of how availability and resiliency are used to measure reliability, refer to the Reliability Pillar of the AWS Well-Architected Framework.
Key questions
Availability
Availability is the percentage of time that a workload is available for use. Common targets include 99% (3.65 days of downtime allowed per year), 99.9% (8.77 hours), and 99.99% (52.6 minutes), with a shorthand of the number of nines in the percentage ("two nines" for 99%, "three nines" for 99.9%, and so on). The availability of the networking solution between AWS and the on-premises data center may be different than overall solution or application availability.
Key questions for the availability of a networking solution include:
-
Can my AWS resources continue to operate if they cannot communicate to my on-premises resources? Vice versa?
-
Should I consider scheduled downtime for planned maintenance as included or excluded from the availability metric?
-
How will I measure the availability of the networking layer, separate from overall application health?
The Availability section of the Well-Architected Framework Reliability Pillar has suggestions and formulas for calculation availability.
Resiliency
Resiliency is the ability of a workload to recover from infrastructure or service disruptions, dynamically acquire computing resources to meet demand, and mitigate disruptions, such as misconfigurations or transient network issues. If a redundant network component (link, network devices, and so on) does not have sufficient availability to provide the expected function on its own, then it has low resiliency to failures. The consequence is a poor and degraded user experience.
Key questions for resiliency of a networking solution include:
-
How many simultaneous, discrete failures should I allow for?
-
How can I reduce single points of failure with both the connectivity solutions and my internal network?
-
What is my vulnerability to distributed denial of service (DDoS) events?
Technical solution
First, it is important to note that not every hybrid network connectivity solution
requires a high level of reliability, and that increasing levels of reliability have a
corresponding increase in cost. In some scenarios, a primary site may require reliable
(redundant and resilient) connections as the downtime has a higher impact on the business,
while regional sites, may not require the same level of reliability due to the lower impact
on the business in case of a failure event. It is recommended to refer to the AWS Direct Connect Resiliency
Recommendations
To achieve a reliable hybrid network connectivity solution in the context of resiliency, the design needs to take into consideration the following aspects:
-
Redundancy: Aim to eliminate any single point of failure in the hybrid network connectivity path, including but not limited to network connections, edge network devices, redundancy across Availability Zones, AWS Regions, and DX locations, and device power sources, fiber paths, and operating systems. For the purpose and scope of this whitepaper, redundancy focuses on the network connections, edge devices (for example, customer gateway devices), AWS DX location, and AWS Regions (for multi-Region architectures).
-
Reliable failover components: In some scenarios, a system might be functional, but not performing its functions at the required level. Such a situation is common during a single failure event where it is discovered that planned redundant components were operating non-redundantly - their networking load has no other place to go to due to usage, which results in insufficient capacity for the entire solution.
-
Failover time: Failover time is the time it takes for a secondary component to fully take over the role of the primary component. Failover time has multiple factors – how long it takes to detect the failure, how long to enable secondary connectivity, and how long to notify the remainder of the network of the change. Failure detection can be improved using Dead Peer Detection (DPD) for VPN links, and Bidirectional Forwarding Detection (BFD) for AWS Direct Connect links. The time to enable secondary connectivity can be very low (if these connections are always active), may be a short time window (if a pre-configured VPN connection needs to be enabled), or longer (if physical resources need to be moved or new resources configured). Notifying the remainder of the network usually occurs via routing protocols inside the customer’s network, each of which has different convergence times and options for configuration – the configuration of these is outside the scope of this whitepaper.
-
Traffic Engineering: Traffic engineering in the context of resilient hybrid network connectivity design aims to address how traffic should flow over multiple available connections in normal and failure scenarios. It is recommended to follow the concept of design for failure, where you need to look at how the solution will operate in different failure scenarios and whether it will be acceptable by the business or not. This section discusses some of the common traffic engineering uses case that aims to enhance the overall resiliency level of the hybrid network connectivity solution. The AWS Direct Connect section on routing and BGP talks about several traffic engineering options for influencing traffic flow (communities, BGP local preference, AS Path length). To design an effective traffic engineering solution, you need to have a good understanding of how each of the AWS networking components handle IP routing in terms of route evaluation and selection, as well as the possible mechanisms to influence the route selection. The details of this are outside the scope of this document. For more information, see Transit Gateway Route Evaluation Order, Site-to-Site VPN Route Priority, and Direct Connect Routing and BGP documentation as needed.
Note
In the VPC route table, you might reference a prefix list which has additional route selection rules. For more information about this use case, refer to route priority for prefix lists. AWS Transit Gateway route tables also support prefix lists, but once applied they get expanded to specific route entries.
Dual Site-to-Site VPN connections with more specific routes example
This scenario is based on a small on-premises site connecting to a single AWS Region over redundant VPN connections via the internet to AWS Transit Gateway. The traffic engineering design depicted in Figure 10 shows that with traffic engineering you can influence the path selection that increases the hybrid connectivity solution reliability by:
-
Resilient hybrid connectivity: Redundant VPN connections each provide the same performance capacity, support automated failover by using dynamic routing protocol (BGP), and speed up connection failure detection by using VPN dead peer detection.
-
Performance efficiency: Configuring ECMP across both VPN connections to AWS Transit Gateway helps to maximize the overall VPN connection bandwidth. Alternatively, by advertising different, more specific, routes along with the site summary route, load can be managed independency across the two VPN connections
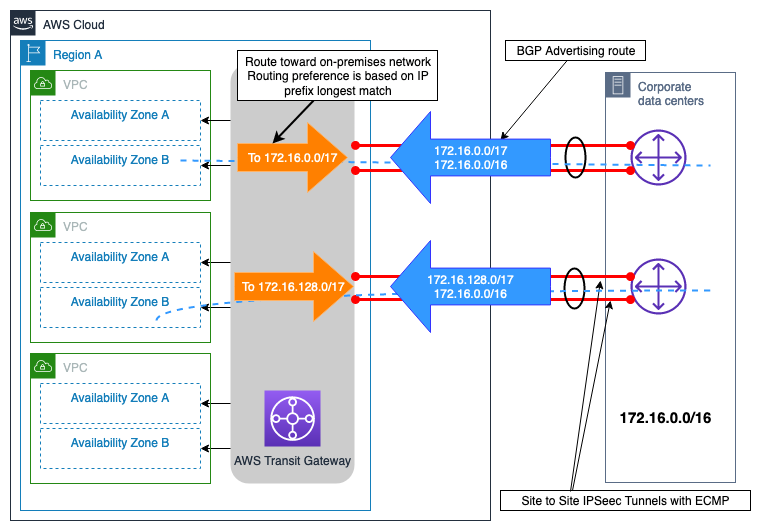
Figure 10 – Dual Site-to-Site VPN connections with more specific routes example
Dual on-premises sites with multiple DX connections example
The scenario illustrated in Figure 11 shows two on-premises data center sites located
in different geographical Regions, and connected to AWS using the Maximum Resiliency
connectivity model (described in the AWS Direct Connect Resiliency
Recommendations
By associating BGP Community attributes with the routes advertised to AWS DXGW, you can influence the egress path selection from AWS DXGW side. These community attributes control AWS’s BGP Local Preference attribute assigned to the advertised route. For more information, refer to AWS DX Routing policies and BGP communities.
To maximize the reliability of the connectivity at the AWS Region level, each pair of AWS DX connections configures ECMP so that both can be utilized at the same time for data transfer between each on-premises site and AWS.
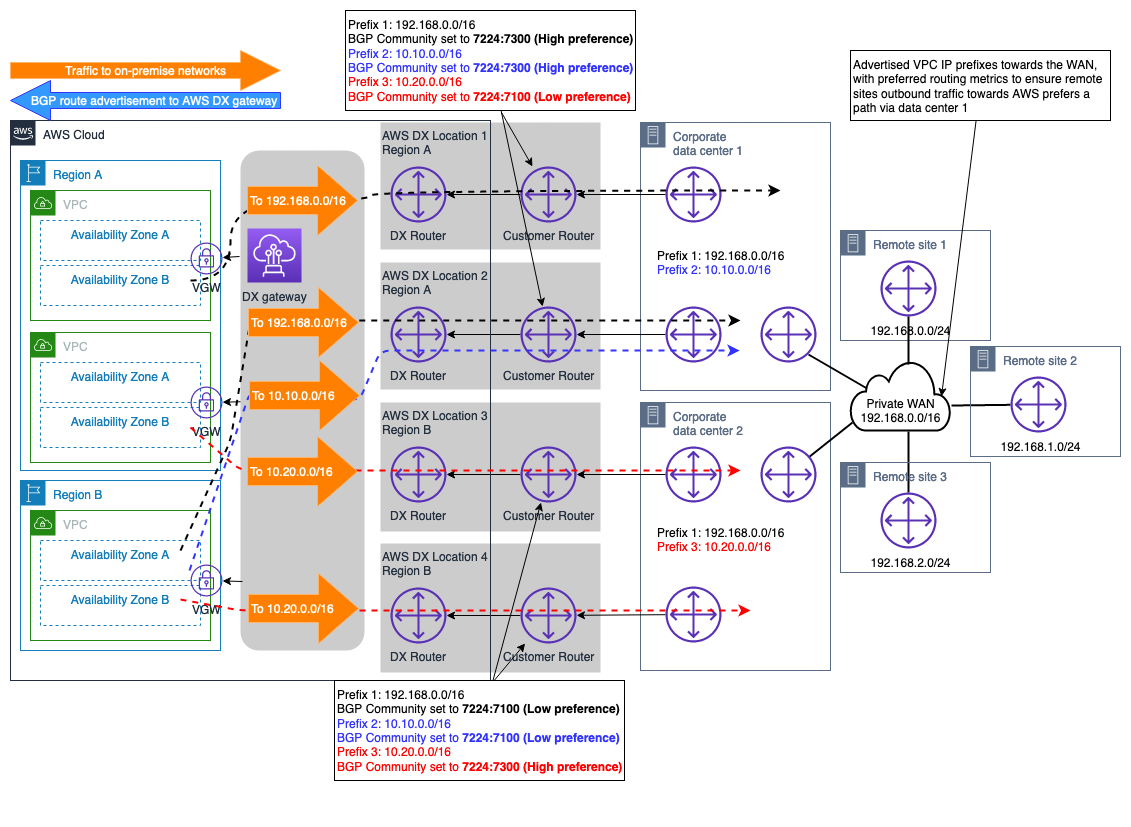
Figure 11 – Dual on-premises sites with multiple DX connections example
With this design, the traffic flows destined to the on-premises networks (with the same advertised prefix length and BGP community) will be distributed across the dual DX connections per site using ECMP. However, if ECMP is not required across the DX connection, the same concept discussed earlier and described in the Routing policies and BGP communities documentation can be used to further engineer the path selection at a DX connection level.
Note: If there are security devices in the path within the on-premises data centers, these devices need to be configured to allow traffic flows leaving over one DX link and coming from another DX link (both links utilized with ECMP) within the same data center site.
VPN connection as a backup to AWS DX connection example
VPN can be selected to provide a backup network connection to an AWS Direct Connect connection. Typically, this type of connectivity model is driven by cost, because it provides a lower level of reliability to the overall hybrid connectivity solution due to indeterministic performance over the internet, and there is no SLA that can be obtained for a connection over the public internet. It is a valid and cost-effective connectivity model, and should be used when cost is the top priority consideration and there is a limited budget, or possibly as an interim solution until a secondary DX can be provisioned. Figure 12 illustrates the design of this connectivity model. One key consideration with this design, where both the VPN and DX connections are terminating at the AWS Transit Gateway, is that the VPN connection can advertise higher number of routes compared to the ones that can be advertised over a DX connection connected to AWS Transit Gateway. This may cause a suboptimal routing situation. An option to resolve this issue is to configure route filtering at the customer gateway device (CGW) for the routes received from the VPN connection, allowing only the summary routes to be accepted.
Note: To create the summary route on the AWS Transit Gateway, you need to specify a static route to an arbitrary attachment in the AWS Transit Gateway route table so that the summary is sent along the more specific route.
From the AWS Transit Gateway routing table’s point of view, the routes for the on-premises prefix are received both from the AWS DX connection (via DXGW) and from VPN, with the same prefix length. Following the route priority logic of AWS Transit Gateway, routes received over Direct Connect have a higher preference than the ones received over Site-to-Site VPN, and thus the path over the AWS Direct Connect will be the preferred to reach the on-premises network(s).
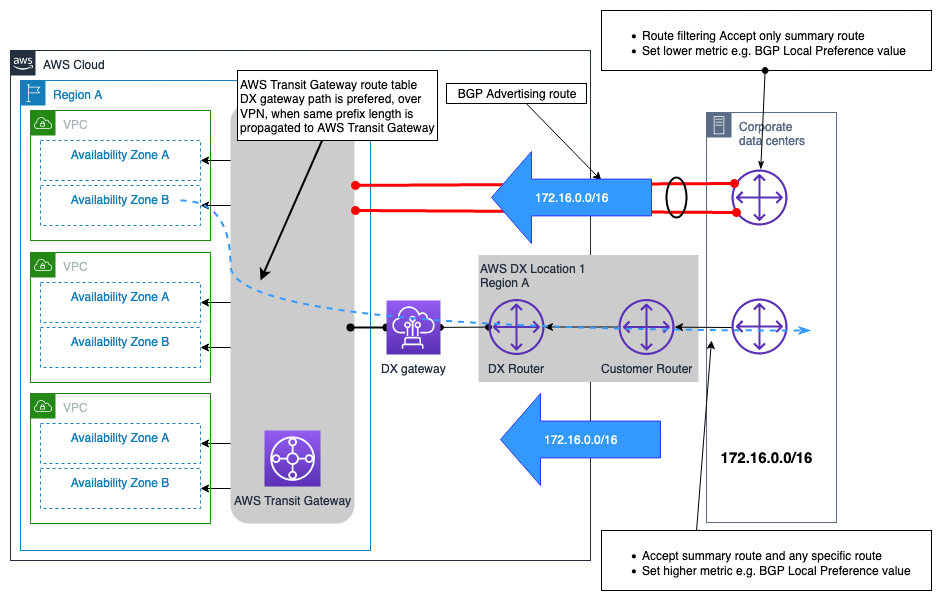
Figure 12 – VPN connection as a backup to AWS DX connection example
The following decision tree guides you through making the desired decision for achieving a resilient (which will result in a reliably) hybrid network connectivity. For more information, refer to AWS Direct Connect Resiliency Toolkit.
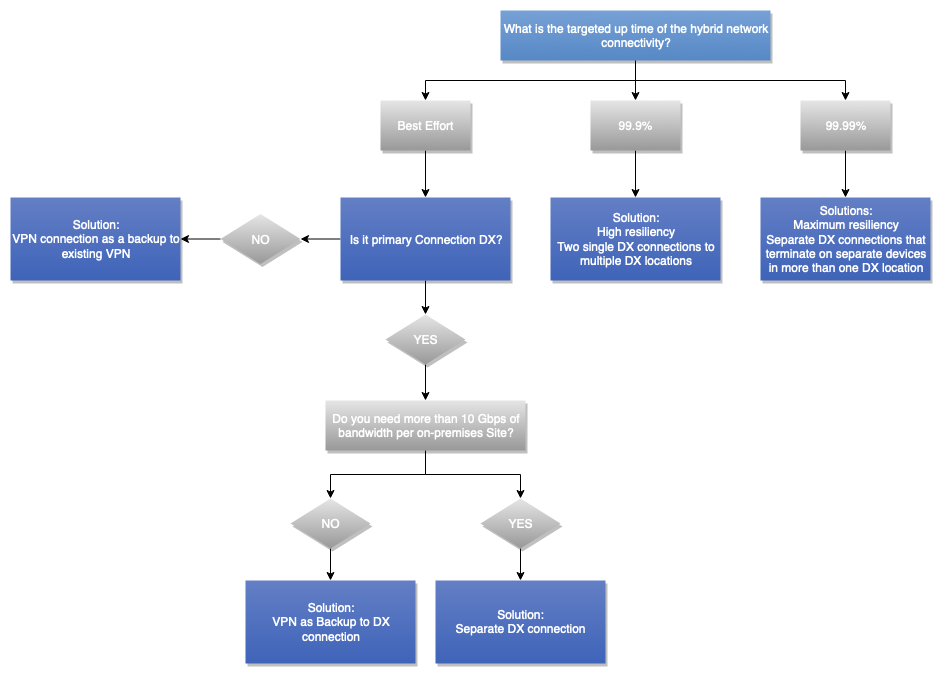
Figure 13 – Reliability decision tree
