Distributed data management
In traditional applications, all components often share a single database. In contrast, each component of a microservices-based application maintains its own data, promoting independence and decentralization. This approach, known as distributed data management, brings new challenges.
One such challenge arises from the trade-off between consistency and performance in distributed systems. It's often more practical to accept slight delays in data updates (eventual consistency) than to insist on instant updates (immediate consistency).
Sometimes, business operations require multiple microservices to work together. If one part fails, you might have to undo some completed tasks. The Saga pattern helps manage this by coordinating a series of compensating actions.
To help microservices stay in sync, a centralized data store can be used. This store, managed with tools like AWS Lambda, AWS Step Functions, and Amazon EventBridge, can assist in cleaning up and deduplicating data.
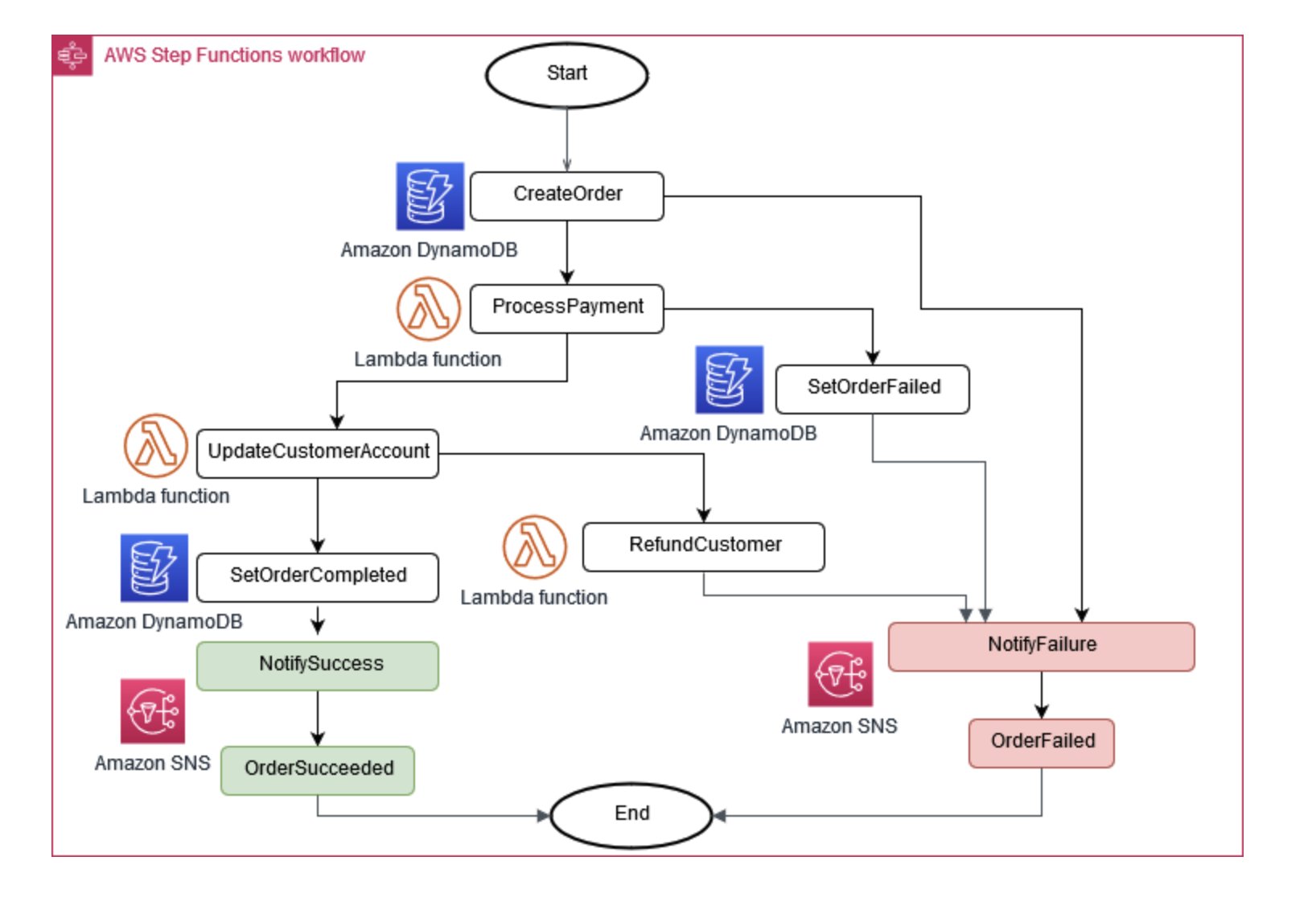
Figure 6: Saga execution coordinator
A common approach in managing changes across microservices is event sourcing. Every change in the application is recorded as an event, creating a timeline of the system's state. This approach not only helps debug and audit but also allows different parts of an application to react to the same events.
Event sourcing often works hand-in-hand with the Command Query Responsibility Segregation (CQRS) pattern, which separates data modification and data querying into different modules for better performance and security.
On AWS, you can implement these patterns using a combination of services. As you can see in Figure 7, Amazon Kinesis Data Streams can serve as your central event store, while Amazon S3 provides a durable storage for all event records. AWS Lambda, Amazon DynamoDB, and Amazon API Gateway work together to handle and process these events.
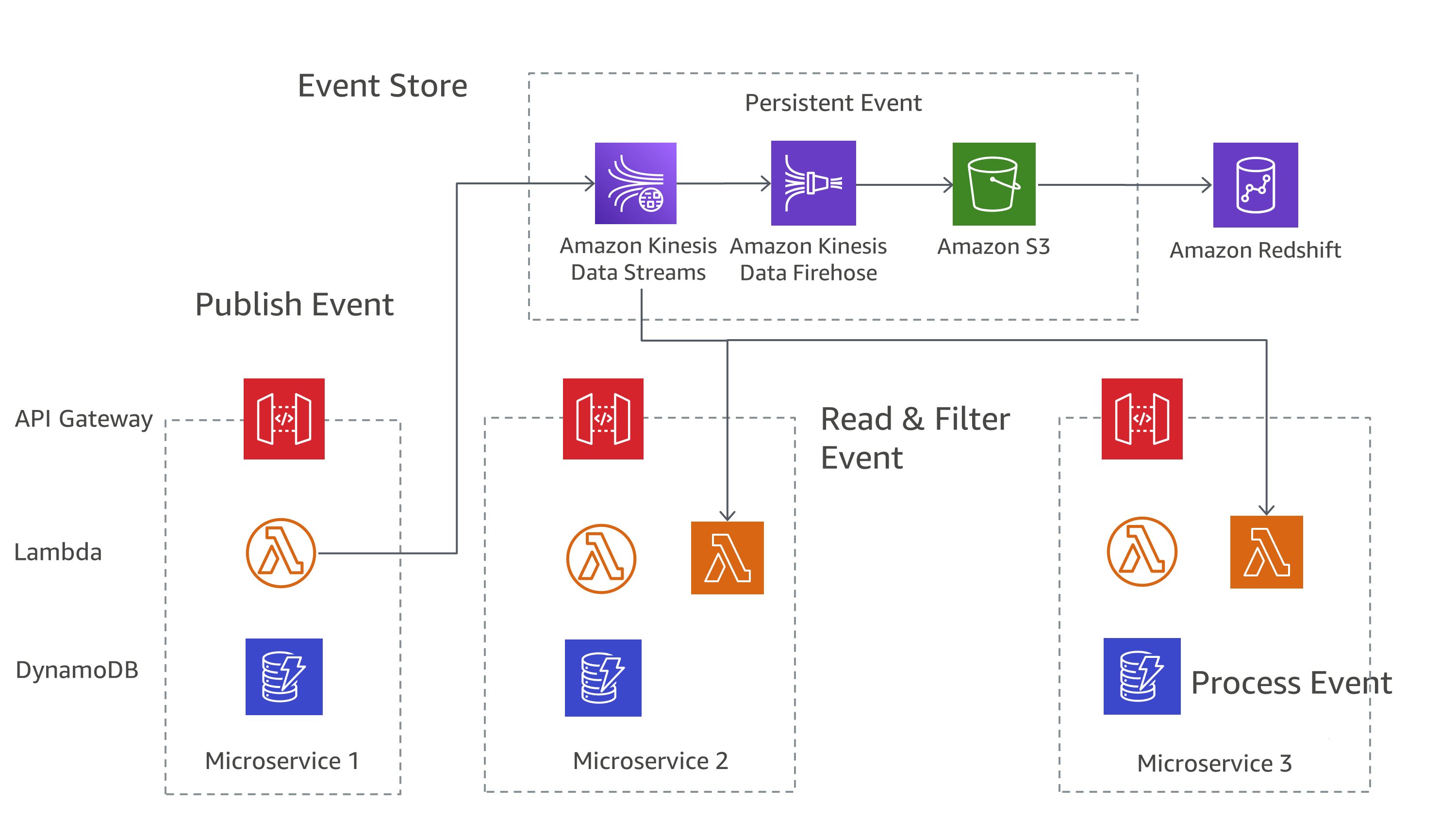
Figure 7: Event sourcing pattern on AWS
Remember, in distributed systems, events might be delivered multiple times due to retries, so it's important to design your applications to handle this.
